
 海天瑞声2024年三季报显示,公司主营收入1.5亿元,同比上升44.9%;归母净利润378.87万元,同比上升111.8%;扣非净利润-193.83万元,同比上升95.44%;其中2024年第三季度,公司单季度主营收入5713.11万元,同比上升98.69%;单季度归母净利润337.23万元,同比上升122.67%;单季度扣非净利润173.75万元,同比上升108.95%;负债率5.22%,投资收益491.08万元,财务费用149.39万元,毛利率66.83%。
海天瑞声2024年三季报显示,公司主营收入1.5亿元,同比上升44.9%;归母净利润378.87万元,同比上升111.8%;扣非净利润-193.83万元,同比上升95.44%;其中2024年第三季度,公司单季度主营收入5713.11万元,同比上升98.69%;单季度归母净利润337.23万元,同比上升122.67%;单季度扣非净利润173.75万元,同比上升108.95%;负债率5.22%,投资收益491.08万元,财务费用149.39万元,毛利率66.83%。證券之星消息,2024年11月8日海天瑞聲(688787)發佈公告稱公司於2024年11月5日接受機構調研,景順長城陸哲皓、銀華基金孫蓓琳 吳文蔚 杜宇 郭磊 同穎茜 王利剛 向伊達、惠升基金管理公司陳橋寧、長盛基金楊睿琦、中郵創業基金姚婷、長城基金林皓 趙鳳飛、中信建投張詠梅參與。
具體內容如下:
問:請公司三季度收入大幅增長的原因是什麼?
答:2024年前三季度,公司收入爲1.50億元,同比增長44.90%,主要是受益於大模型技術的快速發展以及應用場景不斷落地,以智能終端廠商、科技互聯網公司等爲代表的國內外科技巨頭紛紛加大多模態數據投入以支撐其智能終端、內容生成等領域的I能力。由此帶來,以多語種、多音色爲代表的智能語音業務需求、以及以指令微調、偏好對齊爲代表的自然語言業務需求均同比呈現大幅增長,整體上驅動公司營業收入同比顯著增加。截至9月末,公司已爲近20家境內外大模型企業、科研機構,在預訓練、指令微調、偏好對齊等方面提供了訓練數據服務或標準化產品,爲後續承接更大規模的大模型領域數據需求奠定基礎。
問:公司前三季度淨利潤同比也呈現出比較好的增長,背後的原因除了收入增長外,公司是否做了其他的舉措來控制費用?
答:2024年1-9月,歸屬於上市公司股東的淨利潤爲378.87萬元,同比增長3,590.86萬元。背後的驅動因素,除了公司整體營業收入大幅增長外,前三季度具有高毛利特點的數據集產品收入佔比有所提升,驅動公司整體毛利率增加至66.83%。此外,爲進一步提升整體運營效率,公司進行了管理資源的合理配置和流程優化,使得管理費用有效降低;與此同時,公司DOTS一體化數據處理平台開發已達到階段性成熟狀態,相關投入強度呈現自然落;同時,部分賬齡較長的大額應收賬款在報告期間完成款,信用減值損失大幅降低,以上因素共同驅動公司前三季度淨利潤同比大幅增長。
問:智能終端的AI agent出來之後,對數據需求有什麼變化?
答:智能終端側的I agent將成爲繼智能駕駛之後又一個重要的I落地場景,會帶來新型的數據需求。首先,智能終端agent需要能夠處理和理解來自終端場景的多樣化數據,因此需要獲取相冊中的照片、視頻、以及短信和電子郵件內容,通過這些數據的學習,使得I agent能夠深入解讀和響應終端的文本和圖像信息。其次,爲了模擬和執行人類的操作行爲,I agent需要大量的各類應用的操作數據,來訓練其對各類操作流程的理解。此外,I agent必須能夠理解和響應各種語音輸入,這也激發了對多語種、多音色和多風格語音數據的進一步需求。針對以上I agent多樣化的數據需求,海天瑞聲均具備設計、採集、加工等數據服務能力。
問:看到公司前三季度境外收入快速增長,除了三季報裏講到的行業側的多模態大模型的驅動外,公司本身在境外做了哪些佈局和投入?
答:爲更好把握行業機遇、進一步擴大全球客戶輻射範圍,公司從體系搭建、市場研究、品牌升級、營銷推廣等多維度提升業務、客戶觸達及服務能力。前三季度,公司持續加強境外銷售團隊建設,進一步織密客戶服務網絡;同時,通過參與包括 Web Summit Qatar、ICSSP、I EXPO TOKYO、utosense and InCabin 及 CVPR 等全球知名行業及學術頂會,以及佈局搜索廣告投放、社交媒體矩陣等多類宣傳渠道等方式,向全球市場展示公司先進技術實力及創新產品,提升行業影響力和美譽度。2024年,公司全新發布海外官網,全面升級官網服務模式,通過搭建marketplace,便捷用戶目標服務/產品的選擇,有效提升新客戶拓展以及訂單轉化率。
問:前三季度,公司在大模型領域進行了哪些投入?
答:公司繼續加大大模型數據方向的研發投入,增厚大模型領域的數據儲備,已完成並持續建設包括「大語言模型中文對話預訓練數據集」、「語音大模型(聲音復刻、歌曲)微調數據集」、「語音大模型(多語種)預訓練及微調數據集」、「視覺大模型(圖像-文本)預訓練及微調數據集」、「視覺大模型(視頻-文本)預訓練及微調數據集」等在內的多領域大模型數據集。同時,針對大模型在特定行業的應用需求,公司重點開發了醫療、金融、法律、藝術等垂直領域的標註資源,形成垂直領域專家庫,爲公司提供高質量行業數據服務奠定堅實基礎。與此同時,爲更好理解大模型技術方向,公司通過前瞻性研究,探索大模型數據的規模化生產方式。公司已和清華大學聯合啓動多語種語音大模型研發計劃,該項目將基於最新的語音大模型框架技術,自研多語種數據清洗技術,訓練多個不同規模的語音大模型,有效提升多語種語音數據處理的效率和準確性。
問:三季報中有到,境內、外客戶購買了公司很多語音數據,請公司在智能語音數據方面的儲備和進展如何?
答:語音一直以來都是公司的優勢領域,公司已沉澱下深厚的語音語言學基礎研究成果,並已將其運用至構建高質量的智能語音、以及多模態訓練數據。在語音語言學基礎研究領域,公司擁有豐富的多語種語言學家團隊資源積累和多語種發音詞典積累,以及不斷創新的發音詞典構建技術和流程技術。目前,公司已經擁有超過205個語種/方言的覆蓋能力,不僅包括含英、法、德、意、西、日、韓等常見語種,還包括東南亞、一帶一路等國家地區的罕見小語種,尤其在亞洲小語種、中東歐小語種的服務上具備競爭優勢。同時,公司已積累下超過130個多語種的發音詞典,覆蓋波斯尼亞語、塞爾維亞語、巽他語、尼泊爾語、奧利亞語、基隆迪語、茨瓦納語、達利語等小語種,累計詞條數超過1,200萬條,可支撐構建高質量的智能語音、以及多模態訓練數據,是公司的主要競爭壁壘及核心技術之一。
問:客戶什麼時候會選擇定製服務,什麼時候會選擇標準化數據集產品?
答:通常來說,客戶在選擇標準化數據集或定製化數據服務時的邏輯爲在客戶的I產品在上線之前及初期,因爲其自身尚未產生實網數據,通常需要採購模擬型數據集(即,標準化數據集)進行算法模型的訓練,在產品上線並運行一段時間、產生大量實網數據之後,則會提供實網數據給到我們進行數據加工(即,定製化數據服務),加工的數據反哺到客戶的產品上從而促進其產品的迭代、升級。之後,客戶需要進行產品功能或語種的拓展,再次需要購買模擬數據集來支撐,後續再採購數據加工服務進行迭代。相較而言,對於新興的人工智能領域,尤其是在向細分產業或場景拓展初期,通常來講定製化數據需求佔比偏多,而後隨着公司對於該領域熟知程度的加深、且市場上假若能逐漸形成共性需求,則公司會逐步拓展該領域的標準化數據集建設。
問:訓練數據產品和服務的定價模式、收費模式是什麼樣的?價格變動趨勢如何?
答:定製服務定價模式一般採用成本加成定價法。公司根據客戶的具體服務需求預估項目成本,在預估成本的基礎上,參考公司制定的指導毛利率水平,結合項目技術難度、複雜程度、時限要求等進行報價,並根據市場環境與客戶協商,最終確定價格。
產品定價模式一般採用需求導向定價法。公司綜合考慮訓練數據集的開發支出、市場需求程度、預計未來重複銷售的頻率等因素,制定產品標準價格及價格區間,在銷售過程中,根據客戶的實際需求情況,以價格區間爲基礎向客戶報價,經雙方協商確定最終銷售價格。訓練數據產品通常以單個數據集爲單位進行定價,定價比較靈活。
價格走勢主要由市場的供需關係決定。如果某類數據爲市場稀缺數據,例如具有較高進入壁壘的多模態、虛擬人等前沿類數據需求、或傳統業務裏的多語種數據,都可在一定時間內維持較高的溢價水平。但在較爲成熟的細分方向,比如中文智能語音數據領域,確實存在進入者增多、價格競爭的情況。因此,未來公司將主攻有較高技術壁壘,存在較大毛利空間的細分場景,盡力避免價格競爭帶來的過度消耗。
問:項目週期一般有多久?
答:公司的項目實施週期可以分爲以下2個類別
(1)產品類數據庫的週期因爲其在銷售時已經是成品狀態,通常1-2個月能實現收入確認;
(2)定製類服務的項目週期根據項目實際,生產過程可能涵蓋設計、採集、處理、質檢等環節,平均週期在6個月左右。如果僅爲數據加工服務,則根據客戶提供的數據量和難度,週期在3-9個月不等。
問:境外業務的毛利率爲什麼會比境內業務高?
答:首先,公司境外業務當中標準化數據集產品的銷售佔比相對更高一些,而標準化產品的銷售毛利率爲100%,遠大於定製服務毛利水平。此外,相比於境內客戶,境外客戶更認同數據服務商的綜合能力及品牌價值、價格敏感度相對較低。以上兩個因素綜合導致境外業務較高的毛利水平。
海天瑞聲(688787)主營業務:AI訓練數據的研發設計、生產及銷售業務。
 海天瑞聲2024年三季報顯示,公司主營收入1.5億元,同比上升44.9%;歸母淨利潤378.87萬元,同比上升111.8%;扣非淨利潤-193.83萬元,同比上升95.44%;其中2024年第三季度,公司單季度主營收入5713.11萬元,同比上升98.69%;單季度歸母淨利潤337.23萬元,同比上升122.67%;單季度扣非淨利潤173.75萬元,同比上升108.95%;負債率5.22%,投資收益491.08萬元,財務費用149.39萬元,毛利率66.83%。
海天瑞聲2024年三季報顯示,公司主營收入1.5億元,同比上升44.9%;歸母淨利潤378.87萬元,同比上升111.8%;扣非淨利潤-193.83萬元,同比上升95.44%;其中2024年第三季度,公司單季度主營收入5713.11萬元,同比上升98.69%;單季度歸母淨利潤337.23萬元,同比上升122.67%;單季度扣非淨利潤173.75萬元,同比上升108.95%;負債率5.22%,投資收益491.08萬元,財務費用149.39萬元,毛利率66.83%。
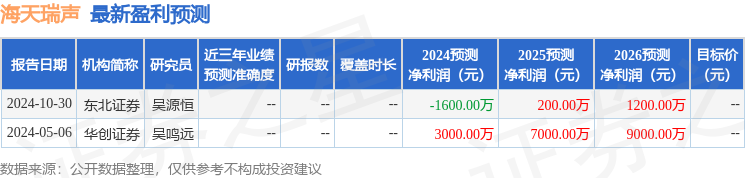
該股最近90天內共有1家機構給出評級,買入評級1家。
以下是詳細的盈利預測信息:
融資融券數據顯示該股近3個月融資淨流入3450.82萬,融資餘額增加;融券淨流出239.43萬,融券餘額減少。
以上內容爲證券之星據公開信息整理,由智能算法生成,不構成投資建議。
