

前OpenAI聯合創始人、SSI創始人Ilya Sutskever發表演講時表示,預訓練作爲 AI 模型開發的第一階段即將結束。未來AI發展將聚焦於智能體、合成數據和推理時間計算。他詳細解釋了這三個方向的巨大潛力,例如,合成數據可以突破真實數據量的限制,而推理時間計算則可以提升AI的效率和可控性。
北京時間14日,在NeurIPS 2024大會上,前OpenAI聯合創始人、SSI創始人Ilya Sutskever發表演講時表示,預訓練作爲AI模型開發的第一階段即將結束。
他將數據比作AI發展的燃料,指出由於我們只有一個互聯網,數據增長已經觸頂,AI即將進入「後石油時代」,而這,意味着依賴於海量數據的預訓練模型將難以爲繼,AI發展亟待新的突破。
 Ilya認爲,未來AI發展將聚焦於智能體、合成數據和推理時間計算。他詳細解釋了這三個方向的巨大潛力,例如,合成數據可以突破真實數據量的限制,而推理時間計算則可以提升AI的效率和可控性。
Ilya認爲,未來AI發展將聚焦於智能體、合成數據和推理時間計算。他詳細解釋了這三個方向的巨大潛力,例如,合成數據可以突破真實數據量的限制,而推理時間計算則可以提升AI的效率和可控性。
Sutskever還認爲,未來的 AI 系統將具備推理能力,不再僅依賴於模式匹配,並且自我意識將在人工智能系統中出現。
進一步,Ilya還深入探討了未來的超級智能。他認爲,超級智能將具備能動性、推理能力和自我意識,其行爲將難以預測,呼籲業界爲超級智能的到來做好準備。
要點如下:
預訓練時代即將結束:數據是有限的,如同 AI 的化石燃料,我們已經達到了峯值,預訓練之後的未來方向包括智能體、合成數據和推理時間計算等。
超級智能將是推理的時代:超級智能將具備真正的能動性,強大的推理能力,以及從有限數據中學習和理解的能力。
超級智能將是不可預測的未來:這與我們習慣的,基於人類直覺的深度學習截然不同,將帶來全新的機遇和挑戰。
Sutskever:預訓練時代落幕,AI模型轉向「代理性」
Sutskever指出,預訓練作爲AI模型開發的第一階段即將結束。這一階段依賴於從大量未標記數據中學習模式,而這些數據通常來自互聯網、書籍等來源。
Sutskever提到,現有的數據資源已經達到峯值,未來的模型必須在有限的數據中尋找新的發展方式:
「我們的數據已經達到峯值,不會再有更多了。我們必須處理我們擁有的數據。互聯網只有一個。」
今年11月,他在接受媒體採訪時表態稱,大模型預訓練效果正趨於平緩:
"2010年代是擴展的時代,現在我們再次回到了探索和發現的時代。每個人都在尋找下一個突。擴展正確的東西比以往任何時候都更重要。”
Sutskever還預言,下一代AI模型將具有真正的「代理性」,能夠自主執行任務、做出決策,並與軟件交互。

他還表示,SSI正在研究一種替代預訓練擴展的方法,但是沒有透露更多細節。
AI自我意識或將誕生
Sutskever還預言未來的AI系統將具備推理能力,不再僅依賴於模式匹配,並且自我意識將在人工智能系統中出現。
根據Sutskever的說法,系統推理得越多,「它就越不可預測」。他與高級AI在國際象棋中的表現進行了比較:
「它們會從有限的數據中理解事物。它們不會感到困惑。」
Sutskever還將AI系統的規模與進化生物學進行了比較。他引用了顯示不同物種大腦與體重關係的研究,指出人類祖先在這一比例上顯示出與其他哺乳動物不同的斜率。
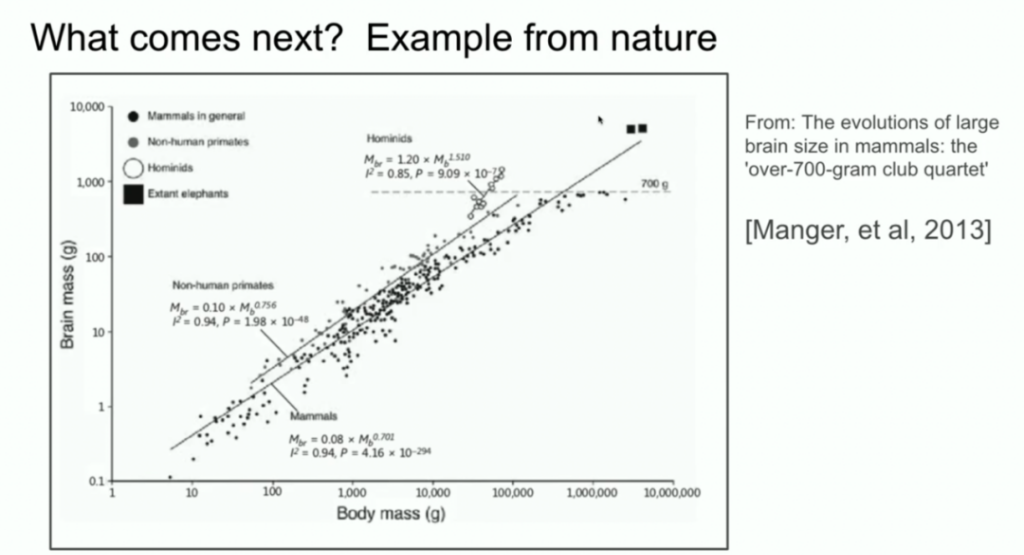
他建議,AI可能會發現類似的擴展路徑,超越當前的預訓練工作方式。
Sutskever:AI發展方向需要自上而下的監管
當被問及如何爲人類創造合適的激勵機制以確保AI的發展方向時,Sutskever稱,這需要「自上而下的政府結構」,並未給出明確的答案。
「我覺得從某種意義上說,這些是人們應該更多地思考的問題。但我對回答這樣的問題沒有信心。」
他表示,如果AI最終選擇與人類共存,並擁有權利,也許是可行的,儘管他對未來的不可預測性持謹慎態度。
以下爲演講全文:
Ilya Sutskever:
我首先要感謝組織者選擇我們的論文給予支持,這真是太棒了。同時,我還要感謝我的傑出合作者 Oriol Vignales 和 Kwokli,他們剛才還站在你們面前。
現在你們看到的是一張截圖,來自 10 年前,2014 年在蒙特利爾的 NeurIPS 會議上我做的類似演講。那時我們還很天真。照片上是當時的我們(「之前」)。
這是現在的我們(「之後」)。現在,我希望我看起來更成熟,更有經驗。
今天我想談談這項工作本身,並進行一個 10 年的回顧。因爲這項工作中有很多觀點是正確的,但也有一些不太正確。我們可以回顧一下,看看發生了什麼,以及它是如何逐漸演變成今天的樣子的。
我們先來回顧一下我們當時做了什麼。我會展示 10 年前那次演講的幻燈片。總的來說,我們做了以下三件事:
• 構建了一個基於文本訓練的自回歸模型
• 使用了一個大型神經網絡
• 使用了大型數據集
就這麼簡單。現在我們深入探討一下細節。
深度學習的假設
這是 10 年前的幻燈片,還不錯吧?上面寫着「深度學習的假設」。我們當時認爲,如果有一個大型神經網絡,它包含很多層,那麼它就能在不到一秒的時間內完成人類可以完成的任何事情。爲什麼我們要強調人類在一秒內可以完成的事情?
這是因爲,如果你相信深度學習的「教條」,認爲人工神經元和生物神經元是相似的,或者至少沒有太大的不同,並且你相信神經元是緩慢的,那麼任何人類能夠快速完成的事情,只要世界上有一個人能夠在一秒內完成,那麼一個 10 層的神經網絡也能做到。邏輯是這樣的:你只需要提取他們的連接方式,然後將其嵌入到你的人工神經網絡中。
這就是動機。任何人類在一秒內可以完成的事情,一個大型 10 層神經網絡都可以做到。我們當時關注 10 層神經網絡,是因爲那時我們只知道如何訓練 10 層的網絡。如果層數能更多,也許能做更多事情。但當時我們只能做到 10 層,所以我們強調的是人類在一秒內能完成的事情。
核心思想:自回歸模型
這是當時演講的另一張幻燈片,上面寫着「我們的核心思想」。你可能認出來至少一個東西:這裏正在發生自回歸的過程。這張幻燈片到底在說什麼?它在說,如果你有一個自回歸模型,它能很好地預測下一個 token,那麼它實際上會捕獲、抓住下一個序列的正確分佈。
這在當時是一個相對較新的想法。這並不是第一個自回歸神經網絡。
但我認爲,這是第一個我們真正相信,如果訓練得足夠好,就能得到任何想要的結果的自回歸神經網絡。在當時,我們的目標是(現在看來很平常,但當時非常大膽)機器翻譯。
LSTM:Transformer 之前的技術
接下來我要展示一些你們很多人可能從未見過的古老歷史:LSTM。對於不熟悉的人來說,LSTM 是在 Transformer 出現之前,可憐的深度學習研究人員使用的東西。它基本上是一個旋轉了 90 度的 ResNet。你可以看到它集成了殘差連接(現在被稱爲殘差流),但也有一些乘法運算。它比 ResNet 稍微複雜一點。這就是我們當時用的。
並行計算:管道並行
另一個我想強調的特點是並行計算。我們使用了管道並行,每個 GPU 處理一層。使用管道並行明智嗎?現在看來,管道並行並不明智。但我們當時沒那麼聰明。通過使用 8 個 GPU,我們獲得了 3.5 倍的速度提升。
結論:規模化假設
可以說是最重要的幻燈片,因爲它闡述了規模化假設的開端:如果你有非常大的數據集,並且訓練非常大的神經網絡,那麼成功就是必然的。如果你願意往好的方面想,可以說,這確實就是之後發生的事情。
核心理念:連接主義
我還想提一個理念,我認爲這個理念經受住了時間的考驗。這就是連接主義。核心理念是:
如果你相信人工神經元有點像生物神經元,那麼你就有信心相信大型神經網絡(即使它們不完全像人類大腦那麼大)可以被配置來完成我們人類所做的大部分事情。當然還是有差異,因爲人類大腦會自我重構,而我們現在最好的學習算法需要大量的數據。人類在這方面仍然更勝一籌。
預訓練時代
我認爲所有這些都引領了預訓練時代的到來。GPT-2 模型、GPT-3 模型、縮放法則,我要特別感謝我的前合作者:Alec Radford、Gerrit Kaplan 和 Daria Amodei,他們的工作至關重要。預訓練是今天我們看到所有進步的驅動力。超大型神經網絡,在海量數據集上訓練。
預訓練的終結,但預訓練終將結束。爲什麼?因爲雖然算力在不斷增長,但數據並沒有無限增長,因爲我們只有一個互聯網。你甚至可以說,數據是人工智能的化石燃料。它被創造出來,我們使用它,並且已經達到了數據峯值,不會有更多的數據了。我們只能處理現有的數據。儘管我們還有很多路要走,但我們只有一個互聯網。
下一步是什麼?
接下來我將稍微推測一下未來會發生什麼。當然,很多人都在推測。你可能聽說過「智能體」(agents)這個詞。人們覺得智能體是未來。更具體一點,但也有點模糊的是合成數據。如何生成有用的合成數據仍然是一個巨大的挑戰。還有推理時的算力優化,以及最近在 o1 模型中看到的,這些都是人們在預訓練之後嘗試探索的方向。
生物學啓示:不同物種的大腦縮放
我還想提一個生物學的例子,我覺得非常有趣。多年前,我也在這個會議上看到一個演講,演講者展示了一個圖表,顯示哺乳動物的身體大小和大腦大小之間的關係。演講者說,在生物學中,一切都很混亂,但這裏有一個特例,即動物的身體大小和大腦大小之間存在緊密的關係。
我當時對這個圖表產生了好奇,並開始在谷歌上搜索。其中一個圖片結果是這樣的:你可以看到各種哺乳動物,非人類靈長類動物也是如此。但接下來是人科動物,如尼安德特人,他們和人類的進化關係很近。有趣的是,人科動物的腦體縮放指數具有不同的斜率。
這意味着,生物學中存在一個例子,它展示了某種不同的縮放方式。這很酷。另外,我要強調一下,x 軸是對數刻度。所以,事物是有可能不同的。我們目前所做的事情,是我們第一個知道如何進行縮放的事情。毫無疑問,這個領域的所有人都會找到下一步的方向。
關於未來的推測
現在我想花幾分鐘推測一下更長遠的未來,我們都將走向何方?我們正在取得進步,這真是太棒了。如果你是 10 年前就入行的,你會記得當時的技術有多麼不成熟。即便你覺得深度學習是理所當然的,但親眼看到它取得的進步還是令人難以置信。我無法向那些最近兩年才加入這個領域的人傳達這種感覺。但我要談談超級智能,因爲這顯然是這個領域的未來。
超級智能在性質上將與我們今天擁有的智能截然不同。我希望在接下來的幾分鐘裏,給你一些具體的直覺,讓你感受到這種不同。
現在我們擁有了強大的語言模型,它們是很棒的聊天機器人,它們甚至能做一些事情,但它們也常常不可靠,有時會感到困惑,同時在某些任務上又具有超人的表現。如何協調這種矛盾目前還不清楚。
但最終,以下情況將會發生:
這些系統將真正具有智能體的性質。而現在,它們在任何有意義的層面上都不是智能體,或者說只有非常微弱的智能體性質。它們會進行真正的推理。
我還要強調一點,關於推理:
一個系統越能進行推理,就變得越不可預測。我們現在使用的模型都是可預測的,因爲我們一直在努力複製人類的直覺。我們大腦在一秒鐘內的反應,本質上就是直覺。所以我們用一些直覺訓練了模型。但推理是不可預測的。原因之一是,好的國際象棋 AI 對人類國際象棋高手來說是不可預測的。
所以,我們將來要處理的 AI 系統將是高度不可預測的。它們會理解有限的數據,它們不會感到困惑,這是它們目前存在的巨大侷限。我不是說如何做到,也不是說何時做到,我只是說它將會發生。當所有這些能力都與自我意識相結合時(爲什麼不呢?自我意識是有用的),我們將擁有與今天截然不同的系統。它們將擁有令人難以置信的能力。但與這些系統相關的問題將與我們過去習慣的問題大相徑庭。
預測未來是不可能的,一切皆有可能。但最後,我還是要以樂觀的態度結束我的演講。
以下爲問答環節實錄:
• 問題1: 在 2024 年,是否有其他生物結構在人類認知中發揮作用,您認爲值得像您之前那樣去探索?
• 回答: 如果有人對大腦的運作方式有獨特的見解,並且認爲我們目前的做法是愚蠢的,他們應該去探索它。我個人沒有這樣的想法。也許從更高的抽象層面來看,我們可以說,生物學啓發的人工智能是非常成功的,因爲所有的神經網絡都是受生物啓發的,儘管其靈感非常有限,比如我們只是使用了神經元。更詳細的生物靈感很難找到。但如果有特別的見解,也許可以找到有用的方向。
• 問題2: 您提到推理是未來模型的核心方面。我們看到現在模型中存在幻覺。我們使用統計分析來判斷模型是否產生幻覺。未來,具有推理能力的模型能否自我糾正,減少幻覺?
• 回答: 我認爲你描述的情況是極有可能發生的。事實上,有些早期的推理模型可能已經開始具備這種能力了。長期來看,爲什麼不能呢?這就像微軟 Word 中的自動更正功能。當然,這種功能比自動更正要強大得多。但總的來說,答案是肯定的。
• 問題3: 如果這些新誕生的智能體需要權利,我們應該如何爲人類建立正確的激勵機制,以確保它們能像人類一樣獲得自由?
• 回答: 這是一個值得人們思考的問題。但是我不覺得我有能力回答這個問題。因爲這涉及到建立某種自上而下的結構,或者政府之類的東西。我不是這方面的專家。也許可以用加密貨幣之類的東西。如果 AI 只是想與我們共存,並且也想要獲得權利,也許這樣就挺好。但我認爲未來太不可預測了,我不敢輕易評論。但我鼓勵大家思考這個問題。
• 問題4: 您認爲大型語言模型(LLM)是否能夠進行多跳推理的跨分佈泛化?
• 回答: 這個問題假設答案是肯定的或者否定的。但這個問題不應該用「是」或「否」來回答,因爲「跨分佈泛化」是什麼意思?「分佈內」又是什麼意思?在深度學習之前,人們使用字符串匹配、n-gram 等技術進行機器翻譯。當時,「泛化」意味着,是否使用完全不在數據集中的短語?現在,我們的標準已經大幅提高。我們可能會說,一個模型在數學競賽中取得了高分,但也許它只是記住了互聯網論壇上討論過的相同想法。所以,也許它是在分佈內,也許只是記憶。我認爲人類的泛化能力要好得多,但現在的模型在某種程度上也能夠做到。這是一個更合理的答案。
編輯/new
