Semianalysis表示,在GTC2025大会上,英伟达推出的推理Token扩展、推理堆栈与Dynamo技术、共封装光学(CPO)技术等创新将显著降低AI总拥有成本,使得高效推理系统的部署成本大幅下降,并巩固了英伟达在全球AI生态系统中的领先地位。
当地时间3月18日周二, $英伟达(NVDA.US)$ CEO黄仁勋在加州圣何塞举行的英伟达AI盛会GTC 2025上发表主题演讲。美国知名半导体咨询机构Semianalysis深度解读黄仁勋GTC演讲,详细阐述英伟达在推动AI推理性能提升方面的最新进展。
市场担心的是,DeepSeek式的软件优化以及英伟达主导的硬件进步带来的巨大成本节省,可能导致对AI硬件的需求下降。然而,价格会影响需求,当AI成本降低时,AI能力的边界不断被突破,而需求随之增加。
以下为文章的核心观点:
推理Token扩展:预训练、后训练与推理时扩展定律协同作用,使得AI模型能力不断提升。
黄仁勋数学规则:包括FLOPs稀疏率、双向带宽计量,以及以封装中GPU芯片数量计算GPU数量的新规则。
GPU与系统路线图:介绍了Blackwell Ultra B300、Rubin及Rubin Ultra的关键规格与性能改进,强调了新一代产品在性能、内存和网络互连上的突破。
推出的推理堆栈与Dynamo技术:通过智能路由器、GPU规划器、改进的NCCL、NIXL和NVMe KVCache卸载管理器等新功能,极大提升了推理吞吐量和效率。
共封装光学(CPO)技术:详述了CPO在降低功耗、提高交换机基数和网络扁平化方面的优势,以及其在未来规模化网络部署中的潜力。
文章指出,这些创新将显著降低AI总拥有成本,使得高效推理系统的部署成本大幅下降,并巩固了英伟达在全球AI生态系统中的领先地位。
Semianalysis深度解读全文为AI翻译 推理 Token 爆炸 人工智能模型的进步加速迅猛,在过去六个月里,模型的提升超过了此前六个月的进展。这一趋势将持续下去,因为三条扩展定律——预训练扩展、后训练扩展和推理时扩展——正协同作用,共同推动这一进程。
今年的GTC(GPU技术大会)将聚焦于应对新的扩展范式。
来源:英伟达 Claude 3.7在软件工程领域展现了惊人的性能。Deepseek v3显示出上一代模型的成本正在急剧下降,这将进一步推动其应用普及。OpenAI的o1和o3模型证明,延长推理时间和搜索功能意味着答案质量大幅提升。正如预训练定律早期所展示的那样,后训练阶段增加计算资源没有上限。今年,Nvidia正致力于大幅提升推理成本效率,目标是实现35倍的推理成本改善,从而支持模型的训练和部署。
去年市场的口号是“买得越多,省得越多”,但今年的口号变成了“省得越多,买得越多”。Nvidia在硬件和软件方面的推理效率提升,使得模型推理和智能代理的部署成本大幅降低,从而实现成本效益的扩散效应,这正是杰文斯悖论的经典体现。
市场担心的是,DeepSeek式的软件优化以及Nvidia主导的硬件进步带来的巨大成本节省,可能导致对AI硬件的需求下降,市场可能出现Token供过于求的情况。价格会影响需求,当AI成本降低时,AI能力的边界不断被突破,而需求随之增加。如今,AI的能力受限于推理成本,随着成本下降,实际的消费量反而会增加。
对Token通缩的担忧类似于讨论光纤互联网每个数据包连接成本下降时,却忽略了网站和互联网应用对我们生活、社会和经济的最终影响。关键区别在于,带宽存在上限,而随着能力的显著提升和成本的下降,对AI的需求则可以无限增长。
Nvidia提供的数据支持了杰文斯悖论的观点。现有模型的Token数超过100万亿,而一个推理模型的Token量是其20倍,计算量则高出150倍。
来源:英伟达 测试时的计算需要数十万Token/查询,每月有数亿次查询。后训练扩展阶段,即模型“上学”,每个模型需要处理数万亿Token,同时需要数十万后训练模型。此外,具备代理能力的AI意味着多个模型将协同工作,解决越来越复杂的问题。
黄仁勋数学每年都在变化 每年,黄仁勋都会推出新的数学规则。今年的情况更为复杂,我们观察到第三条新的黄仁勋数学规则。
第一条规则是,Nvidia公布的FLOPs数据以2:4稀疏度(实际上无人使用)计,而真实性能指标是密集FLOPs——也就是说,H100在FP16下被报为989.4 TFLOPs,实际密集性能约为1979.81 TFLOPs。
第二条规则是,带宽应以双向带宽来计量。NVLink5的带宽被报为1.8TB/s,因为它的发送带宽为900GB/s,加上接收带宽900GB/s。尽管这些数据在规格书中相加,但在网络领域,标准是以单向带宽计量。
现在,第三条黄仁勋数学规则出现了:GPU数量将按照封装中GPU芯片的数量计,而非封装数量。从Rubin系列开始,这一命名方式将被采用。第一代Vera Rubin机架将被称为NVL144,即使其系统架构与GB200 NVL72类似,只不过采用了相同的Oberon机架和72个GPU封装。这种新的计数方式虽然让人费解,但我们只能在黄仁勋的世界中接受这一变化。
现在,让我们来回顾一下路线图。
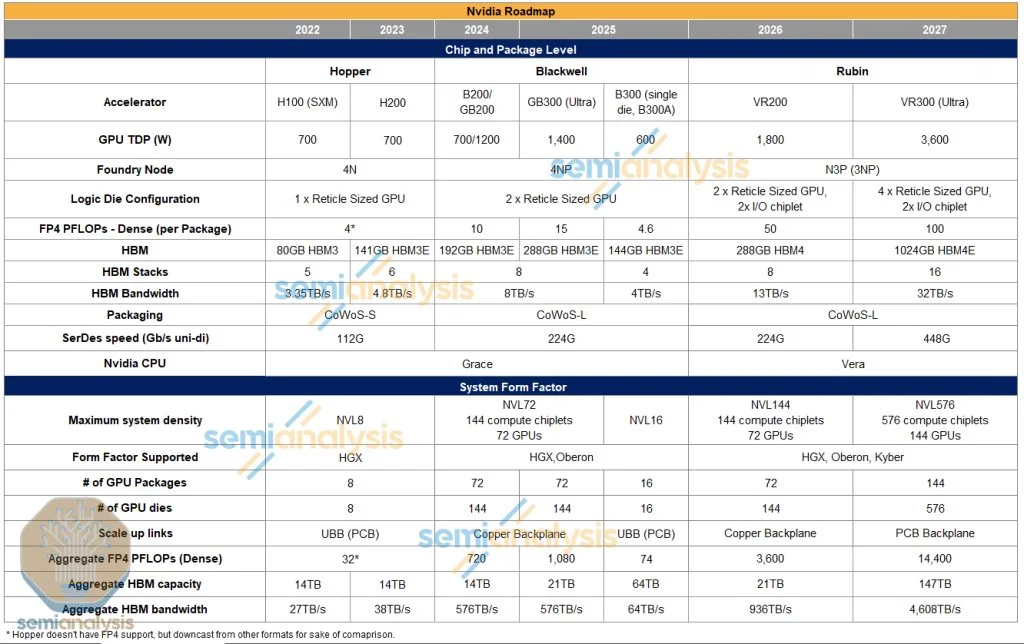
GPU和系统路线图
来源:英伟达 Blackwell Ultra B300
来源:英伟达 Blackwell Ultra 300已预览过,细节与去年圣诞节时我们分享的基本一致。主要规格如下:GB300不会以单板形式出售,而是作为B300 GPU出现在一个便携式SXM模块上,同时搭载Grace CPU,也以便携式BGA形式出现。在性能上,B300相对于B200在FP4 FLOPs密度上提升超过50%。内存容量升级到每个封装288GB(8个12-Hi HBM3E堆叠),但带宽维持在8 TB/s不变。实现这一目标的关键在于减少了许多(但不是全部)FP64运算单元,并将其替换为FP4和FP6运算单元。双精度工作负载主要用于HPC和超级计算,而非AI。虽然这让HPC群体感到失望,但Nvidia正转向强调更重要的AI市场。
B300 HGX版本现在称为B300 NVL16。这将采用之前称为“B300A”的单GPU版本,现在简称“B300”。由于单个B300没有高速D2D接口连接两个GPU芯片,可能存在更多通信间接费用。
B300 NVL16将取代B200 HGX形态,采用16个封装和GPU芯片在一块基板上。为实现这一点,每个SXM模块上放置2个单芯片封装,共8个SXM模块。尚不清楚Nvidia为何不继续采用8×双芯B300,而选择这种方式,我们怀疑这是为了从更小的CoWoS模块和封装基板中提高产量。值得注意的是,该封装技术将采用CoWoS-L而非CoWoS-S,这一决策意义重大。CoWoS-S的成熟度和产能是单芯B300A的原因,而这一转变表明CoWoS-L已迅速成熟,其产率相比起初的低迷已有所稳定。
这16个GPU将通过NVLink协议通信,与B200 HGX类似,两块NVSwitch 5.0 ASIC将位于SXM模块的两个阵列之间。
新细节是,与以往的HGX不同,B300 NVL16将不再采用$Astera Labs(ALAB.US)$ 的重定时器。不过,一些超大规模云服务提供商可能会选择加入PCIe交换机。我们曾在今年早些时候向Core Research订阅者透露过这一消息。
另一个重要细节是,B300将引入CX-8 NIC,该网卡提供4个200G的通道,总吞吐量达到800G,为InfiniBand提供新一代网络速度,这比现有的CX-7 NIC提升一倍。
Rubin技术规格
来源:英伟达 来源:Semianalysis Rubin将采用$台积电(TSM.US)$ 3nm工艺,拥有两个reticle-size计算芯片,左右各配备两个I/O Tile,内置所有NVLink、PCIe以及NVLink C2C IP,以释放主芯片上更多用于计算的空间。
Rubin提供令人难以置信的50 PFLOPs密集FP4计算性能,比B300的代际性能增长超过三倍。Nvidia如何实现这一点?他们通过以下几个关键向量进行扩展:
1、如上所述,I/O芯片释放的面积可能增加20%-30%,可用于更多的流处理器和张量核。
2、Rubin将采用3nm工艺,可能使用定制的Nvidia 3NP或标准N3P。从3NP到4NP的转变大幅提升了逻辑密度,但SRAM几乎没有缩减。
3、Rubin将具有更高的TDP——我们估计约为1800W,这甚至可能推动更高的时钟频率。
4、结构上,Nvidia逐代扩大的张量核systolic array将进一步扩大:从Hopper的32×32到Blackwell的64×64,Rubin可能扩展至128×128。更大的systolic array提供了更好的数据复用和较低的控制复杂度,同时在面积和功耗上更高效。尽管编程难度增加,但Nvidia凭借内置冗余和修复机制实现了极高的参数良率,这使得即使个别计算单元失效,整体性能仍能得到保障。这与TPU不同,后者的超大张量核没有相同的容错能力。
来源:Semianalysis Rubin将继续使用Oberon机架架构,如同GB200/300 NVL72,并配备Vera CPU——Grace的3nm继任者。需要注意的是,Vera CPU将采用Nvidia全定制核心,而Grace则严重依赖Arm的Neoverse CSS核心。Nvidia还开发了一套定制互连系统,使得单个CPU核心能访问更多内存带宽,这一点是AMD和Intel难以匹敌的。
这就是新命名方式的由来。新机架将命名为VR200 NVL144,尽管系统架构与之前的GB200 NVL72类似,但由于每个封装含有2个计算芯片,总计144个计算芯片(72个封装×2个计算芯片/封装),Nvidia正在改变我们统计GPU数量的方式!
至于AMD,其市场营销团队需要注意,AMD在宣称MI300X家族可以扩展到64个GPU的规模上存在遗漏(每系统8个封装×每封装8个XCD芯片组),这是一个关键的市场机遇。
HBM与互连
Nvidia的HBM容量将一代比一代保持在288GB,但升级为HBM4:8个堆叠,每个12-Hi,层密度保持24GB/层。HBM4的应用使得总带宽得以提升,13TB/s的总带宽主要得益于总线宽度翻倍至2048位,针脚速度为6.5Gbps,符合JEDEC标准。
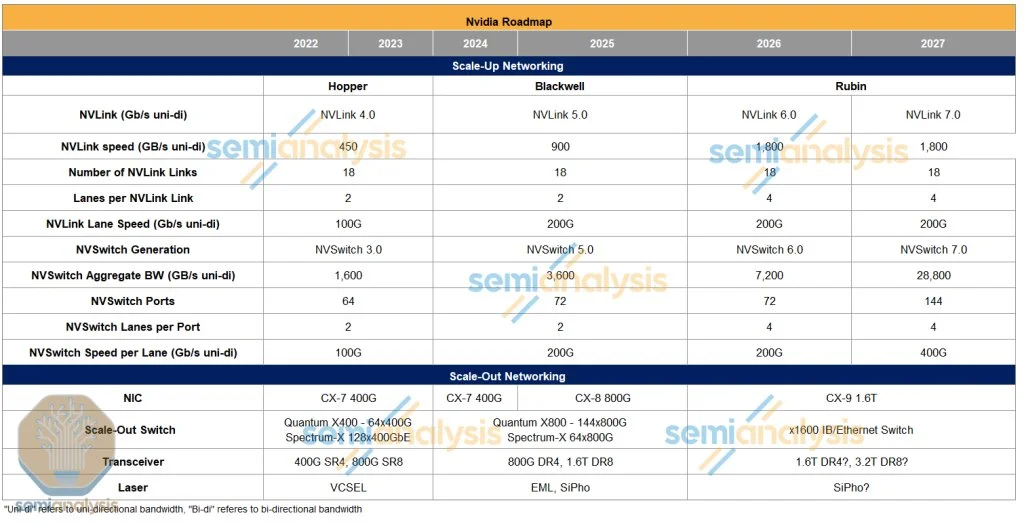
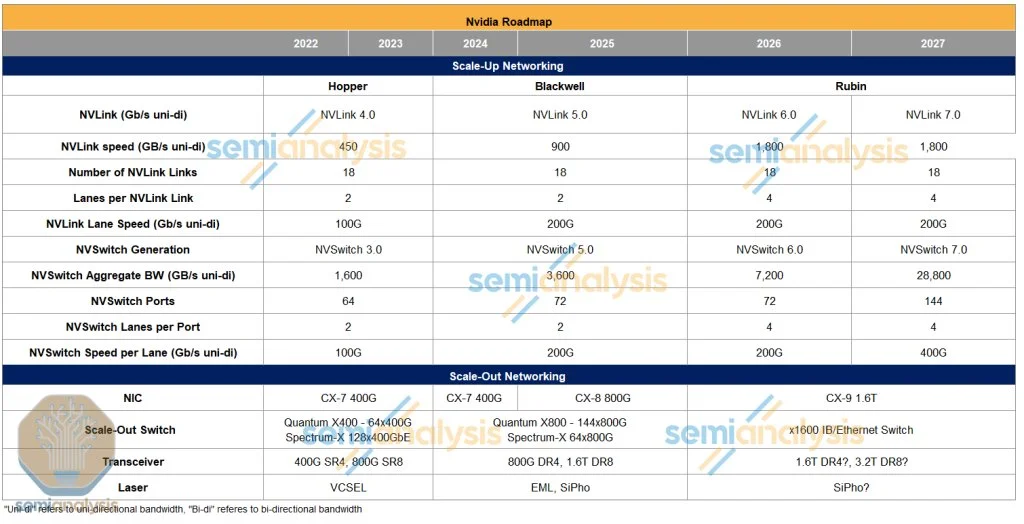
来源:Semianalysis NVLink第六代的速度翻倍至3.6TB/s(双向),这来自于通道数量翻倍,Nvidia仍采用224G SerDes。
回到Oberon机架,背板依然采用铜背板,但我们认为其电缆数量也相应增加,以适应每个GPU通道数量的翻倍。
NVSwitch方面,新一代NVSwitch ASIC也将通过通道数量翻倍来实现总带宽的翻倍,这将进一步提高交换机的性能。
Rubin Ultra规格
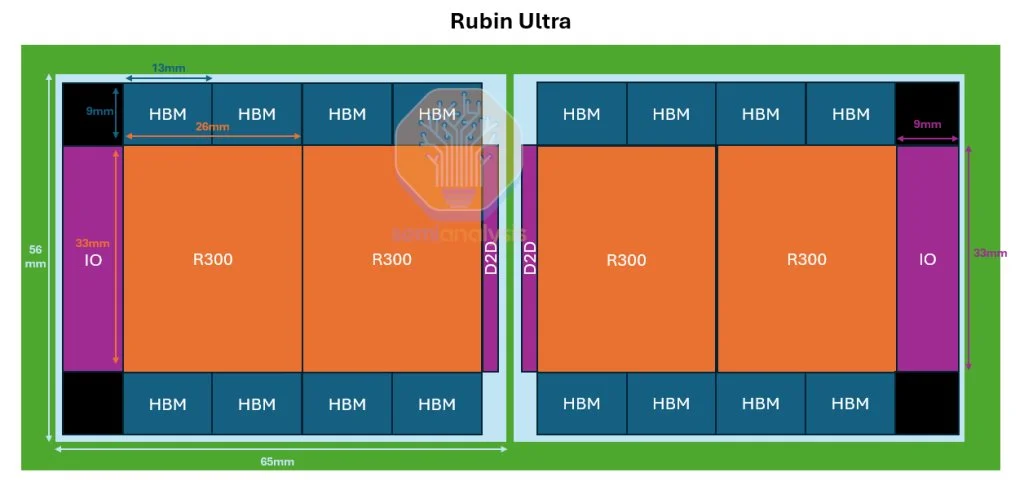
来源:英伟达 Rubin Ultra是性能大幅提升的阶段。Nvidia将直接在一个封装中使用16个HBM堆叠,从8个增加至16个。整个机架将由4个掩模尺寸GPU组成,中间配有2个I/O芯片。计算区域翻倍,计算性能也翻倍至100 PFLOPs密集FP4性能。HBM容量增加到1024GB,超过普通Rubin的3.5倍。采用双堆叠设计,同时密度和层数也提高。为达到1TB内存,封装中将有16个HBM4E堆叠,每个堆叠有16层32Gb DRAM核心芯片。
我们认为,这种封装将拆分为两个互连器放置在基板上,以避免使用一个超大互连器(几乎8倍于掩模大小)。中间的2个GPU芯片将通过薄型I/O芯片进行互联,通信通过基板实现。这需要一个超大ABF基板,其尺寸超出当前JEDEC封装尺寸限制(宽度和高度均为120mm)。
该系统拥有总计365TB的高速存储,每个Vera CPU拥有1.2TB LPDDR,共计86TB(72个CPU),这为每个GPU封装留下约2TB的LPDDR,作为额外的二级内存。这是对定制HBM基芯功能的实现。LPDDR内存控制器集成在基芯上,为额外的二级内存服务,该内存位于板上LPCAMM模块上,与Vera CPU所带的二级内存协同工作。
来源:Semianalysis 这也是我们将看到Kyber机架架构推出的时候。
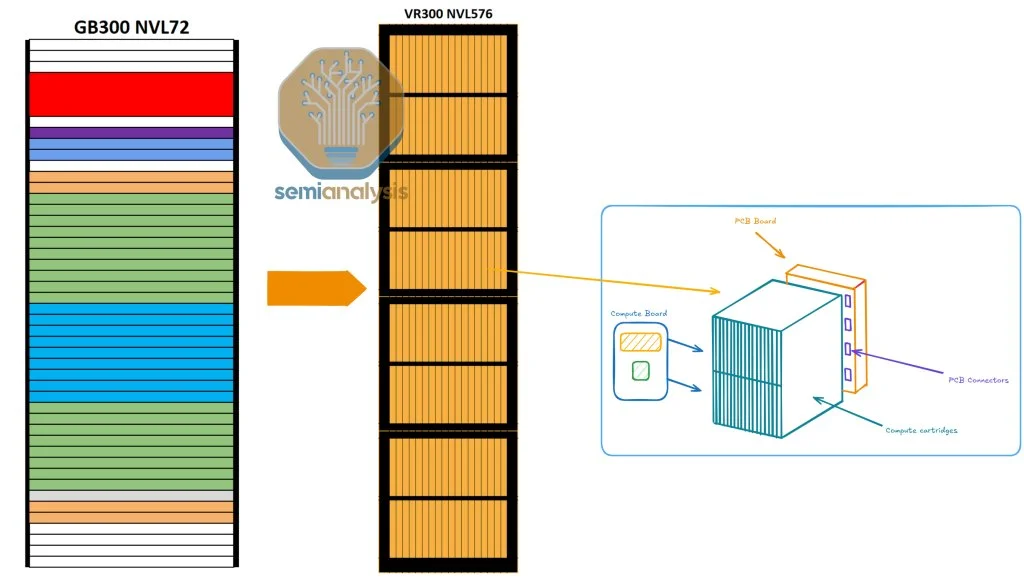
Kyber机架架构
Kyber机架架构的关键新特性在于,Nvidia通过将机架旋转90度来提高密度。对于NVL576(144个GPU封装)的配置,这是大规模扩展网络规模的又一重大提升。
来源:英伟达 让我们来看一下Oberon机架与Kyber机架的关键区别:
来源:Semianalysis ·计算托盘旋转90度,形成类似于卡盒的形态,从而实现更高的机架密度。
·每个机架由4个筒仓组成,每个筒仓包括两层18个计算卡。
对于NVL576,每个计算卡中包含一个R300 GPU和一个Vera CPU。
每个筒仓总共有36个R300 GPU和36个Vera CPU。
这使得NVLink的世界规模达到144个GPU(576个芯片)。
·PCB背板取代了铜线背板,作为GPU与NVSwitch之间扩展链接的关键部件。
这一转变主要是由于在较小的占地面积内难以布置电缆。
来源:英伟达 有迹象表明,供应链中出现了VR300 NVL1,152(288个GPU封装)的Kyber机架变体。如果按照GTC主题演讲中提到的晶圆数计算,您将看到红色标注的288个GPU封装。我们认为这可能是未来的一款SKU,其机架密度和NVLink世界规模将从展示的NVL576(144个封装)翻倍至NVL1,152(288个封装)。
此外,还有一款全新NVSwitch第七代,这一点值得注意。这是第一次引入中平台的NVSwitch,使得交换机总带宽和基数都有所提升,可扩展到单一域内576个GPU芯片(144个封装),不过拓扑结构可能不再是全互联的单级多平面结构,而可能转为具有过度订阅的两级多平面网络拓扑,或甚至采用非Clos拓扑。
Blackwell Ultra改进的指数级硬件单元 各种注意力机制(如flash-attention、MLA、MQA和GQA)都需要矩阵乘法(GEMM)和SOFTMAX函数(行归约和元素级指数运算)。
在GPU中,GEMM运算主要由张量核执行。虽然每代张量核性能不断提升,但负责softmax计算的多功能单元(MUFU)提升幅度较小。
在bf16(bfloat16)Hopper中,计算注意力层的softmax需要占用GEMM周期的50%。这要求内核工程师通过重叠计算来“隐藏”softmax的延迟,这使得编写内核变得异常困难。
来源: Tri Dao @ CUDA Mode Hackathon 2024 在FP8(浮点数8位)的Hopper中,注意力层的softmax计算所需周期与GEMM相同。如果没有任何重叠,注意力层的计算时间将翻倍,大约需要1536个周期来计算矩阵乘法,再加1536个周期来计算softmax。这就是重叠技术提高吞吐量的关键所在。由于softmax和GEMM所需周期相同,工程师需要设计出完美重叠的内核,但现实中很难达到这一理想状态,根据阿姆达尔定律,完美重叠难以实现,硬件性能因此受损。
在Hopper GPU世界中,这一挑战尤为明显,第一代Blackwell也面临类似问题。Nvidia通过Blackwell Ultra解决了这一问题,在重新设计SM(流多处理器)并增加新的指令后,使MUFU计算softmax部分的速度提升了2.5倍。这将减轻对完美重叠计算的依赖,使得CUDA开发者在编写注意力内核时有更大的容错空间。
来源: Tri Dao @ CUDA Mode Hackathon 2024 这正是Nvidia新的推理堆栈和Dynamo技术大显身手的地方。
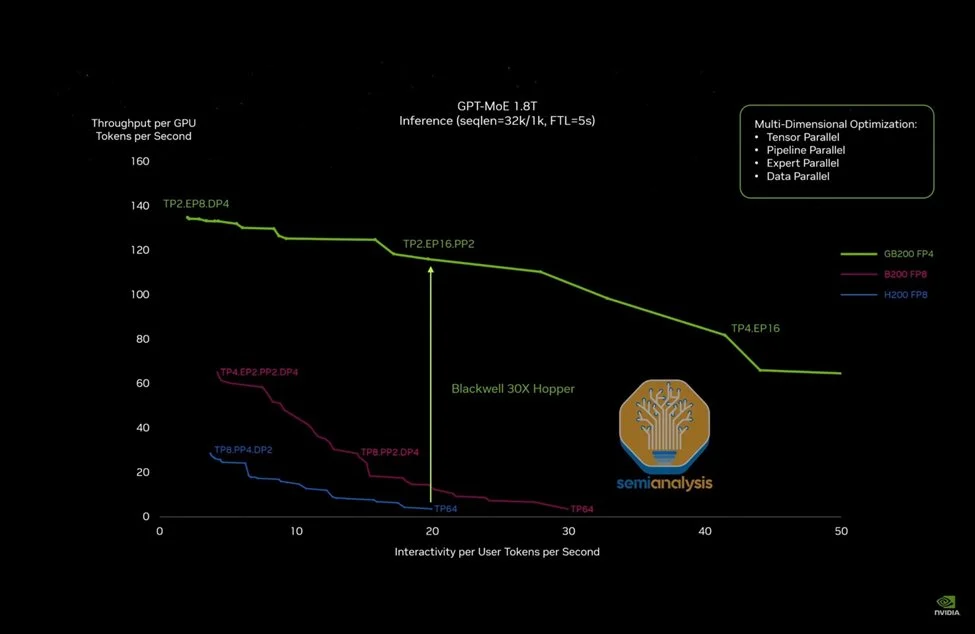
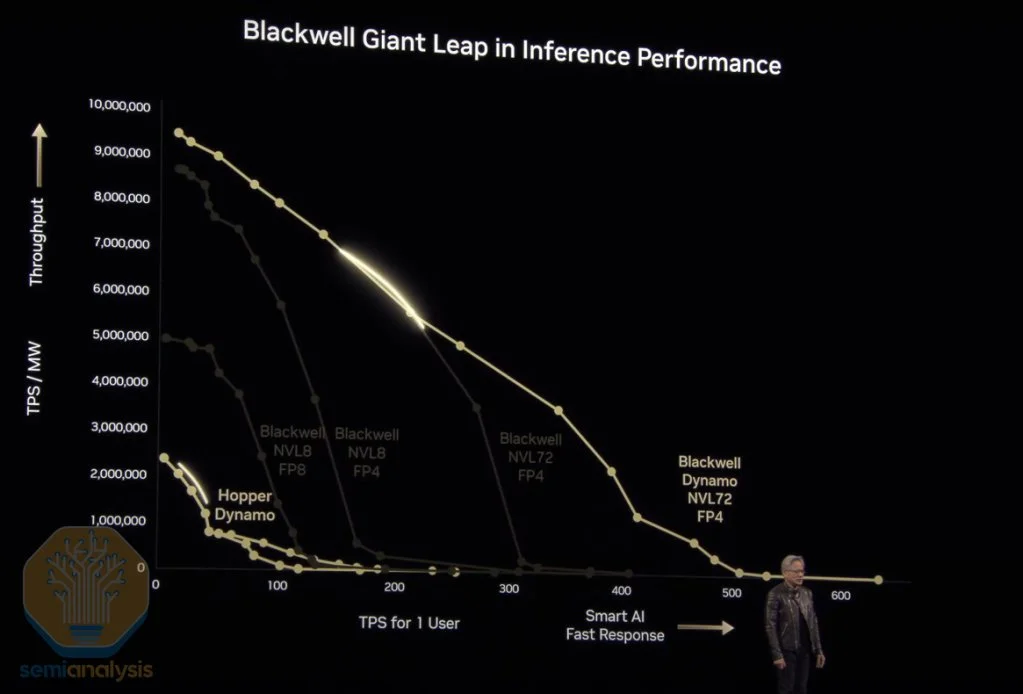
推理堆栈与Dynamo 在去年的GTC上,Nvidia讨论了GB200 NVL72的大规模GPU扩展如何使推理吞吐量较H200在FP8下提升15倍。
来源:英伟达 Nvidia并未放缓步伐,而是在硬件和软件领域同时加速推理吞吐量的提升。
Blackwell Ultra GB300 NVL72较GB200 NVL72在FP4密集性能上提升50%,同时HBM容量也提升50%,这两项均将提高推理吞吐量。路线图中还包括Rubin系列中网络速度的多项升级,这也将显著提升推理性能。
下一步硬件在推理吞吐量方面的跃升将来自Rubin Ultra中扩展的网络规模,其规模将从Rubin中的144个GPU芯片(或封装)扩展到576个GPU芯片,这只是硬件改进的一部分。
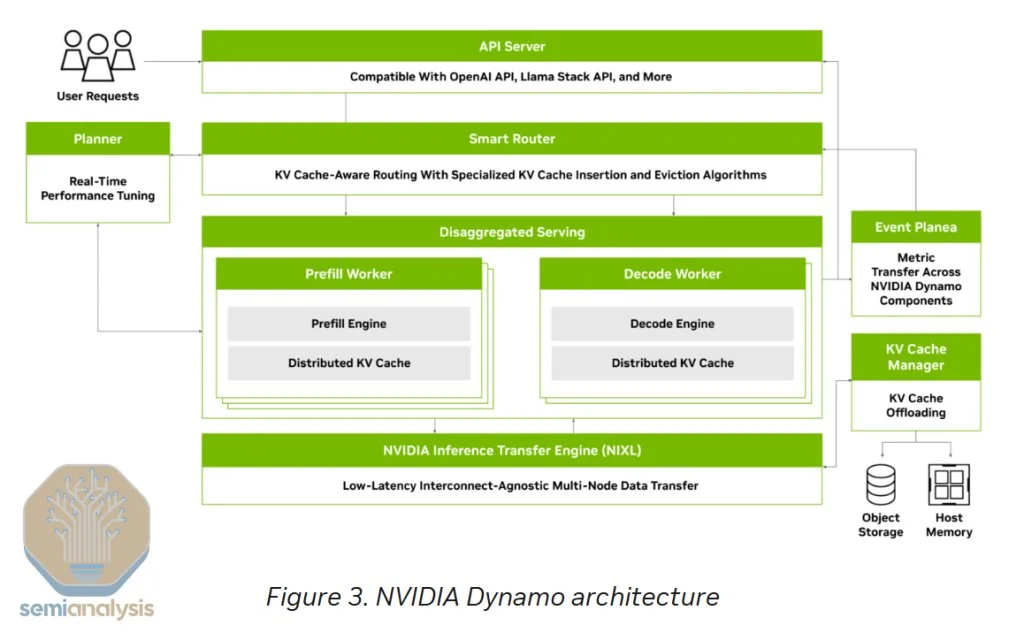
在软件方面,Nvidia推出了Nvidia Dynamo——一个开放的AI引擎堆栈,旨在简化推理部署和扩展。Dynamo有潜力颠覆现有的VLLM和SGLang,提供更多功能且性能更高。结合硬件创新,Dynamo将使推理吞吐量和交互性之间的曲线进一步右移,尤其是为需要更高交互性的应用场景提供改进。
来源:英伟达 Dynamo引入了多个关键新功能:
·Smart Router:智能路由器能在多GPU推理部署中合理分配每个Token,确保在预加载和解码阶段均衡负载,避免瓶颈。
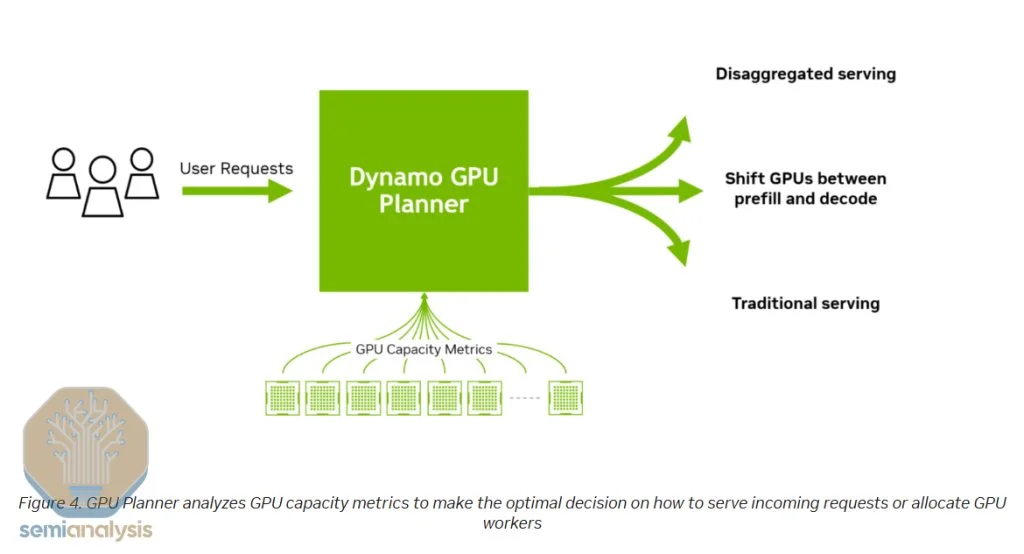
·GPU Planner:GPU规划器可以自动调整预加载和解码节点,依据日内需求波动动态增加或重新分配GPU资源,进一步实现负载均衡。
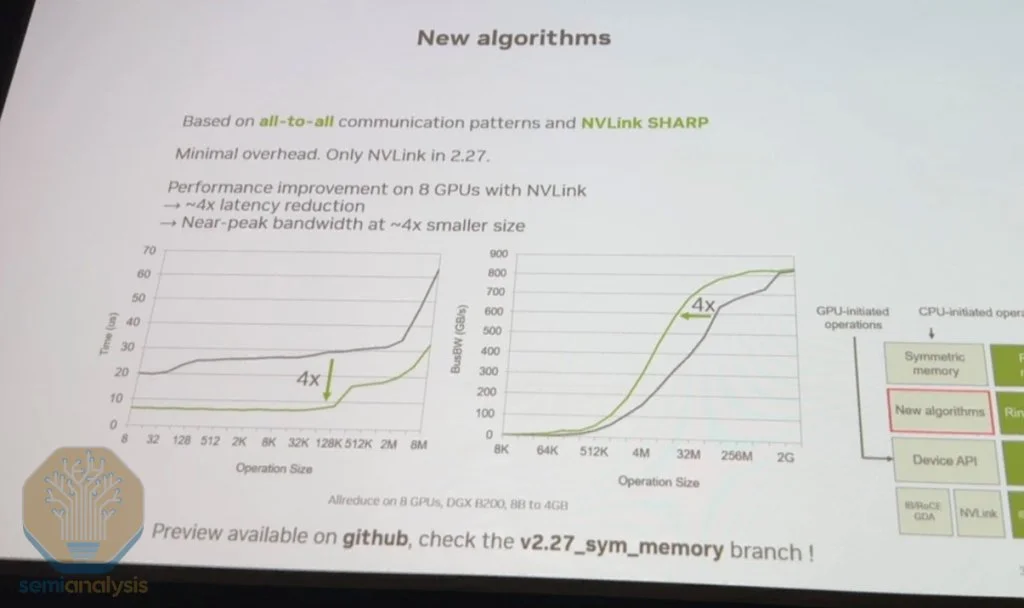
·改进的NCCL Collective for Inference:Nvidia Collective Communications Library(NCCL)的新算法使得小消息传输延迟降低4倍,从而显著提高推理吞吐量。
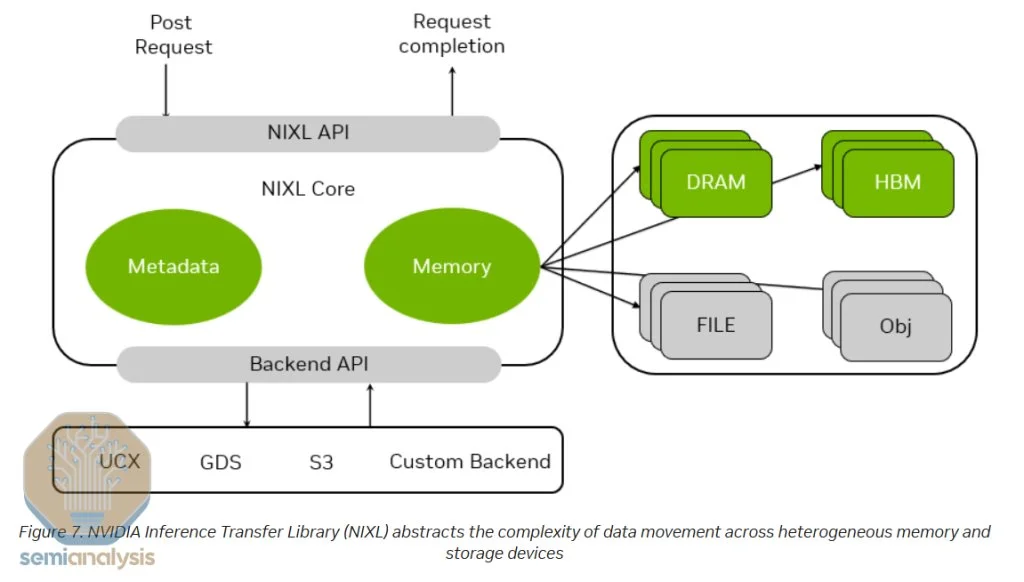
·NIXL(NVIDIA Inference Transfer Engine):NIXL利用InfiniBand GPU-Async Initialized(IBGDA)技术,将控制流和数据流均直接从GPU传输到NIC,无需通过CPU,极大降低延迟。
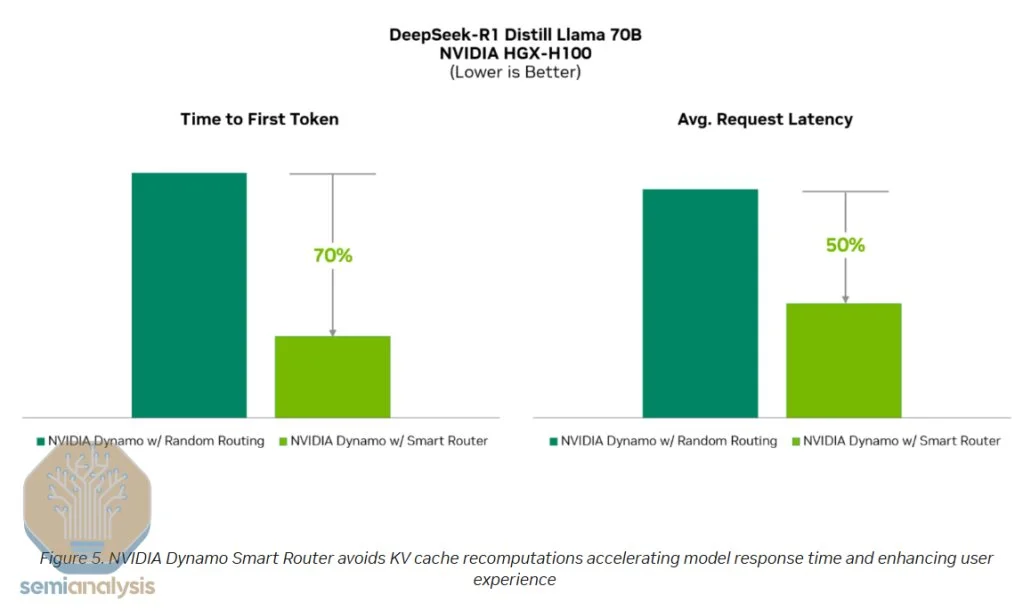
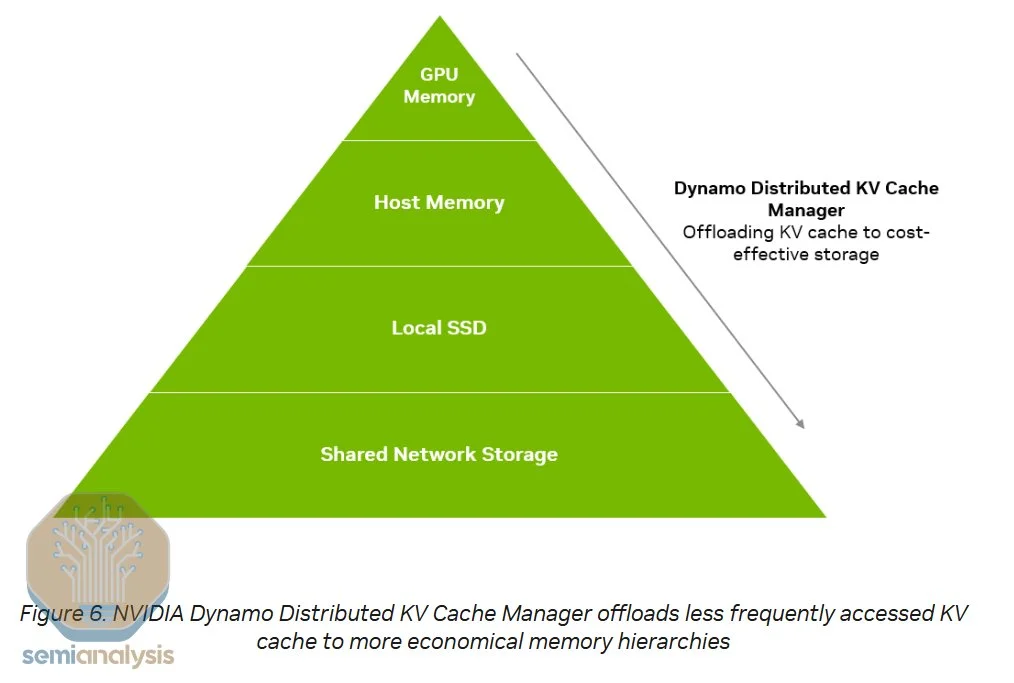
·NVMe KV-Cache Offload Manager:该模块允许将KV Cache离线存储到NVMe设备,避免在多轮对话中重复计算,从而加速响应并释放预加载节点容量。
智能路由器
智能路由器能在多GPU推理部署中智能地将每个token同时路由到预加载(prefill)和解码(decode)GPU上。在预加载阶段,确保传入的tokens均匀分配到各个负责预加载的GPU上,从而避免某个expet参数模块因流量过载而形成瓶颈。
同样,在解码阶段,确保序列长度和请求在负责解码的各GPU之间得到合理分配和平衡也十分关键。对于那些处理量较大的expet参数模块,GPU规划器(GPU Planner)还可将其复制,以进一步维持负载平衡。
此外,智能路由器还能在所有模型副本之间实现负载均衡,这一点是vLLM等许多推理引擎所不具备的优势。
来源:英伟达 GPU规划器 GPU规划器是预加载和解码节点的自动扩展器,可根据一天内需求的自然波动启动额外节点。它能够在基于专家模型(MoE)的多个expet参数模块之间实施一定程度的负载均衡,无论是在预加载还是在解码阶段。GPU规划器会启动额外的GPU,为高负载expet参数模块提供更多计算能力,并可根据需要在预加载和解码节点之间动态重新分配资源,从而最大化资源利用率。
此外,它还支持调整用于解码和预加载的GPU比例——这对像Deep Research这样的应用尤为重要,因为这类应用需要预加载大量上下文信息,而实际生成的内容却相对较少。
来源:英伟达 改进的NCCL集体通信
Nvidia Collective Communications Library (NCCL)中新增的一组低延迟通信算法,可以将小消息传输的延迟降低4倍,从而大幅提升整体推理吞吐量。
在今年的GTC上,Sylvain在演讲中详细介绍了这些改进,重点阐述了单次和双次全归约(all-reduce)算法如何实现这一效果。
由于AMD的RCCL库实际上是Nvidia NCCL的复制版本,Sylvain对NCCL的重构将持续扩大CUDA的护城河,同时迫使AMD在同步Nvidia重大重构成果上耗费大量工程资源,而Nvidia则可以利用这些时间继续推进集体通信软件堆栈和算法的前沿发展。
来源:英伟达 NIXL —— Nvidia推理传输引擎
为了在预加载节点和解码节点之间实现数据传输,需要低延迟、高带宽的通信传输库。NIXL采用InfiniBand GPU-Async Initialized (IBGDA)技术。
目前在NCCL中,控制流经过CPU代理线程,而数据流则直接传输到网卡,无需经过CPU缓冲。而使用IBGDA后,控制流与数据流均可直接从GPU传输到网卡,无需CPU中转,从而大幅降低延迟。
此外,NIXL还能将在CXL、本地NVMe、远程NVMe、CPU内存、远程GPU内存及GPU之间传输数据的复杂性进行抽象,简化数据移动流程。
来源:英伟达 NVMe KVCache卸载管理器
KVCache卸载管理器通过将之前用户对话中生成的KV缓存存储到NVMe设备中,而非直接丢弃,来提高预加载阶段整体效率。
来源:英伟达 在用户与大型语言模型(LLM)进行多轮对话时,模型需要将前期问答作为输入token纳入考量。传统上,推理系统会丢弃用于生成这些问答的KV缓存,导致必须重新计算,从而重复同样的计算过程。
而采用NVMe KVCache卸载后,当用户暂时离开时,KV缓存会被卸载到NVMe存储中;当用户重新提问时,系统可以迅速从NVMe中检索KV缓存,免去了重新计算的开销。
这不仅释放了预加载节点的计算能力,使其能够处理更多的输入流量,同时还改善了用户体验,显著缩短了从开始对话到接收到第一个token的时间。
来源:英伟达 根据DeepSeek在开源周第6天的GitHub说明,研究人员披露其磁盘KV缓存命中率为56.3%,表明在多轮对话中典型的KV缓存命中率可达到50%-60%,这对预加载部署效率提升起到了显著作用。虽然在对话较短时,重新计算可能比加载更便宜,但总体来看,采用NVMe存储方案所带来的节约成本是巨大的。
追踪DeepSeek开源周的朋友对上述技术应该并不陌生。这些技术堪称快速了解Nvidia Dynamo创新成果的绝佳途径,而Nvidia也将推出更多关于Dynamo的文档。
所有这些新特性共同实现了推理性能的大幅加速。Nvidia甚至讨论过,当Dynamo部署在现有的H100节点上时,性能如何进一步提升。基本上,Dynamo使得DeepSeek的创新成果普惠整个社区,不仅限于那些拥有顶尖推理部署工程能力的AI实验室,所有用户都能部署高效的推理系统。
最后,由于Dynamo能够广泛处理分散推理和专家并行性,它特别有利于单个复制和更高交互性部署。当然,要充分发挥Dynamo的能力,必须有大量节点作为前提,从而实现显著的性能改进。
来源:英伟达 这些技术共同带来了推理性能的巨大提升。Nvidia提到,当Dynamo部署在现有的H100节点上时,也能实现显著的性能改进。换句话说,Dynamo使得整个开源推理技术的最佳成果惠及所有用户,不仅仅是那些拥有深厚工程背景的顶级AI实验室。这让更多的企业能够部署高效的推理系统,降低整体成本,提高应用的交互性和扩展性。
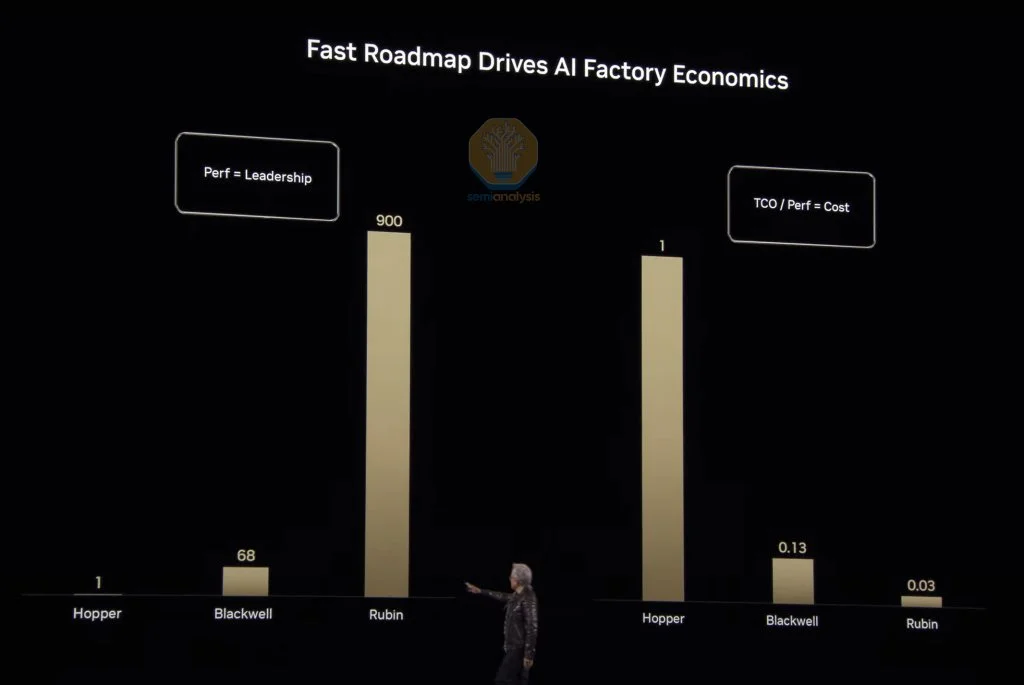
AI总拥有成本下降 在讨论完Blackwell之后,黄仁勋强调,这些创新已使他成为“首席收入破坏者”。他指出,Blackwell相比Hopper的性能提升达68倍,使得成本下降了87%。而Rubin预计将实现比Hopper高900倍的性能提升,成本降低99.97%。
显然,Nvidia正以不懈的步伐推动技术进步——正如黄仁勋所言:“当Blackwell开始大规模出货时,你甚至不可能把Hopper免费送出。”
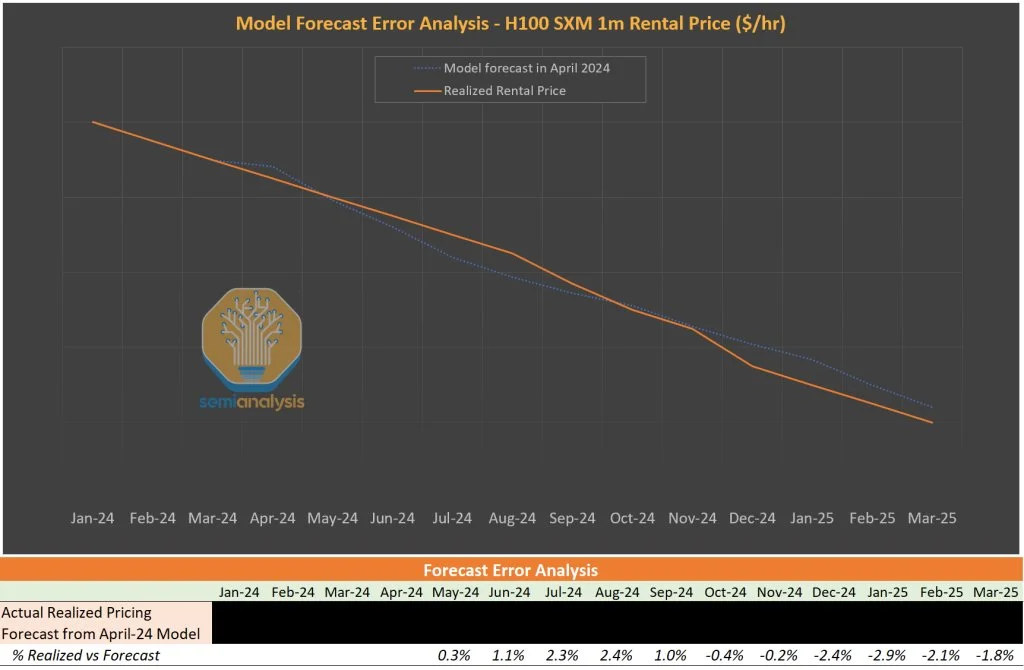
来源:英伟达 我们早在去年10月的《AI Neocloud行动指南》中就强调,产品周期早期部署计算能力的重要性,而这正是驱动H100租赁价格从2024年中期开始加速下跌的原因。我们一直呼吁整个生态系统优先部署下一代系统,如B200和GB200 NVL72,而不是继续采购H100或H200。
我们的AI云总拥有成本(TCO)模型已经向客户展示了各代芯片生产率的跃升,以及这种跃升如何推动AI Neocloud租赁价格的变化,进而影响芯片所有者的净现值。截至目前,我们在2024年初发布的H100租赁价格预测模型准确率达到98%。
来源: AI TCO Model CPO(共封装光学)技术 来源:英伟达 在主题演讲中,Nvidia宣布了首个共封装光学(CPO)解决方案,将其部署于扩展交换机中。通过CPO,收发器被外部激光源(ELS)取代,与直接放置在芯片硅片旁边的光学引擎(OE)协同工作,实现数据通信。现在,光纤直接插入交换机上的端口,将信号路由至光学引擎,而不再依赖传统收发器端口。
来源:英伟达 CPO的主要优势在于显著降低功耗。由于交换机上不再需要数字信号处理器(DSP),而且可以使用功耗更低的激光光源,因此实现了显著的功耗节省。使用线性可插光模块(LPO)也能取得类似效果,但CPO还允许更高的交换机基数,从而将网络结构扁平化——使得整个集群能够通过使用CPO实现两层网络,而非传统三层网络。这样不仅降低了成本,也节约了功耗,这种节能效果几乎和降低收发器功耗一样显著。
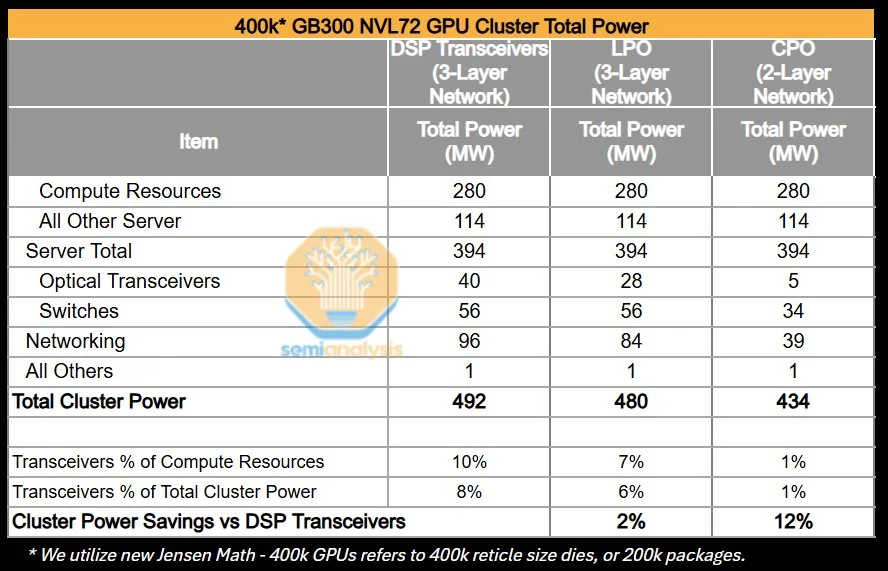
我们的分析显示,对于一个400k* GB200 NVL72部署而言,从基于DSP收发器的三层网络转向基于CPO的两层网络,总集群功耗节省最高可达12%,使得收发器功耗从占计算资源的10%降至仅1%。
来源:Semianalysis Nvidia今天推出了多款基于CPO的交换机,包括$昆腾(QMCO.US)$ X-800 3400的CPO版本,该交换机去年在GTC 2024上首发,具有144个800G端口,总吞吐量达到115T,并将配备144个MPO端口和18个ELS。该交换机将于2025年下半年推出。另一款Spectrum-X交换机提供512个800G端口,同样适用于高速、扁平化的网络拓扑,该以太网CPO交换机计划于2026年下半年推出。
来源:英伟达 尽管今天的发布已经具有突破性意义,我们仍认为Nvidia在CPO领域仅仅是热身。长远来看,CPO在规模化网络中的最大贡献在于,它能够大幅提升GPU扩展网络的基数和聚合带宽,从而实现更快、更扁平的网络拓扑,开启远超576 GPU的规模化世界。我们将很快发布一篇更详细的文章,深入探讨Nvidia的CPO解决方案。
Nvidia依旧称王,瞄准你的计算成本 今天,《信息》发布了一篇文章,称$亚马逊(AMZN.US)$ Trainium芯片的定价仅为H100价格的25%。与此同时,黄仁勋宣称:“当Blackwell开始大规模出货时,你甚至无法将H100免费送出。”我们认为这一说法极具分量。技术进步正在推动总体拥有成本的下降,而除了TPU之外,我们在各处都能看到Nvidia路线图的复制品。而黄仁勋正推动技术边界的不断突破。新的架构、机架设计、算法改进以及CPO技术都使Nvidia与竞争对手形成鲜明对比。Nvidia在几乎所有领域都处于领先地位,而当竞争对手追赶上来时,他们会在另一个方向继续突破。随着Nvidia保持一年一度的升级节奏,我们预计这一势头将继续。有人谈论ASIC将是计算的未来,但我们已经看到,像CPU时代那样的平台优势很难被超越。Nvidia正在通过GPU重新构建这种平台,我们预期他们将继续走在前沿。
正如黄仁勋所说,“祝你好运,跟上这位首席收入破坏者的步伐。”
编辑/Rocky
Semianalysis表示,在GTC2025大會上,英偉達推出的推理Token擴展、推理堆棧與Dynamo技術、共封裝光學(CPO)技術等創新將顯著降低AI總擁有成本,使得高效推理系統的部署成本大幅下降,並鞏固了英偉達在全球AI生態系統中的領先地位。
當地時間3月18日週二, $英偉達(NVDA.US)$ CEO黃仁勳在加州聖何塞舉行的英偉達AI盛會GTC 2025上發表主題演講。美國知名半導體諮詢機構Semianalysis深度解讀黃仁勳GTC演講,詳細闡述英偉達在推動AI推理性能提升方面的最新進展。
市場擔心的是,DeepSeek式的軟體優化以及英偉達主導的硬件進步帶來的巨大成本節省,可能導致對AI硬件的需求下降。然而,價格會影響需求,當AI成本降低時,AI能力的邊界不斷被突破,而需求隨之增加。
以下爲文章的核心觀點:
推理Token擴展:預訓練、後訓練與推理時擴展定律協同作用,使得AI模型能力不斷提升。
黃仁勳數學規則:包括FLOPs稀疏率、雙向帶寬計量,以及以封裝中GPU芯片數量計算GPU數量的新規則。
GPU與系統路線圖:介紹了Blackwell Ultra B300、Rubin及Rubin Ultra的關鍵規格與性能改進,強調了新一代產品在性能、內存和網絡互連上的突破。
推出的推理堆棧與Dynamo技術:通過智能路由器、GPU規劃器、改進的NCCL、NIXL和NVMe KVCache卸載管理器等新功能,極大提升了推理吞吐量和效率。
共封裝光學(CPO)技術:詳述了CPO在降低功耗、提高交換機基數和網絡扁平化方面的優勢,以及其在未來規模化網絡部署中的潛力。
文章指出,這些創新將顯著降低AI總擁有成本,使得高效推理系統的部署成本大幅下降,並鞏固了英偉達在全球AI生態系統中的領先地位。
Semianalysis深度解讀全文爲AI翻譯 推理 Token 爆炸 人工智能模型的進步加速迅猛,在過去六個月裏,模型的提升超過了此前六個月的進展。這一趨勢將持續下去,因爲三條擴展定律——預訓練擴展、後訓練擴展和推理時擴展——正協同作用,共同推動這一進程。
今年的GTC(GPU技術大會)將聚焦於應對新的擴展範式。
來源:英偉達 Claude 3.7在軟體工程領域展現了驚人的性能。Deepseek v3顯示出上一代模型的成本正在急劇下降,這將進一步推動其應用普及。OpenAI的o1和o3模型證明,延長推理時間和搜索功能意味着答案質量大幅提升。正如預訓練定律早期所展示的那樣,後訓練階段增加計算資源沒有上限。今年,Nvidia正致力於大幅提升推理成本效率,目標是實現35倍的推理成本改善,從而支持模型的訓練和部署。
去年市場的口號是「買得越多,省得越多」,但今年的口號變成了「省得越多,買得越多」。Nvidia在硬件和軟體方面的推理效率提升,使得模型推理和智能代理的部署成本大幅降低,從而實現成本效益的擴散效應,這正是傑文斯悖論的經典體現。
市場擔心的是,DeepSeek式的軟體優化以及Nvidia主導的硬件進步帶來的巨大成本節省,可能導致對AI硬件的需求下降,市場可能出現Token供過於求的情況。價格會影響需求,當AI成本降低時,AI能力的邊界不斷被突破,而需求隨之增加。如今,AI的能力受限於推理成本,隨着成本下降,實際的消費量反而會增加。
對Token通縮的擔憂類似於討論光纖互聯網每個數據包連接成本下降時,卻忽略了網站和互聯網應用對我們生活、社會和經濟的最終影響。關鍵區別在於,帶寬存在上限,而隨着能力的顯著提升和成本的下降,對AI的需求則可以無限增長。
Nvidia提供的數據支持了傑文斯悖論的觀點。現有模型的Token數超過100萬億,而一個推理模型的Token量是其20倍,計算量則高出150倍。
來源:英偉達 測試時的計算需要數十萬Token/查詢,每月有數億次查詢。後訓練擴展階段,即模型「上學」,每個模型需要處理數萬億Token,同時需要數十萬後訓練模型。此外,具備代理能力的AI意味着多個模型將協同工作,解決越來越複雜的問題。
黃仁勳數學每年都在變化 每年,黃仁勳都會推出新的數學規則。今年的情況更爲複雜,我們觀察到第三條新的黃仁勳數學規則。
第一條規則是,Nvidia公佈的FLOPs數據以2:4稀疏度(實際上無人使用)計,而真實性能指標是密集FLOPs——也就是說,H100在FP16下被報爲989.4 TFLOPs,實際密集性能約爲1979.81 TFLOPs。
第二條規則是,帶寬應以雙向帶寬來計量。NVLink5的帶寬被報爲1.8TB/s,因爲它的發送帶寬爲900GB/s,加上接收帶寬900GB/s。儘管這些數據在規格書中相加,但在網絡領域,標準是以單向帶寬計量。
現在,第三條黃仁勳數學規則出現了:GPU數量將按照封裝中GPU芯片的數量計,而非封裝數量。從Rubin系列開始,這一命名方式將被採用。第一代Vera Rubin機架將被稱爲NVL144,即使其系統架構與GB200 NVL72類似,只不過採用了相同的Oberon機架和72個GPU封裝。這種新的計數方式雖然讓人費解,但我們只能在黃仁勳的世界中接受這一變化。
現在,讓我們來回顧一下路線圖。
GPU和系統路線圖
來源:英偉達 Blackwell Ultra B300
來源:英偉達 Blackwell Ultra 300已預覽過,細節與去年聖誕節時我們分享的基本一致。主要規格如下:GB300不會以單板形式出售,而是作爲B300 GPU出現在一個便攜式SXM模塊上,同時搭載Grace CPU,也以便攜式BGA形式出現。在性能上,B300相對於B200在FP4 FLOPs密度上提升超過50%。內存容量升級到每個封裝288GB(8個12-Hi HBM3E堆疊),但帶寬維持在8 TB/s不變。實現這一目標的關鍵在於減少了許多(但不是全部)FP64運算單元,並將其替換爲FP4和FP6運算單元。雙精度工作負載主要用於HPC和超級計算,而非AI。雖然這讓HPC群體感到失望,但Nvidia正轉向強調更重要的AI市場。
B300 HGX版本現在稱爲B300 NVL16。這將採用之前稱爲「B300A」的單GPU版本,現在簡稱「B300」。由於單個B300沒有高速D2D接口連接兩個GPU芯片,可能存在更多通信間接費用。
B300 NVL16將取代B200 HGX形態,採用16個封裝和GPU芯片在一塊基板上。爲實現這一點,每個SXM模塊上放置2個單芯片封裝,共8個SXM模塊。尚不清楚Nvidia爲何不繼續採用8×雙芯B300,而選擇這種方式,我們懷疑這是爲了從更小的CoWoS模塊和封裝基板中提高產量。值得注意的是,該封裝技術將採用CoWoS-L而非CoWoS-S,這一決策意義重大。CoWoS-S的成熟度和產能是單芯B300A的原因,而這一轉變表明CoWoS-L已迅速成熟,其產率相比起初的低迷已有所穩定。
這16個GPU將通過NVLink協議通信,與B200 HGX類似,兩塊NVSwitch 5.0 ASIC將位於SXM模塊的兩個陣列之間。
新細節是,與以往的HGX不同,B300 NVL16將不再採用$Astera Labs(ALAB.US)$ 的重定時器。不過,一些超大規模雲服務提供商可能會選擇加入PCIe交換機。我們曾在今年早些時候向Core Research訂閱者透露過這一消息。
另一個重要細節是,B300將引入CX-8 NIC,該網卡提供4個200G的通道,總吞吐量達到800G,爲InfiniBand提供新一代網絡速度,這比現有的CX-7 NIC提升一倍。
Rubin技術規格
來源:英偉達 來源:Semianalysis Rubin將採用$台積電(TSM.US)$ 3nm工藝,擁有兩個reticle-size計算芯片,左右各配備兩個I/O Tile,內置所有NVLink、PCIe以及NVLink C2C IP,以釋放主芯片上更多用於計算的空間。
Rubin提供令人難以置信的50 PFLOPs密集FP4計算性能,比B300的代際性能增長超過三倍。Nvidia如何實現這一點?他們通過以下幾個關鍵向量進行擴展:
1、如上所述,I/O芯片釋放的面積可能增加20%-30%,可用於更多的流處理器和張量核。
2、Rubin將採用3nm工藝,可能使用定製的Nvidia 3NP或標準N3P。從3NP到4NP的轉變大幅提升了邏輯密度,但SRAM幾乎沒有縮減。
3、Rubin將具有更高的TDP——我們估計約爲1800W,這甚至可能推動更高的時鐘頻率。
4、結構上,Nvidia逐代擴大的張量核systolic array將進一步擴大:從Hopper的32×32到Blackwell的64×64,Rubin可能擴展至128×128。更大的systolic array提供了更好的數據複用和較低的控制複雜度,同時在面積和功耗上更高效。儘管編程難度增加,但Nvidia憑藉內置冗餘和修復機制實現了極高的參數良率,這使得即使個別計算單元失效,整體性能仍能得到保障。這與TPU不同,後者的超大張量核沒有相同的容錯能力。
來源:Semianalysis Rubin將繼續使用Oberon機架架構,如同GB200/300 NVL72,並配備Vera CPU——Grace的3nm繼任者。需要注意的是,Vera CPU將採用Nvidia全定製核心,而Grace則嚴重依賴Arm的Neoverse CSS核心。Nvidia還開發了一套定製互連繫統,使得單個CPU核心能訪問更多內存帶寬,這一點是AMD和Intel難以匹敵的。
這就是新命名方式的由來。新機架將命名爲VR200 NVL144,儘管系統架構與之前的GB200 NVL72類似,但由於每個封裝含有2個計算芯片,總計144個計算芯片(72個封裝×2個計算芯片/封裝),Nvidia正在改變我們統計GPU數量的方式!
至於AMD,其市場營銷團隊需要注意,AMD在宣稱MI300X家族可以擴展到64個GPU的規模上存在遺漏(每系統8個封裝×每封裝8個XCD芯片組),這是一個關鍵的市場機遇。
HBM與互連
Nvidia的HBM容量將一代比一代保持在288GB,但升級爲HBM4:8個堆疊,每個12-Hi,層密度保持24GB/層。HBM4的應用使得總帶寬得以提升,13TB/s的總帶寬主要得益於總線寬度翻倍至2048位,針腳速度爲6.5Gbps,符合JEDEC標準。
來源:Semianalysis NVLink第六代的速度翻倍至3.6TB/s(雙向),這來自於通道數量翻倍,Nvidia仍採用224G SerDes。
回到Oberon機架,背板依然採用銅背板,但我們認爲其電纜數量也相應增加,以適應每個GPU通道數量的翻倍。
NVSwitch方面,新一代NVSwitch ASIC也將通過通道數量翻倍來實現總帶寬的翻倍,這將進一步提高交換機的性能。
Rubin Ultra規格
來源:英偉達 Rubin Ultra是性能大幅提升的階段。Nvidia將直接在一個封裝中使用16個HBM堆疊,從8個增加至16個。整個機架將由4個掩模尺寸GPU組成,中間配有2個I/O芯片。計算區域翻倍,計算性能也翻倍至100 PFLOPs密集FP4性能。HBM容量增加到1024GB,超過普通Rubin的3.5倍。採用雙堆疊設計,同時密度和層數也提高。爲達到1TB內存,封裝中將有16個HBM4E堆疊,每個堆疊有16層32Gb DRAM核心芯片。
我們認爲,這種封裝將拆分爲兩個互連器放置在基板上,以避免使用一個超大互連器(幾乎8倍於掩模大小)。中間的2個GPU芯片將通過薄型I/O芯片進行互聯,通信通過基板實現。這需要一個超大ABF基板,其尺寸超出當前JEDEC封裝尺寸限制(寬度和高度均爲120mm)。
該系統擁有總計365TB的高速存儲,每個Vera CPU擁有1.2TB LPDDR,共計86TB(72個CPU),這爲每個GPU封裝留下約2TB的LPDDR,作爲額外的二級內存。這是對定製HBM基芯功能的實現。LPDDR內存控制器集成在基芯上,爲額外的二級內存服務,該內存位於板上LPCAMM模塊上,與Vera CPU所帶的二級內存協同工作。
來源:Semianalysis 這也是我們將看到Kyber機架架構推出的時候。
Kyber機架架構
Kyber機架架構的關鍵新特性在於,Nvidia通過將機架旋轉90度來提高密度。對於NVL576(144個GPU封裝)的配置,這是大規模擴展網絡規模的又一重大提升。
來源:英偉達 讓我們來看一下Oberon機架與Kyber機架的關鍵區別:
來源:Semianalysis ·計算托盤旋轉90度,形成類似於卡盒的形態,從而實現更高的機架密度。
·每個機架由4個筒倉組成,每個筒倉包括兩層18個計算卡。
對於NVL576,每個計算卡中包含一個R300 GPU和一個Vera CPU。
每個筒倉總共有36個R300 GPU和36個Vera CPU。
這使得NVLink的世界規模達到144個GPU(576個芯片)。
·PCB背板取代了銅線背板,作爲GPU與NVSwitch之間擴展鏈接的關鍵部件。
這一轉變主要是由於在較小的佔地面積內難以佈置電纜。
來源:英偉達 有跡象表明,供應鏈中出現了VR300 NVL1,152(288個GPU封裝)的Kyber機架變體。如果按照GTC主題演講中提到的晶圓數計算,您將看到紅色標註的288個GPU封裝。我們認爲這可能是未來的一款SKU,其機架密度和NVLink世界規模將從展示的NVL576(144個封裝)翻倍至NVL1,152(288個封裝)。
此外,還有一款全新NVSwitch第七代,這一點值得注意。這是第一次引入中平台的NVSwitch,使得交換機總帶寬和基數都有所提升,可擴展到單一域內576個GPU芯片(144個封裝),不過拓撲結構可能不再是全互聯的單級多平面結構,而可能轉爲具有過度訂閱的兩級多平面網絡拓撲,或甚至採用非Clos拓撲。
Blackwell Ultra改進的指數級硬件單元 各種注意力機制(如flash-attention、MLA、MQA和GQA)都需要矩陣乘法(GEMM)和SOFTMAX函數(行歸約和元素級指數運算)。
在GPU中,GEMM運算主要由張量核執行。雖然每代張量核性能不斷提升,但負責softmax計算的多功能單元(MUFU)提升幅度較小。
在bf16(bfloat16)Hopper中,計算注意力層的softmax需要佔用GEMM週期的50%。這要求內核工程師通過重疊計算來「隱藏」softmax的延遲,這使得編寫內核變得異常困難。
來源: Tri Dao @ CUDA Mode Hackathon 2024 在FP8(浮點數8位)的Hopper中,注意力層的softmax計算所需週期與GEMM相同。如果沒有任何重疊,注意力層的計算時間將翻倍,大約需要1536個週期來計算矩陣乘法,再加1536個週期來計算softmax。這就是重疊技術提高吞吐量的關鍵所在。由於softmax和GEMM所需週期相同,工程師需要設計出完美重疊的內核,但現實中很難達到這一理想狀態,根據阿姆達爾定律,完美重疊難以實現,硬件性能因此受損。
在Hopper GPU世界中,這一挑戰尤爲明顯,第一代Blackwell也面臨類似問題。Nvidia通過Blackwell Ultra解決了這一問題,在重新設計SM(流多處理器)並增加新的指令後,使MUFU計算softmax部分的速度提升了2.5倍。這將減輕對完美重疊計算的依賴,使得CUDA開發者在編寫注意力內核時有更大的容錯空間。
來源: Tri Dao @ CUDA Mode Hackathon 2024 這正是Nvidia新的推理堆棧和Dynamo技術大顯身手的地方。
推理堆棧與Dynamo 在去年的GTC上,Nvidia討論了GB200 NVL72的大規模GPU擴展如何使推理吞吐量較H200在FP8下提升15倍。
來源:英偉達 Nvidia並未放緩步伐,而是在硬件和軟體領域同時加速推理吞吐量的提升。
Blackwell Ultra GB300 NVL72較GB200 NVL72在FP4密集性能上提升50%,同時HBM容量也提升50%,這兩項均將提高推理吞吐量。路線圖中還包括Rubin系列中網絡速度的多項升級,這也將顯著提升推理性能。
下一步硬件在推理吞吐量方面的躍升將來自Rubin Ultra中擴展的網絡規模,其規模將從Rubin中的144個GPU芯片(或封裝)擴展到576個GPU芯片,這只是硬件改進的一部分。
在軟體方面,Nvidia推出了Nvidia Dynamo——一個開放的AI引擎堆棧,旨在簡化推理部署和擴展。Dynamo有潛力顛覆現有的VLLM和SGLang,提供更多功能且性能更高。結合硬件創新,Dynamo將使推理吞吐量和交互性之間的曲線進一步右移,尤其是爲需要更高交互性的應用場景提供改進。
來源:英偉達 Dynamo引入了多個關鍵新功能:
·Smart Router:智能路由器能在多GPU推理部署中合理分配每個Token,確保在預加載和解碼階段均衡負載,避免瓶頸。
·GPU Planner:GPU規劃器可以自動調整預加載和解碼節點,依據日內需求波動動態增加或重新分配GPU資源,進一步實現負載均衡。
·改進的NCCL Collective for Inference:Nvidia Collective Communications Library(NCCL)的新算法使得小消息傳輸延遲降低4倍,從而顯著提高推理吞吐量。
·NIXL(NVIDIA Inference Transfer Engine):NIXL利用InfiniBand GPU-Async Initialized(IBGDA)技術,將控制流和數據流均直接從GPU傳輸到NIC,無需通過CPU,極大降低延遲。
·NVMe KV-Cache Offload Manager:該模塊允許將KV Cache離線存儲到NVMe設備,避免在多輪對話中重複計算,從而加速響應並釋放預加載節點容量。
智能路由器
智能路由器能在多GPU推理部署中智能地將每個token同時路由到預加載(prefill)和解碼(decode)GPU上。在預加載階段,確保傳入的tokens均勻分配到各個負責預加載的GPU上,從而避免某個expet參數模塊因流量過載而形成瓶頸。
同樣,在解碼階段,確保序列長度和請求在負責解碼的各GPU之間得到合理分配和平衡也十分關鍵。對於那些處理量較大的expet參數模塊,GPU規劃器(GPU Planner)還可將其複製,以進一步維持負載平衡。
此外,智能路由器還能在所有模型副本之間實現負載均衡,這一點是vLLM等許多推理引擎所不具備的優勢。
來源:英偉達 GPU規劃器 GPU規劃器是預加載和解碼節點的自動擴展器,可根據一天內需求的自然波動啓動額外節點。它能夠在基於專家模型(MoE)的多個expet參數模塊之間實施一定程度的負載均衡,無論是在預加載還是在解碼階段。GPU規劃器會啓動額外的GPU,爲高負載expet參數模塊提供更多計算能力,並可根據需要在預加載和解碼節點之間動態重新分配資源,從而最大化資源利用率。
此外,它還支持調整用於解碼和預加載的GPU比例——這對像Deep Research這樣的應用尤爲重要,因爲這類應用需要預加載大量上下文信息,而實際生成的內容卻相對較少。
來源:英偉達 改進的NCCL集體通信
Nvidia Collective Communications Library (NCCL)中新增的一組低延遲通信算法,可以將小消息傳輸的延遲降低4倍,從而大幅提升整體推理吞吐量。
在今年的GTC上,Sylvain在演講中詳細介紹了這些改進,重點闡述了單次和雙次全歸約(all-reduce)算法如何實現這一效果。
由於AMD的RCCL庫實際上是Nvidia NCCL的複製版本,Sylvain對NCCL的重構將持續擴大CUDA的護城河,同時迫使AMD在同步Nvidia重大重構成果上耗費大量工程資源,而Nvidia則可以利用這些時間繼續推進集體通信軟體堆棧和算法的前沿發展。
來源:英偉達 NIXL —— Nvidia推理傳輸引擎
爲了在預加載節點和解碼節點之間實現數據傳輸,需要低延遲、高帶寬的通信傳輸庫。NIXL採用InfiniBand GPU-Async Initialized (IBGDA)技術。
目前在NCCL中,控制流經過CPU代理線程,而數據流則直接傳輸到網卡,無需經過CPU緩衝。而使用IBGDA後,控制流與數據流均可直接從GPU傳輸到網卡,無需CPU中轉,從而大幅降低延遲。
此外,NIXL還能將在CXL、本地NVMe、遠程NVMe、CPU內存、遠程GPU內存及GPU之間傳輸數據的複雜性進行抽象,簡化數據移動流程。
來源:英偉達 NVMe KVCache卸載管理器
KVCache卸載管理器通過將之前用戶對話中生成的KV緩存存儲到NVMe設備中,而非直接丟棄,來提高預加載階段整體效率。
來源:英偉達 在用戶與大型語言模型(LLM)進行多輪對話時,模型需要將前期問答作爲輸入token納入考量。傳統上,推理系統會丟棄用於生成這些問答的KV緩存,導致必須重新計算,從而重複同樣的計算過程。
而採用NVMe KVCache卸載後,當用戶暫時離開時,KV緩存會被卸載到NVMe存儲中;當用戶重新提問時,系統可以迅速從NVMe中檢索KV緩存,免去了重新計算的開銷。
這不僅釋放了預加載節點的計算能力,使其能夠處理更多的輸入流量,同時還改善了用戶體驗,顯著縮短了從開始對話到接收到第一個token的時間。
來源:英偉達 根據DeepSeek在開源周第6天的GitHub說明,研究人員披露其磁盤KV緩存命中率爲56.3%,表明在多輪對話中典型的KV緩存命中率可達到50%-60%,這對預加載部署效率提升起到了顯著作用。雖然在對話較短時,重新計算可能比加載更便宜,但總體來看,採用NVMe存儲方案所帶來的節約成本是巨大的。
追蹤DeepSeek開源周的朋友對上述技術應該並不陌生。這些技術堪稱快速了解Nvidia Dynamo創新成果的絕佳途徑,而Nvidia也將推出更多關於Dynamo的文檔。
所有這些新特性共同實現了推理性能的大幅加速。Nvidia甚至討論過,當Dynamo部署在現有的H100節點上時,性能如何進一步提升。基本上,Dynamo使得DeepSeek的創新成果普惠整個社區,不僅限於那些擁有頂尖推理部署工程能力的AI實驗室,所有用戶都能部署高效的推理系統。
最後,由於Dynamo能夠廣泛處理分散推理和專家並行性,它特別有利於單個複製和更高交互性部署。當然,要充分發揮Dynamo的能力,必須有大量節點作爲前提,從而實現顯著的性能改進。
來源:英偉達 這些技術共同帶來了推理性能的巨大提升。Nvidia提到,當Dynamo部署在現有的H100節點上時,也能實現顯著的性能改進。換句話說,Dynamo使得整個開源推理技術的最佳成果惠及所有用戶,不僅僅是那些擁有深厚工程背景的頂級AI實驗室。這讓更多的企業能夠部署高效的推理系統,降低整體成本,提高應用的交互性和擴展性。
AI總擁有成本下降 在討論完Blackwell之後,黃仁勳強調,這些創新已使他成爲「首席收入破壞者」。他指出,Blackwell相比Hopper的性能提升達68倍,使得成本下降了87%。而Rubin預計將實現比Hopper高900倍的性能提升,成本降低99.97%。
顯然,Nvidia正以不懈的步伐推動技術進步——正如黃仁勳所言:「當Blackwell開始大規模出貨時,你甚至不可能把Hopper免費送出。」
來源:英偉達 我們早在去年10月的《AI Neocloud行動指南》中就強調,產品週期早期部署計算能力的重要性,而這正是驅動H100租賃價格從2024年中期開始加速下跌的原因。我們一直呼籲整個生態系統優先部署下一代系統,如B200和GB200 NVL72,而不是繼續採購H100或H200。
我們的AI雲總擁有成本(TCO)模型已經向客戶展示了各代芯片生產率的躍升,以及這種躍升如何推動AI Neocloud租賃價格的變化,進而影響芯片所有者的淨現值。截至目前,我們在2024年初發佈的H100租賃價格預測模型準確率達到98%。
來源: AI TCO Model CPO(共封裝光學)技術 來源:英偉達 在主題演講中,Nvidia宣佈了首個共封裝光學(CPO)解決方案,將其部署於擴展交換機中。通過CPO,收發器被外部激光源(ELS)取代,與直接放置在芯片硅片旁邊的光學引擎(OE)協同工作,實現數據通信。現在,光纖直接插入交換機上的端口,將信號路由至光學引擎,而不再依賴傳統收發器端口。
來源:英偉達 CPO的主要優勢在於顯著降低功耗。由於交換機上不再需要數字信號處理器(DSP),而且可以使用功耗更低的激光光源,因此實現了顯著的功耗節省。使用線性可插光模塊(LPO)也能取得類似效果,但CPO還允許更高的交換機基數,從而將網絡結構扁平化——使得整個集群能夠通過使用CPO實現兩層網絡,而非傳統三層網絡。這樣不僅降低了成本,也節約了功耗,這種節能效果幾乎和降低收發器功耗一樣顯著。
我們的分析顯示,對於一個400k* GB200 NVL72部署而言,從基於DSP收發器的三層網絡轉向基於CPO的兩層網絡,總集群功耗節省最高可達12%,使得收發器功耗從佔計算資源的10%降至僅1%。
來源:Semianalysis Nvidia今天推出了多款基於CPO的交換機,包括$昆騰(QMCO.US)$ X-800 3400的CPO版本,該交換機去年在GTC 2024上首發,具有144個800G端口,總吞吐量達到115T,並將配備144個MPO端口和18個ELS。該交換機將於2025年下半年推出。另一款Spectrum-X交換機提供512個800G端口,同樣適用於高速、扁平化的網絡拓撲,該以太網CPO交換機計劃於2026年下半年推出。
來源:英偉達 儘管今天的發佈已經具有突破性意義,我們仍認爲Nvidia在CPO領域僅僅是熱身。長遠來看,CPO在規模化網絡中的最大貢獻在於,它能夠大幅提升GPU擴展網絡的基數和聚合帶寬,從而實現更快、更扁平的網絡拓撲,開啓遠超576 GPU的規模化世界。我們將很快發佈一篇更詳細的文章,深入探討Nvidia的CPO解決方案。
Nvidia依舊稱王,瞄準你的計算成本 今天,《信息》發佈了一篇文章,稱$亞馬遜(AMZN.US)$ Trainium芯片的定價僅爲H100價格的25%。與此同時,黃仁勳宣稱:「當Blackwell開始大規模出貨時,你甚至無法將H100免費送出。」我們認爲這一說法極具分量。技術進步正在推動總體擁有成本的下降,而除了TPU之外,我們在各處都能看到Nvidia路線圖的複製品。而黃仁勳正推動技術邊界的不斷突破。新的架構、機架設計、算法改進以及CPO技術都使Nvidia與競爭對手形成鮮明對比。Nvidia在幾乎所有領域都處於領先地位,而當競爭對手追趕上來時,他們會在另一個方向繼續突破。隨着Nvidia保持一年一度的升級節奏,我們預計這一勢頭將繼續。有人談論ASIC將是計算的未來,但我們已經看到,像CPU時代那樣的平台優勢很難被超越。Nvidia正在通過GPU重新構建這種平台,我們預期他們將繼續走在前沿。
正如黃仁勳所說,「祝你好運,跟上這位首席收入破壞者的步伐。」
編輯/Rocky





 随着英伟达在硬件和软件方面的推理效率提升,使得模型推理和智能代理的部署成本大幅降低,从而实现成本效益的扩散效应,实际的消费量反而会增加,正如英伟达的口号所说的那样:“买越多、省越多”。
随着英伟达在硬件和软件方面的推理效率提升,使得模型推理和智能代理的部署成本大幅降低,从而实现成本效益的扩散效应,实际的消费量反而会增加,正如英伟达的口号所说的那样:“买越多、省越多”。

 隨着英偉達在硬件和軟體方面的推理效率提升,使得模型推理和智能代理的部署成本大幅降低,從而實現成本效益的擴散效應,實際的消費量反而會增加,正如英偉達的口號所說的那樣:「買越多、省越多」。
隨着英偉達在硬件和軟體方面的推理效率提升,使得模型推理和智能代理的部署成本大幅降低,從而實現成本效益的擴散效應,實際的消費量反而會增加,正如英偉達的口號所說的那樣:「買越多、省越多」。


















 ,而今天在早盤衝高至24000附近入了熊仔后,指數大幅下跌最多接近6百多點,即時把昨日虧損賺回有突多
,而今天在早盤衝高至24000附近入了熊仔后,指數大幅下跌最多接近6百多點,即時把昨日虧損賺回有突多

 ,而今天再破新高, 最高 24076 , 其後收市時轉跌約70點, 出了陰燭, 暫時走勢仍未有破壞, 不過由前底至今已經上漲接近至6千點, 本人覺得有貨者可以繼續持貨直到 明顯有走勢轉壞才止賺離場, 沒貨者可以等待回調后再上車, 其實本人也希望能夠快點有回調, 一來可以上車, 二來回一回氣也健康
,而今天再破新高, 最高 24076 , 其後收市時轉跌約70點, 出了陰燭, 暫時走勢仍未有破壞, 不過由前底至今已經上漲接近至6千點, 本人覺得有貨者可以繼續持貨直到 明顯有走勢轉壞才止賺離場, 沒貨者可以等待回調后再上車, 其實本人也希望能夠快點有回調, 一來可以上車, 二來回一回氣也健康 ,暫時看法都是跟之前一樣, 覺得即使有所回調應該都不會跌得太深,但假若期貨失守22350企不穩收,便可能還有下跌空間, 期貨短期要跌破21400的機會應該也不大, 所以本人覺得如果有大幅的回調也是一個機會分注做多。近日都堅持不過夜持倉,暫只做即市, 因為不高追,也不隨便做空。
,暫時看法都是跟之前一樣, 覺得即使有所回調應該都不會跌得太深,但假若期貨失守22350企不穩收,便可能還有下跌空間, 期貨短期要跌破21400的機會應該也不大, 所以本人覺得如果有大幅的回調也是一個機會分注做多。近日都堅持不過夜持倉,暫只做即市, 因為不高追,也不隨便做空。
評論(5)
請選擇舉報原因