来源:极客公园
作者:黎诗韵
历史上第一次有公司会连续开 12 天的产品发布会——当 OpenAI 宣布这个决定之后,全球科技圈的期待值被拉满了。但直到发布会接近尾声,「就这?就这?」一位 AI 从业者如此表达他的观感。
这似乎代表了某种主流看法:此次 OpenAI 发布会,亮点不大、低于预期。
 前十一天,OpenAI 的发布会涉及技术、产品形态、商业模式和产业生态等多个重要更新,包括完整的推理模型 o1、强化微调、文生视频 Sora、更强的写作和编程工具 Canvas、与 Apple 生态系统的深度整合、语音和视觉功能、Projects 功能、ChatGPT 搜索、给 ChatGPT 打电话和 WhatsApp 聊天等等。
前十一天,OpenAI 的发布会涉及技术、产品形态、商业模式和产业生态等多个重要更新,包括完整的推理模型 o1、强化微调、文生视频 Sora、更强的写作和编程工具 Canvas、与 Apple 生态系统的深度整合、语音和视觉功能、Projects 功能、ChatGPT 搜索、给 ChatGPT 打电话和 WhatsApp 聊天等等。
但正如上述 AI 从业者感到失望的原因,「还以为会发 GPT-5。」在发布会结束第二天,据外媒报道,OpenAI 的 GPT-5 研发受阻。
不过,最后一天发布的 o3 是个例外。它是 o1 的下一代推理模型,在数学、代码、物理等多项测试中表现惊人——一位国内大模型公司的技术人士谈及 o3 给他带来的震撼,「AGI 已来。」他说。技术人士对 o3 评价都颇高。
回顾这 12 天的发布会,OpenAI 一边秀出了技术「肌肉」,另一边不断优化产品形态、扩大落地应用的空间。有人打趣道,就像一场「直播带货」,OpenAI 希望吸引更多用户、开发者使用 ChatGPT。在新的一年,OpenAI 在日活、营收等数据上或许会迎来飞跃。
 o3 发布会|图片来源:OpenAI
o3 发布会|图片来源:OpenAI但这个过程不一定会顺利。尽管模型能力变强,但由于数据掣肘、封装能力、模型成本过高等原因,强大模型和应用落地之间仍有较大距离。
OpenAI 此次发布会似乎透露出这样一种趋势:目前大模型行业的竞争焦点不仅在于模型参数和技术上限,也在于用户体验和市场规模。需要两者齐头并进,才能保持领先。
在梳理了 OpenAI 这 12 场发布会的主要信息、以及与国内大模型行业人士交流后,极客公园总结了以下几个关键看点。
o3 的智能深度已经够了,但能否称之为 AGI 要看智能广度
「疯狂,太疯狂了。」这是国内某模型负责人看到 o3 之后的第一反应。
在数学、编码、博士级科学问答等复杂问题上,o3 表现出了超越部分人类专家的水平。比如,在涉及生物学、物理学和化学的博士级科学考试 GPQA Diamond 中,o3 的准确率达到 87.7%,而这些领域的博士专家只能达到 70%;在美国 AIME 数学竞赛中,o3 取得 96.7 分、只错了一道题,相当于顶级数学家的水平。
被广为讨论的是其代码能力。在目前全世界最大的算法练习和竞赛平台 Codeforces 上,o3 得分为 2727 分、相较 o1 提升了 800 多分,相当于位列 175 名的人类选手。甚至,它超过了 OpenAI 的研究高级副总裁 Mark Chen(得分 2500 分)。
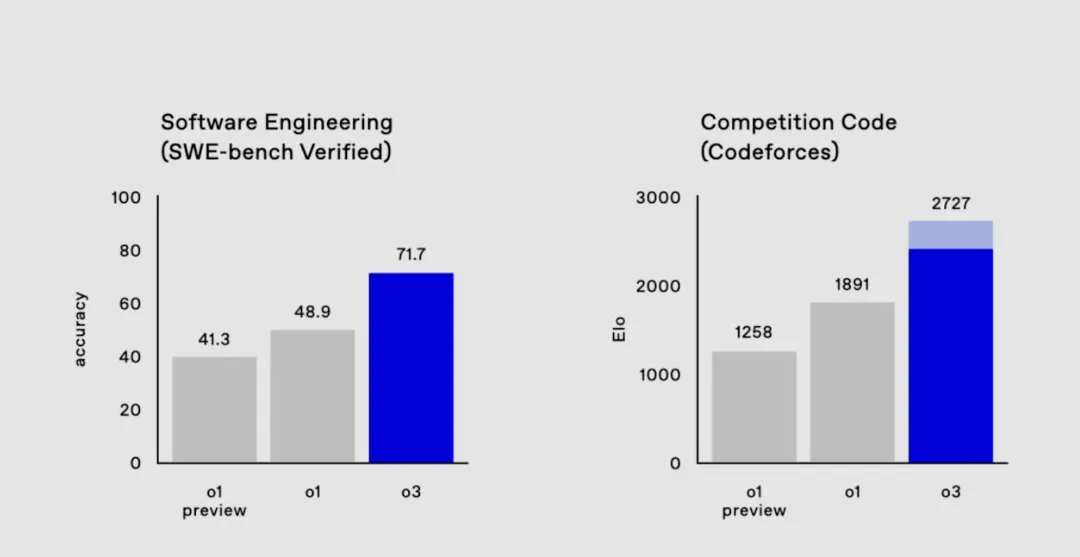 o1-preview、o1、o3 的代码能力对比 | 图片来源:OpenAI
o1-preview、o1、o3 的代码能力对比 | 图片来源:OpenAI自 9 月推出 o1-preview 版本以来,短短三个月时间内,o1 系列模型在推理能力上完成了超强进化。在发布会第一天推出的 o1 完整版,其思考速度较 o1-preview 提高了约 50%、针对困难现实问题的重大错误减少了 34%、同时还支持多模态输入(可识别图像)。而今天的 o3 在复杂问题上则已超越部分人类专家水平。
「从 o1 到 o3 是通过增加推理计算量实现对模型能力的提升,随着国内外 Deepseek-R1、Gemini 2.0 Flash Thinking 等发布,表明大模型开始从预训练 Scaling Law 转向推理的 Scaling Law。」清华大学长聘副教授、面壁智能发起人刘知远对极客公园表示。
自 OpenAI 发布 o1-preview,大模型浪潮的技术范式从最初的预训练 Scaling Law(缩放定律),即不断扩大模型训练参数、提升其智能上限,切换到了新一轮的、升级的技术范式,即在推理阶段注入强化学习、提高复杂推理能力。
在前一种范式下,模型主要是通过 next token prediction(下一个词预测)给出答案,更偏向「快思考」。就像「读了万卷书」,但「学而不思则罔」,没法完成数学、编程等更复杂的推理任务。
而在后一种范式下,模型不会马上给出答案,而是会「慢思考」,先引入 CoT(思维链),把复杂的问题规划、分解为更简单的步骤,最后得到结果。而当方法不起作用时、它会尝试另一种方法,在强化学习中提升复杂推理能力——随着模型不断进行「慢思考」和强化学习,其推理能力会指数级上升,这就是推理的 Scaling Law。
对于 o3 超出人类专家的超强研究推理能力——在刘知远看来,这表明 o3 正在朝「超高智能的超级计算机」方向前进。
不少行业人士认为,这会对前沿科学领域影响深远。从积极的角度来看,o3 极强的研究推理能力,能够帮助推动人类在数学、物理学、生物学、化学等学科的基础科学研究。不过,也有人担心它会冲击科研人员的工作。
此次 o3 带来的惊人的智能深度,似乎让人看到了 AGI 的曙光。但在刘知远看来,正如信息革命的标志并非大型计算机、而是个人计算机(PC)的普及,只有实现 AGI 的大众化、普惠化,即让每个人拥有自己的大模型、解决好自己日常的问题,才意味着真正的智能革命。
「毕竟我们并不需要让陶哲轩、Hinton(均为顶尖科学家)来为我们解决日常问题。」他说。
这背后涉及的关键问题是,o3 模型的智能深度能否泛化到其他各种领域、具有足够的智能广度——在上述某国内大模型公司的技术人士看来,只有同时突破智能的深度、广度,才能称之为 AGI。他对此感到乐观,「就像你们班来了一个转校生,你没跟他接触过,但他考试数学和编程都考了全班第一。你觉得他语文和英语会很差吗?」
对于国内的大模型公司来说,核心的问题还是如何追赶 o3。从训练架构、数据、训练方法和评价数据集等关键要素来看,这似乎是工程化能解决的问题。
「你认为距离我们拥有一个 o3 水平的开源模型还有多远?」
「一年之后。」上述模型负责人回答。
模型只是发动机,关键是帮助开发者用起来
尽管 o3 的模型能力很强,但在一些应用层人士看来,模型和落地应用之间还有很大距离。「今天 OpenAI 训练了爱因斯坦,但如果想变成上市公司的首席科学家,依然是有距离的。」澜码科技创始人兼 CEO 周健对极客公园表示。
作为大模型中间层,澜码科技是国内较早探索将大模型应用落地、打造 AI Agent 的公司。在周健看来,大模型只是一个基础设施,需要结合场景去做很多工作才能用起来,而目前主要的掣肘是数据。
在很多场景里,拿到完整数据是很难的,有很多数据甚至是没有数字化的。比如猎头可能需要简历数据,但很多简历数据并没有被数字化。
而成本是影响 o 系列模型落地的最关键因素。根据 ARC-AGI 测试标准,o3-low(低计算量模式)每个任务耗费 20 美金,o3-high(高计算量模式)每个任务耗费数千美金——哪怕问一个最简单的问题,也要花费近两万元。收益和成本根本不能打平,o3 的落地可能还需要漫长一段时间。
![bigjpg]() o 系列模型的成本测算 | 图片来源:ARC-AGI 测试标准
o 系列模型的成本测算 | 图片来源:ARC-AGI 测试标准在帮助模型应用落地的问题上,OpenAI 在发布会上也发布了相应的功能方案。比如第二天,OpenAI 专为开发者发布了 AI 强化微调(AI Reinforcement Fine-Tuning)功能,这是周健最关心的功能。它指的是,模型能通过少量数据,优化推理能力、提升性能。
这尤其适用于精细化领域的应用。OpenAI 技术人士称,它能帮助任何需要在 AI 模型方面拥有深厚专业知识的领域,比如法律、金融、工程、保险。一个例子是,最近汤森路透使用强化微调来微调 o1-mini,得到了好用的 AI 法律助理,帮助他们的法律专业人员完成了一些「最具分析性的工作流程」。
比如第九天,o1 模型终于向开发者开放使用。它支持函数调用和视觉能力;引入了 WebRTC,实现实时语音应用开发;推出了偏好微调功能,帮助开发者定制模型;发布了 Go 和 JAVA SDK,让开发者可快速上手集成。
同时,它带来了更低成本、更高质量的 4o 语音模型。其中,4o 音频价格下调 60%,降至输入 $40/百万 tokens、输出 $80/百万 tokens,缓存音频价格降低 87.5%、至 $2.50/百万 tokens;对于预算有限的开发者,OpenAI 推出 GPT-4o mini,音频费用仅为 4o 的四分之一。
这个新功能也是周健关注的。他认为,更新的实时语音、视觉识别等功能,将能更好地在营销、电话客服和销售外呼等场景应用。按他的经验,当 OpenAI 推出某些领先技术,一般国内 6-12 个月就可以追上。这让他对新一年的应用业务充满信心。
Sora 的视频生成低于预期,但产品开放会提升其物理模拟能力
年初 OpenAI 发布 Sora 的 demo 时,引发了全球科技圈的震撼。但这一整年,国内各大模型公司纷纷竞逐文生视频赛道——等到 OpenAI 在发布会第三天正式放出 Sora 时,国内的文生视频公司松了一口气。
「基本没有什么超出预期的内容,真实感、物理特性等方面相比于 2 月份的发布并没有显著变化,从基础模型能力的层面来说算是低于预期的。」生数科技联合创始人兼 CEO 唐家渝对极客公园表示。
目前,字节、快手、MiniMax、智谱、生数、爱诗等公司均推出了自己的文生视频产品。「Sora 的效果和实力综合来看并无明显领先优势,我们看到自己与OpenAI确实还是齐头并进的。」唐家渝表示。
在他看来,Sora 稍微有亮点的部分是在基础的文生视频、图生视频以外,提供了一些提升视频创作体验的编辑功能,说明 OpenAI 确实更关注产品体验了。
比如故事板功能,它相当于按时间轴的方式,把一段故事(视频)切成了多个不同的故事卡(视频帧)。用户只需要设计和调整每张故事卡(视频帧),Sora 会自动把它们补成一段流畅的故事(视频)——这很像电影里的分镜、动画的手稿,当导演画好分镜、漫画师写好手稿、一个动画、片子就做好了。它能让创作者更好地表达自己。
此外,它还推出了文字直接修改视频、无缝融合两段不同的视频、给视频改变画风等功能,它们相当于是直接给视频加「特效」了。而一般的文生视频产品,无法直接修改原视频,只能不断调整 prompt(提示词)、生成新视频。
![bigjpg]() Sora 的故事板功能 | 图片来源:OpenAI
Sora 的故事板功能 | 图片来源:OpenAI在唐家渝看来,这些功能设计确实都是为了给创作者更大的创作自由度,类似的功能已经在 Vidu(生数科技的文生视频产品)迭代的计划中。「Sora 这些功能的实现对于我们来说并没有难度,实现路径也已经非常明确了。」他说。
在发布会上,Sam Altman 阐释了做 Sora 的原因:一是工具性价值,为创意人员提供创作工具;二是交互价值,大模型不应只通过文本交互,也应扩展多模态;三是最重要的——它和 AGI 技术愿景是一致的,Sora 在学习更多关于世界的规律,最终有可能建立理解物理规律的「世界模型」。
在唐家渝看来,目前 Sora 生成的视频中,依然有不少明显违背物理定律的地方,跟 2 月的 demo 相比进步不大。在他看来,Sora 发布后、会有更多人来尝试和探索它的物理模拟能力,这些测试样本或许对提升它的物理模拟起到一定的指导作用。
内加功能、外接生态,ChatGPT 能变成 Super App 吗?
在 o 系列模型、Sora、以及开发者服务之外,OpenAI 在发布会上的主要动作,一方面还是在产品侧持续增加新功能,优化用户体验。另一方面是积极推动与苹果等企业的深度合作,探索 AI 融入终端设备和操作系统。
从前者可以看到,ChatGPT 的演进方向,似乎是要成为一个「无所不能、无所不在、人人可得」的超级 AI 助理。据极客公园了解,OpenAI 创立之初的愿景就是打造一个「无所不能」的 Agent,它能理解人类的指令、自动调用不同的工具、满足人类的需要。看起来,终点即起点。
比如第六天,ChatGPT 增加了支持屏幕共享的视频通话和圣诞老人语音模式。前者让用户能与 AI 实时视频通话,分享屏幕或展示周围环境,进行多模态互动,复现了电影《Her》的场景。
比如第八天,ChatGPT 向全体用户开放了其搜索功能。在基础搜索外,它还增加了语音搜索;同时,它集成了手机设备的地图服务,能调取苹果、谷歌地图展示搜索结果列表;它还与多家顶级新闻和数据提供商建立了合作关系,支持用户查看股票行情、体育赛事得分、天气预报等信息。
又比如第十一天,ChatGPT 宣布扩展了与桌面软件的集成。它能接入更多编码应用程序,如 BBEdit、MatLab、NOVA、Script Editor 等;它能和 Warp(文件共享应用)、XCode 编辑器等应用一起使用;它还能在语音模式下与其他应用程序协同工作,包括 NOTION、Apple Notes 等;
现场演示有这样一个例子,当用户在 Apple Notes 中设定「节日派对歌单」,并语音征询 ChatGPT 对候选歌曲的意见。ChatGPT 能指出用户的错误,如将圣诞歌曲《Frosty the Snowman》误写为《Freezy the Snowman》。
![bigjpg]() ChatGPT 指出了 Apple Notes 的错误 | 图片来源:OpenAI
ChatGPT 指出了 Apple Notes 的错误 | 图片来源:OpenAI「ChatGPT 会从单纯的会话助手向更为强大的代理工具转变。」OpenAI 首席产品官凯文·韦尔(Kevin Weil)称。
而另一方面,OpenAI 也在积极扩张生态,通过融入人们最常用的终端设备、操作系统、上层软件等,触达更广泛人群。
比如第五天,ChatGPT 宣布集成苹果智能生态,融入 iOS、MacOS 和 iPadOS,支持用户跨平台、跨应用调用 AI 能力,包括 Siri 交互、写作工具(Writing Tools),以及视觉功能智能识别场景内容(Visual Intelligence)等。通过这次合作,ChatGPT 触达了全球数十亿苹果用户。它也开启了大模型与端侧、操作系统合作的先例。
比如第十天,ChatGPT 公布了自己的电话联系方式(1-800-242-8478),美国用户每月可拨打该号码享受 15 分钟的免费通话。同时上线的还有 WhatsApp 联系人(1-800-242-8478),全球任何用户均可通过 WhatsApp 向该号码发送消息,目前只限文字信息。
![bigjpg]() ChatGPT 公布了自己的电话联系方式 | 图片来源:OpenAI
ChatGPT 公布了自己的电话联系方式 | 图片来源:OpenAI全球部分国家、地区的智能手机和移动互联网渗透率还远远不足,通过电话这种最基础的通讯工具,ChatGPT 触达了这些人群。同时它也通过 WhatsApp,触达了其近 30 亿用户。
无论是内加功能、还是外接生态,ChatGPT 核心是希望产品触达更广泛人群,变成真正的 Super APP。但也有人并不看好它这种不断内加功能、将业务线拉得无尽长的做法,甚至将其形容为「铺了一个大饼,但每一块饼都有点薄,深入不下去」。而很多业务都需要足够深才能发挥价值、也有对应的公司在深耕,这或许是 OpenAI 要面临的挑战。
尽管 o3 模型让外界看到了 OpenAI 惊人的技术实力,但关于推理的 Scaling Law 能达到怎样的智能上限、以及 GPT-5 的难产问题,依然让外界对这家公司的技术发展充满疑虑。这次发布会上,OpenAI 将关注点转而放在产品形态、合作生态和落地建设上,也未尝不是一种思路。这两者的结合,可能决定了行业接下来的走向。
编辑/rice
來源:極客公園
作者:黎詩韻
歷史上第一次有公司會連續開 12 天的產品發佈會——當 OpenAI 宣佈這個決定之後,全球科技圈的期待值被拉滿了。但直到發佈會接近尾聲,「就這?就這?」一位 AI 從業者如此表達他的觀感。
這似乎代表了某種主流看法:此次 OpenAI 發佈會,亮點不大、低於預期。
 前十一天,OpenAI 的發佈會涉及技術、產品形態、商業模式和產業生態等多個重要更新,包括完整的推理模型 o1、強化微調、文生視頻 Sora、更強的寫作和編程工具 Canvas、與 Apple 生態系統的深度整合、語音和視覺功能、Projects 功能、ChatGPT 搜索、給 ChatGPT 打電話和 WhatsApp 聊天等等。
前十一天,OpenAI 的發佈會涉及技術、產品形態、商業模式和產業生態等多個重要更新,包括完整的推理模型 o1、強化微調、文生視頻 Sora、更強的寫作和編程工具 Canvas、與 Apple 生態系統的深度整合、語音和視覺功能、Projects 功能、ChatGPT 搜索、給 ChatGPT 打電話和 WhatsApp 聊天等等。
但正如上述 AI 從業者感到失望的原因,「還以爲會發 GPT-5。」在發佈會結束第二天,據外媒報道,OpenAI 的 GPT-5 研發受阻。
不過,最後一天發佈的 o3 是個例外。它是 o1 的下一代推理模型,在數學、代碼、物理等多項測試中表現驚人——一位國內大模型公司的技術人士談及 o3 給他帶來的震撼,「AGI 已來。」他說。技術人士對 o3 評價都頗高。
回顧這 12 天的發佈會,OpenAI 一邊秀出了技術「肌肉」,另一邊不斷優化產品形態、擴大落地應用的空間。有人打趣道,就像一場「直播帶貨」,OpenAI 希望吸引更多用戶、開發者使用 ChatGPT。在新的一年,OpenAI 在日活、營收等數據上或許會迎來飛躍。
o3 發佈會|圖片來源:OpenAI 但這個過程不一定會順利。儘管模型能力變強,但由於數據掣肘、封裝能力、模型成本過高等原因,強大模型和應用落地之間仍有較大距離。
OpenAI 此次發佈會似乎透露出這樣一種趨勢:目前大模型行業的競爭焦點不僅在於模型參數和技術上限,也在於用戶體驗和市場規模。需要兩者齊頭並進,才能保持領先。
在梳理了 OpenAI 這 12 場發佈會的主要信息、以及與國內大模型行業人士交流後,極客公園總結了以下幾個關鍵看點。
o3 的智能深度已經夠了,但能否稱之爲 AGI 要看智能廣度
「瘋狂,太瘋狂了。」這是國內某模型負責人看到 o3 之後的第一反應。
在數學、編碼、博士級科學問答等複雜問題上,o3 表現出了超越部分人類專家的水平。比如,在涉及生物學、物理學和化學的博士級科學考試 GPQA Diamond 中,o3 的準確率達到 87.7%,而這些領域的博士專家只能達到 70%;在美國 AIME 數學競賽中,o3 取得 96.7 分、只錯了一道題,相當於頂級數學家的水平。
被廣爲討論的是其代碼能力。在目前全世界最大的算法練習和競賽平台 Codeforces 上,o3 得分爲 2727 分、相較 o1 提升了 800 多分,相當於位列 175 名的人類選手。甚至,它超過了 OpenAI 的研究高級副總裁 Mark Chen(得分 2500 分)。
o1-preview、o1、o3 的代碼能力對比 | 圖片來源:OpenAI 自 9 月推出 o1-preview 版本以來,短短三個月時間內,o1 系列模型在推理能力上完成了超強進化。在發佈會第一天推出的 o1 完整版,其思考速度較 o1-preview 提高了約 50%、針對困難現實問題的重大錯誤減少了 34%、同時還支持多模態輸入(可識別圖像)。而今天的 o3 在複雜問題上則已超越部分人類專家水平。
「從 o1 到 o3 是通過增加推理計算量實現對模型能力的提升,隨着國內外 Deepseek-R1、Gemini 2.0 Flash Thinking 等發佈,表明大模型開始從預訓練 Scaling Law 轉向推理的 Scaling Law。」清華大學長聘副教授、面壁智能發起人劉知遠對極客公園表示。
自 OpenAI 發佈 o1-preview,大模型浪潮的技術範式從最初的預訓練 Scaling Law(縮放定律),即不斷擴大模型訓練參數、提升其智能上限,切換到了新一輪的、升級的技術範式,即在推理階段注入強化學習、提高複雜推理能力。
在前一種範式下,模型主要是通過 next token prediction(下一個詞預測)給出答案,更偏向「快思考」。就像「讀了萬卷書」,但「學而不思則罔」,沒法完成數學、編程等更復雜的推理任務。
而在後一種範式下,模型不會馬上給出答案,而是會「慢思考」,先引入 CoT(思維鏈),把複雜的問題規劃、分解爲更簡單的步驟,最後得到結果。而當方法不起作用時、它會嘗試另一種方法,在強化學習中提升複雜推理能力——隨着模型不斷進行「慢思考」和強化學習,其推理能力會指數級上升,這就是推理的 Scaling Law。
對於 o3 超出人類專家的超強研究推理能力——在劉知遠看來,這表明 o3 正在朝「超高智能的超級計算機」方向前進。
不少行業人士認爲,這會對前沿科學領域影響深遠。從積極的角度來看,o3 極強的研究推理能力,能夠幫助推動人類在數學、物理學、生物學、化學等學科的基礎科學研究。不過,也有人擔心它會衝擊科研人員的工作。
此次 o3 帶來的驚人的智能深度,似乎讓人看到了 AGI 的曙光。但在劉知遠看來,正如信息革命的標誌並非大型計算機、而是個人計算機(PC)的普及,只有實現 AGI 的大衆化、普惠化,即讓每個人擁有自己的大模型、解決好自己日常的問題,才意味着真正的智能革命。
「畢竟我們並不需要讓陶哲軒、Hinton(均爲頂尖科學家)來爲我們解決日常問題。」他說。
這背後涉及的關鍵問題是,o3 模型的智能深度能否泛化到其他各種領域、具有足夠的智能廣度——在上述某國內大模型公司的技術人士看來,只有同時突破智能的深度、廣度,才能稱之爲 AGI。他對此感到樂觀,「就像你們班來了一個轉校生,你沒跟他接觸過,但他考試數學和編程都考了全班第一。你覺得他語文和英語會很差嗎?」
對於國內的大模型公司來說,核心的問題還是如何追趕 o3。從訓練架構、數據、訓練方法和評價數據集等關鍵要素來看,這似乎是工程化能解決的問題。
「你認爲距離我們擁有一個 o3 水平的開源模型還有多遠?」
「一年之後。」上述模型負責人回答。
模型只是發動機,關鍵是幫助開發者用起來
儘管 o3 的模型能力很強,但在一些應用層人士看來,模型和落地應用之間還有很大距離。「今天 OpenAI 訓練了愛因斯坦,但如果想變成上市公司的首席科學家,依然是有距離的。」瀾碼科技創始人兼 CEO 周健對極客公園表示。
作爲大模型中間層,瀾碼科技是國內較早探索將大模型應用落地、打造 AI Agent 的公司。在周健看來,大模型只是一個基礎設施,需要結合場景去做很多工作才能用起來,而目前主要的掣肘是數據。
在很多場景裏,拿到完整數據是很難的,有很多數據甚至是沒有數字化的。比如獵頭可能需要簡歷數據,但很多簡歷數據並沒有被數字化。
而成本是影響 o 系列模型落地的最關鍵因素。根據 ARC-AGI 測試標準,o3-low(低計算量模式)每個任務耗費 20 美金,o3-high(高計算量模式)每個任務耗費數千美金——哪怕問一個最簡單的問題,也要花費近兩萬元。收益和成本根本不能打平,o3 的落地可能還需要漫長一段時間。
![bigjpg]() o 系列模型的成本測算 | 圖片來源:ARC-AGI 測試標準
o 系列模型的成本測算 | 圖片來源:ARC-AGI 測試標準在幫助模型應用落地的問題上,OpenAI 在發佈會上也發佈了相應的功能方案。比如第二天,OpenAI 專爲開發者發佈了 AI 強化微調(AI Reinforcement Fine-Tuning)功能,這是周健最關心的功能。它指的是,模型能通過少量數據,優化推理能力、提升性能。
這尤其適用於精細化領域的應用。OpenAI 技術人士稱,它能幫助任何需要在 AI 模型方面擁有深厚專業知識的領域,比如法律、金融、工程、保險。一個例子是,最近湯森路透使用強化微調來微調 o1-mini,得到了好用的 AI 法律助理,幫助他們的法律專業人員完成了一些「最具分析性的工作流程」。
比如第九天,o1 模型終於向開發者開放使用。它支持函數調用和視覺能力;引入了 WebRTC,實現實時語音應用開發;推出了偏好微調功能,幫助開發者定製模型;發佈了 Go 和 JAVA SDK,讓開發者可快速上手集成。
同時,它帶來了更低成本、更高質量的 4o 語音模型。其中,4o 音頻價格下調 60%,降至輸入 $40/百萬 tokens、輸出 $80/百萬 tokens,緩存音頻價格降低 87.5%、至 $2.50/百萬 tokens;對於預算有限的開發者,OpenAI 推出 GPT-4o mini,音頻費用僅爲 4o 的四分之一。
這個新功能也是周健關注的。他認爲,更新的實時語音、視覺識別等功能,將能更好地在營銷、電話客服和銷售外呼等場景應用。按他的經驗,當 OpenAI 推出某些領先技術,一般國內 6-12 個月就可以追上。這讓他對新一年的應用業務充滿信心。
Sora 的視頻生成低於預期,但產品開放會提升其物理模擬能力
年初 OpenAI 發佈 Sora 的 demo 時,引發了全球科技圈的震撼。但這一整年,國內各大模型公司紛紛競逐文生視頻賽道——等到 OpenAI 在發佈會第三天正式放出 Sora 時,國內的文生視頻公司鬆了一口氣。
「基本沒有什麼超出預期的內容,真實感、物理特性等方面相比於 2 月份的發佈並沒有顯著變化,從基礎模型能力的層面來說算是低於預期的。」生數科技聯合創始人兼 CEO 唐家渝對極客公園表示。
目前,字節、快手、MiniMax、智譜、生數、愛詩等公司均推出了自己的文生視頻產品。「Sora 的效果和實力綜合來看並無明顯領先優勢,我們看到自己與OpenAI確實還是齊頭並進的。」唐家渝表示。
在他看來,Sora 稍微有亮點的部分是在基礎的文生視頻、圖生視頻以外,提供了一些提升視頻創作體驗的編輯功能,說明 OpenAI 確實更關注產品體驗了。
比如故事板功能,它相當於按時間軸的方式,把一段故事(視頻)切成了多個不同的故事卡(視頻幀)。用戶只需要設計和調整每張故事卡(視頻幀),Sora 會自動把它們補成一段流暢的故事(視頻)——這很像電影裏的分鏡、動畫的手稿,當導演畫好分鏡、漫畫師寫好手稿、一個動畫、片子就做好了。它能讓創作者更好地表達自己。
此外,它還推出了文字直接修改視頻、無縫融合兩段不同的視頻、給視頻改變畫風等功能,它們相當於是直接給視頻加「特效」了。而一般的文生視頻產品,無法直接修改原視頻,只能不斷調整 prompt(提示詞)、生成新視頻。
![bigjpg]() Sora 的故事板功能 | 圖片來源:OpenAI
Sora 的故事板功能 | 圖片來源:OpenAI在唐家渝看來,這些功能設計確實都是爲了給創作者更大的創作自由度,類似的功能已經在 Vidu(生數科技的文生視頻產品)迭代的計劃中。「Sora 這些功能的實現對於我們來說並沒有難度,實現路徑也已經非常明確了。」他說。
在發佈會上,Sam Altman 闡釋了做 Sora 的原因:一是工具性價值,爲創意人員提供創作工具;二是交互價值,大模型不應只通過文本交互,也應擴展多模態;三是最重要的——它和 AGI 技術願景是一致的,Sora 在學習更多關於世界的規律,最終有可能建立理解物理規律的「世界模型」。
在唐家渝看來,目前 Sora 生成的視頻中,依然有不少明顯違揹物理定律的地方,跟 2 月的 demo 相比進步不大。在他看來,Sora 發佈後、會有更多人來嘗試和探索它的物理模擬能力,這些測試樣本或許對提升它的物理模擬起到一定的指導作用。
內加功能、外接生態,ChatGPT 能變成 Super App 嗎?
在 o 系列模型、Sora、以及開發者服務之外,OpenAI 在發佈會上的主要動作,一方面還是在產品側持續增加新功能,優化用戶體驗。另一方面是積極推動與蘋果等企業的深度合作,探索 AI 融入終端設備和操作系統。
從前者可以看到,ChatGPT 的演進方向,似乎是要成爲一個「無所不能、無所不在、人人可得」的超級 AI 助理。據極客公園了解,OpenAI 創立之初的願景就是打造一個「無所不能」的 Agent,它能理解人類的指令、自動調用不同的工具、滿足人類的需要。看起來,終點即起點。
比如第六天,ChatGPT 增加了支持屏幕共享的視頻通話和聖誕老人語音模式。前者讓用戶能與 AI 實時視頻通話,分享屏幕或展示周圍環境,進行多模態互動,復現了電影《Her》的場景。
比如第八天,ChatGPT 向全體用戶開放了其搜索功能。在基礎搜索外,它還增加了語音搜索;同時,它集成了手機設備的地圖服務,能調取蘋果、谷歌地圖展示搜索結果列表;它還與多家頂級新聞和數據提供商建立了合作關係,支持用戶查看股票行情、體育賽事得分、天氣預報等信息。
又比如第十一天,ChatGPT 宣佈擴展了與桌面軟體的集成。它能接入更多編碼應用程序,如 BBEdit、MatLab、Nova、Script Editor 等;它能和 Warp(文件共享應用)、XCode 編輯器等應用一起使用;它還能在語音模式下與其他應用程序協同工作,包括 NOTION、Apple Notes 等;
現場演示有這樣一個例子,當用戶在 Apple Notes 中設定「節日派對歌單」,並語音徵詢 ChatGPT 對候選歌曲的意見。ChatGPT 能指出用戶的錯誤,如將聖誕歌曲《Frosty the Snowman》誤寫爲《Freezy the Snowman》。
![bigjpg]() ChatGPT 指出了 Apple Notes 的錯誤 | 圖片來源:OpenAI
ChatGPT 指出了 Apple Notes 的錯誤 | 圖片來源:OpenAI「ChatGPT 會從單純的會話助手向更爲強大的代理工具轉變。」OpenAI 首席產品官凱文·韋爾(Kevin Weil)稱。
而另一方面,OpenAI 也在積極擴張生態,通過融入人們最常用的終端設備、操作系統、上層軟體等,觸達更廣泛人群。
比如第五天,ChatGPT 宣佈集成蘋果智能生態,融入 iOS、MacOS 和 iPadOS,支持用戶跨平台、跨應用調用 AI 能力,包括 Siri 交互、寫作工具(Writing Tools),以及視覺功能智能識別場景內容(Visual Intelligence)等。通過這次合作,ChatGPT 觸達了全球數十億蘋果用戶。它也開啓了大模型與端側、操作系統合作的先例。
比如第十天,ChatGPT 公佈了自己的電話聯繫方式(1-800-242-8478),美國用戶每月可撥打該號碼享受 15 分鐘的免費通話。同時上線的還有 WhatsApp 聯繫人(1-800-242-8478),全球任何用戶均可通過 WhatsApp 向該號碼發送消息,目前只限文字信息。
![bigjpg]() ChatGPT 公佈了自己的電話聯繫方式 | 圖片來源:OpenAI
ChatGPT 公佈了自己的電話聯繫方式 | 圖片來源:OpenAI全球部分國家、地區的智能手機和移動互聯網滲透率還遠遠不足,通過電話這種最基礎的通訊工具,ChatGPT 觸達了這些人群。同時它也通過 WhatsApp,觸達了其近 30 億用戶。
無論是內加功能、還是外接生態,ChatGPT 核心是希望產品觸達更廣泛人群,變成真正的 Super APP。但也有人並不看好它這種不斷內加功能、將業務線拉得無盡長的做法,甚至將其形容爲「鋪了一個大餅,但每一塊餅都有點薄,深入不下去」。而很多業務都需要足夠深才能發揮價值、也有對應的公司在深耕,這或許是 OpenAI 要面臨的挑戰。
儘管 o3 模型讓外界看到了 OpenAI 驚人的技術實力,但關於推理的 Scaling Law 能達到怎樣的智能上限、以及 GPT-5 的難產問題,依然讓外界對這家公司的技術發展充滿疑慮。這次發佈會上,OpenAI 將關注點轉而放在產品形態、合作生態和落地建設上,也未嘗不是一種思路。這兩者的結合,可能決定了行業接下來的走向。
編輯/rice





