
前OpenAI联合创始人、SSI创始人Ilya Sutskever发表演讲时表示,预训练作为 AI 模型开发的第一阶段即将结束。未来AI发展将聚焦于智能体、合成数据和推理时间计算。他详细解释了这三个方向的巨大潜力,例如,合成数据可以突破真实数据量的限制,而推理时间计算则可以提升AI的效率和可控性。
北京时间14日,在NeurIPS 2024大会上,前OpenAI联合创始人、SSI创始人Ilya Sutskever发表演讲时表示,预训练作为AI模型开发的第一阶段即将结束。
他将数据比作AI发展的燃料,指出由于我们只有一个互联网,数据增长已经触顶,AI即将进入“后石油时代”,而这,意味着依赖于海量数据的预训练模型将难以为继,AI发展亟待新的突破。
 Ilya认为,未来AI发展将聚焦于智能体、合成数据和推理时间计算。他详细解释了这三个方向的巨大潜力,例如,合成数据可以突破真实数据量的限制,而推理时间计算则可以提升AI的效率和可控性。
Ilya认为,未来AI发展将聚焦于智能体、合成数据和推理时间计算。他详细解释了这三个方向的巨大潜力,例如,合成数据可以突破真实数据量的限制,而推理时间计算则可以提升AI的效率和可控性。
Sutskever还认为,未来的 AI 系统将具备推理能力,不再仅依赖于模式匹配,并且自我意识将在人工智能系统中出现。
进一步,Ilya还深入探讨了未来的超级智能。他认为,超级智能将具备能动性、推理能力和自我意识,其行为将难以预测,呼吁业界为超级智能的到来做好准备。
要点如下:
预训练时代即将结束:数据是有限的,如同 AI 的化石燃料,我们已经达到了峰值,预训练之后的未来方向包括智能体、合成数据和推理时间计算等。
超级智能将是推理的时代:超级智能将具备真正的能动性,强大的推理能力,以及从有限数据中学习和理解的能力。
超级智能将是不可预测的未来:这与我们习惯的,基于人类直觉的深度学习截然不同,将带来全新的机遇和挑战。
Sutskever:预训练时代落幕,AI模型转向“代理性”
Sutskever指出,预训练作为AI模型开发的第一阶段即将结束。这一阶段依赖于从大量未标记数据中学习模式,而这些数据通常来自互联网、书籍等来源。
Sutskever提到,现有的数据资源已经达到峰值,未来的模型必须在有限的数据中寻找新的发展方式:
“我们的数据已经达到峰值,不会再有更多了。我们必须处理我们拥有的数据。互联网只有一个。”
今年11月,他在接受媒体采访时表态称,大模型预训练效果正趋于平缓:
"2010年代是扩展的时代,现在我们再次回到了探索和发现的时代。每个人都在寻找下一个突。扩展正确的东西比以往任何时候都更重要。”
Sutskever还预言,下一代AI模型将具有真正的“代理性”,能够自主执行任务、做出决策,并与软件交互。

他还表示,SSI正在研究一种替代预训练扩展的方法,但是没有透露更多细节。
AI自我意识或将诞生
Sutskever还预言未来的AI系统将具备推理能力,不再仅依赖于模式匹配,并且自我意识将在人工智能系统中出现。
根据Sutskever的说法,系统推理得越多,“它就越不可预测”。他与高级AI在国际象棋中的表现进行了比较:
“它们会从有限的数据中理解事物。它们不会感到困惑。”
Sutskever还将AI系统的规模与进化生物学进行了比较。他引用了显示不同物种大脑与体重关系的研究,指出人类祖先在这一比例上显示出与其他哺乳动物不同的斜率。
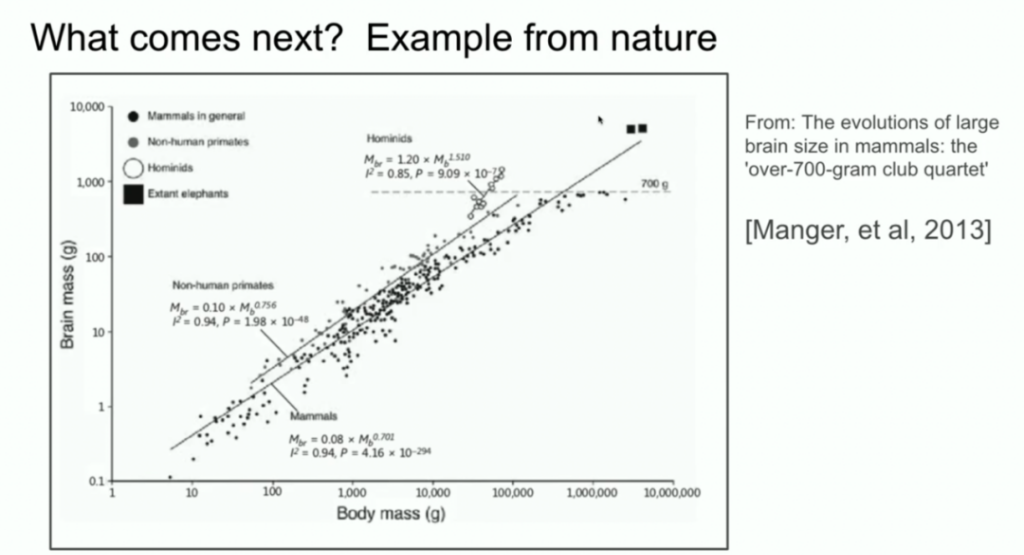
他建议,AI可能会发现类似的扩展路径,超越当前的预训练工作方式。
Sutskever:AI发展方向需要自上而下的监管
当被问及如何为人类创造合适的激励机制以确保AI的发展方向时,Sutskever称,这需要“自上而下的政府结构”,并未给出明确的答案。
“我觉得从某种意义上说,这些是人们应该更多地思考的问题。但我对回答这样的问题没有信心。”
他表示,如果AI最终选择与人类共存,并拥有权利,也许是可行的,尽管他对未来的不可预测性持谨慎态度。
以下为演讲全文:
Ilya Sutskever:
我首先要感谢组织者选择我们的论文给予支持,这真是太棒了。同时,我还要感谢我的杰出合作者 Oriol Vignales 和 Kwokli,他们刚才还站在你们面前。
现在你们看到的是一张截图,来自 10 年前,2014 年在蒙特利尔的 NeurIPS 会议上我做的类似演讲。那时我们还很天真。照片上是当时的我们(“之前”)。
这是现在的我们(“之后”)。现在,我希望我看起来更成熟,更有经验。
今天我想谈谈这项工作本身,并进行一个 10 年的回顾。因为这项工作中有很多观点是正确的,但也有一些不太正确。我们可以回顾一下,看看发生了什么,以及它是如何逐渐演变成今天的样子的。
我们先来回顾一下我们当时做了什么。我会展示 10 年前那次演讲的幻灯片。总的来说,我们做了以下三件事:
• 构建了一个基于文本训练的自回归模型
• 使用了一个大型神经网络
• 使用了大型数据集
就这么简单。现在我们深入探讨一下细节。
深度学习的假设
这是 10 年前的幻灯片,还不错吧?上面写着“深度学习的假设”。我们当时认为,如果有一个大型神经网络,它包含很多层,那么它就能在不到一秒的时间内完成人类可以完成的任何事情。为什么我们要强调人类在一秒内可以完成的事情?
这是因为,如果你相信深度学习的“教条”,认为人工神经元和生物神经元是相似的,或者至少没有太大的不同,并且你相信神经元是缓慢的,那么任何人类能够快速完成的事情,只要世界上有一个人能够在一秒内完成,那么一个 10 层的神经网络也能做到。逻辑是这样的:你只需要提取他们的连接方式,然后将其嵌入到你的人工神经网络中。
这就是动机。任何人类在一秒内可以完成的事情,一个大型 10 层神经网络都可以做到。我们当时关注 10 层神经网络,是因为那时我们只知道如何训练 10 层的网络。如果层数能更多,也许能做更多事情。但当时我们只能做到 10 层,所以我们强调的是人类在一秒内能完成的事情。
核心思想:自回归模型
这是当时演讲的另一张幻灯片,上面写着“我们的核心思想”。你可能认出来至少一个东西:这里正在发生自回归的过程。这张幻灯片到底在说什么?它在说,如果你有一个自回归模型,它能很好地预测下一个 token,那么它实际上会捕获、抓住下一个序列的正确分布。
这在当时是一个相对较新的想法。这并不是第一个自回归神经网络。
但我认为,这是第一个我们真正相信,如果训练得足够好,就能得到任何想要的结果的自回归神经网络。在当时,我们的目标是(现在看来很平常,但当时非常大胆)机器翻译。
LSTM:Transformer 之前的技术
接下来我要展示一些你们很多人可能从未见过的古老历史:LSTM。对于不熟悉的人来说,LSTM 是在 Transformer 出现之前,可怜的深度学习研究人员使用的东西。它基本上是一个旋转了 90 度的 ResNet。你可以看到它集成了残差连接(现在被称为残差流),但也有一些乘法运算。它比 ResNet 稍微复杂一点。这就是我们当时用的。
并行计算:管道并行
另一个我想强调的特点是并行计算。我们使用了管道并行,每个 GPU 处理一层。使用管道并行明智吗?现在看来,管道并行并不明智。但我们当时没那么聪明。通过使用 8 个 GPU,我们获得了 3.5 倍的速度提升。
结论:规模化假设
可以说是最重要的幻灯片,因为它阐述了规模化假设的开端:如果你有非常大的数据集,并且训练非常大的神经网络,那么成功就是必然的。如果你愿意往好的方面想,可以说,这确实就是之后发生的事情。
核心理念:连接主义
我还想提一个理念,我认为这个理念经受住了时间的考验。这就是连接主义。核心理念是:
如果你相信人工神经元有点像生物神经元,那么你就有信心相信大型神经网络(即使它们不完全像人类大脑那么大)可以被配置来完成我们人类所做的大部分事情。当然还是有差异,因为人类大脑会自我重构,而我们现在最好的学习算法需要大量的数据。人类在这方面仍然更胜一筹。
预训练时代
我认为所有这些都引领了预训练时代的到来。GPT-2 模型、GPT-3 模型、缩放法则,我要特别感谢我的前合作者:Alec Radford、Gerrit Kaplan 和 Daria Amodei,他们的工作至关重要。预训练是今天我们看到所有进步的驱动力。超大型神经网络,在海量数据集上训练。
预训练的终结,但预训练终将结束。为什么?因为虽然算力在不断增长,但数据并没有无限增长,因为我们只有一个互联网。你甚至可以说,数据是人工智能的化石燃料。它被创造出来,我们使用它,并且已经达到了数据峰值,不会有更多的数据了。我们只能处理现有的数据。尽管我们还有很多路要走,但我们只有一个互联网。
下一步是什么?
接下来我将稍微推测一下未来会发生什么。当然,很多人都在推测。你可能听说过“智能体”(agents)这个词。人们觉得智能体是未来。更具体一点,但也有点模糊的是合成数据。如何生成有用的合成数据仍然是一个巨大的挑战。还有推理时的算力优化,以及最近在 o1 模型中看到的,这些都是人们在预训练之后尝试探索的方向。
生物学启示:不同物种的大脑缩放
我还想提一个生物学的例子,我觉得非常有趣。多年前,我也在这个会议上看到一个演讲,演讲者展示了一个图表,显示哺乳动物的身体大小和大脑大小之间的关系。演讲者说,在生物学中,一切都很混乱,但这里有一个特例,即动物的身体大小和大脑大小之间存在紧密的关系。
我当时对这个图表产生了好奇,并开始在谷歌上搜索。其中一个图片结果是这样的:你可以看到各种哺乳动物,非人类灵长类动物也是如此。但接下来是人科动物,如尼安德特人,他们和人类的进化关系很近。有趣的是,人科动物的脑体缩放指数具有不同的斜率。
这意味着,生物学中存在一个例子,它展示了某种不同的缩放方式。这很酷。另外,我要强调一下,x 轴是对数刻度。所以,事物是有可能不同的。我们目前所做的事情,是我们第一个知道如何进行缩放的事情。毫无疑问,这个领域的所有人都会找到下一步的方向。
关于未来的推测
现在我想花几分钟推测一下更长远的未来,我们都将走向何方?我们正在取得进步,这真是太棒了。如果你是 10 年前就入行的,你会记得当时的技术有多么不成熟。即便你觉得深度学习是理所当然的,但亲眼看到它取得的进步还是令人难以置信。我无法向那些最近两年才加入这个领域的人传达这种感觉。但我要谈谈超级智能,因为这显然是这个领域的未来。
超级智能在性质上将与我们今天拥有的智能截然不同。我希望在接下来的几分钟里,给你一些具体的直觉,让你感受到这种不同。
现在我们拥有了强大的语言模型,它们是很棒的聊天机器人,它们甚至能做一些事情,但它们也常常不可靠,有时会感到困惑,同时在某些任务上又具有超人的表现。如何协调这种矛盾目前还不清楚。
但最终,以下情况将会发生:
这些系统将真正具有智能体的性质。而现在,它们在任何有意义的层面上都不是智能体,或者说只有非常微弱的智能体性质。它们会进行真正的推理。
我还要强调一点,关于推理:
一个系统越能进行推理,就变得越不可预测。我们现在使用的模型都是可预测的,因为我们一直在努力复制人类的直觉。我们大脑在一秒钟内的反应,本质上就是直觉。所以我们用一些直觉训练了模型。但推理是不可预测的。原因之一是,好的国际象棋 AI 对人类国际象棋高手来说是不可预测的。
所以,我们将来要处理的 AI 系统将是高度不可预测的。它们会理解有限的数据,它们不会感到困惑,这是它们目前存在的巨大局限。我不是说如何做到,也不是说何时做到,我只是说它将会发生。当所有这些能力都与自我意识相结合时(为什么不呢?自我意识是有用的),我们将拥有与今天截然不同的系统。它们将拥有令人难以置信的能力。但与这些系统相关的问题将与我们过去习惯的问题大相径庭。
预测未来是不可能的,一切皆有可能。但最后,我还是要以乐观的态度结束我的演讲。
以下为问答环节实录:
• 问题1: 在 2024 年,是否有其他生物结构在人类认知中发挥作用,您认为值得像您之前那样去探索?
• 回答: 如果有人对大脑的运作方式有独特的见解,并且认为我们目前的做法是愚蠢的,他们应该去探索它。我个人没有这样的想法。也许从更高的抽象层面来看,我们可以说,生物学启发的人工智能是非常成功的,因为所有的神经网络都是受生物启发的,尽管其灵感非常有限,比如我们只是使用了神经元。更详细的生物灵感很难找到。但如果有特别的见解,也许可以找到有用的方向。
• 问题2: 您提到推理是未来模型的核心方面。我们看到现在模型中存在幻觉。我们使用统计分析来判断模型是否产生幻觉。未来,具有推理能力的模型能否自我纠正,减少幻觉?
• 回答: 我认为你描述的情况是极有可能发生的。事实上,有些早期的推理模型可能已经开始具备这种能力了。长期来看,为什么不能呢?这就像微软 Word 中的自动更正功能。当然,这种功能比自动更正要强大得多。但总的来说,答案是肯定的。
• 问题3: 如果这些新诞生的智能体需要权利,我们应该如何为人类建立正确的激励机制,以确保它们能像人类一样获得自由?
• 回答: 这是一个值得人们思考的问题。但是我不觉得我有能力回答这个问题。因为这涉及到建立某种自上而下的结构,或者政府之类的东西。我不是这方面的专家。也许可以用加密货币之类的东西。如果 AI 只是想与我们共存,并且也想要获得权利,也许这样就挺好。但我认为未来太不可预测了,我不敢轻易评论。但我鼓励大家思考这个问题。
• 问题4: 您认为大型语言模型(LLM)是否能够进行多跳推理的跨分布泛化?
• 回答: 这个问题假设答案是肯定的或者否定的。但这个问题不应该用“是”或“否”来回答,因为“跨分布泛化”是什么意思?“分布内”又是什么意思?在深度学习之前,人们使用字符串匹配、n-gram 等技术进行机器翻译。当时,“泛化”意味着,是否使用完全不在数据集中的短语?现在,我们的标准已经大幅提高。我们可能会说,一个模型在数学竞赛中取得了高分,但也许它只是记住了互联网论坛上讨论过的相同想法。所以,也许它是在分布内,也许只是记忆。我认为人类的泛化能力要好得多,但现在的模型在某种程度上也能够做到。这是一个更合理的答案。
编辑/new
