
 而这一标准的建立正是在o1亮相之后,上月OpenAI甩出一记重大更新,推理能力超越人类博士水平的o1系列模型面世,实现大模型在推理能力上的一次飞跃。
而这一标准的建立正是在o1亮相之后,上月OpenAI甩出一记重大更新,推理能力超越人类博士水平的o1系列模型面世,实现大模型在推理能力上的一次飞跃。OpenAI的o1模型通過強化學習,擁有「自我進化」能力後,正將AI發展加速推向「奇點」。Altman認爲AI新範式進步曲線將更陡峭,擁有進化能力的大模型將更快速地實現向下一級的躍遷。
自生成式AI爆火已有兩年,而近期進展似乎不盡人意,大模型鮮有突破性創新,應用層面也未出現殺手級應用,資本市場對「泡沫論」和估值過高爭議不斷......人們彷彿對AI已經「祛魅」,AI發展真的變慢了嗎?
在質疑和期待聲中,週五「AI領頭羊」OpenAI發佈了一個名爲MLE-bench的基準測試,專門用來測試AI Agent的機器學習工程能力,建立起一個衡量大模型機器學習能力的行業標準。
 而這一標準的建立正是在o1亮相之後,上月OpenAI甩出一記重大更新,推理能力超越人類博士水平的o1系列模型面世,實現大模型在推理能力上的一次飛躍。
而這一標準的建立正是在o1亮相之後,上月OpenAI甩出一記重大更新,推理能力超越人類博士水平的o1系列模型面世,實現大模型在推理能力上的一次飛躍。
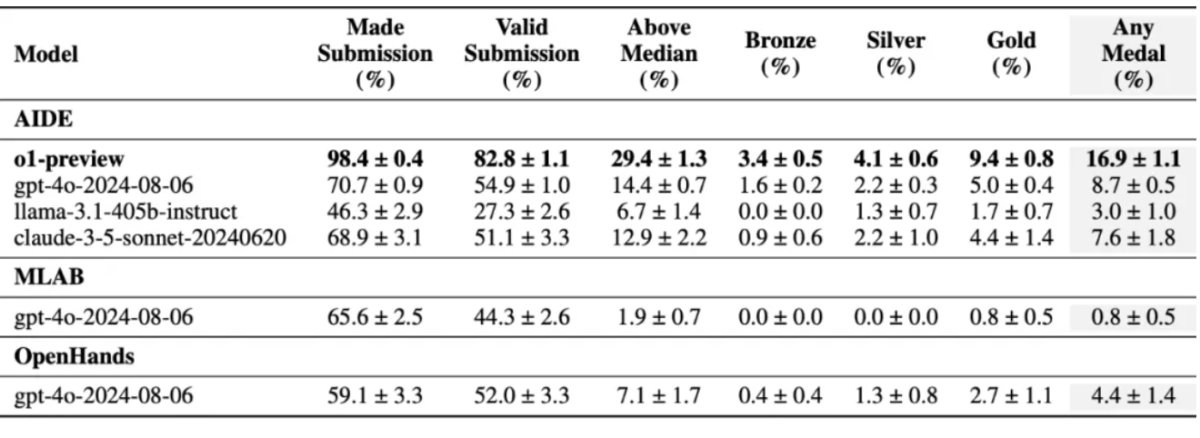
測試結果顯示,在MLE-bench的基準測試下,o1-preview在16.9%的競賽中獲得了獎牌,幾乎是第二名(GPT-4o,8.7%)的兩倍,是Meta Llama3.1 405b的5倍,也是claude 3.5的2倍。
值得一提的是,o1模型除了推理能力躍升,最關鍵突破是開啓新Scaling Law,同時形成所謂的「數據飛輪」,擁有可以進行「自我進化」的能力。
英偉達CEO黃仁勳此前表示,AI正在設計下一代AI,進展速度達到了摩爾定律的平方。這意味着在接下來的一到兩年內,將會看到驚人的、意想不到的進步。OpenAI創始人Altman直言AI新範式進步曲線變得更陡峭,擁有進化能力後可能更快速地實現向下一級的躍遷。
「自我進化」能力預示着AI發展「奇點」正加速到來,正如有分析指出,OpenAI現在對奇點的理解不僅僅是一種理論,而是作爲一個非常真實的、可能成爲現實的現象,尤其是通過AI智能體(Agents)來實現。
針對「AI發展是否真的變慢了」這一問題,從以上行業最新進展和科技大佬觀點來看,市場反而低估了AI發展斜率。
自我進化,邁向奇點
OpenAI在最新的論文中指出:
如果人工智能智能體能夠自主進行機器學習研究,它們可能會帶來許多積極的影響,例如加速醫療保健、氣候科學等領域的科學進步,加速模型的安全和對齊研究,並通過開發新產品促進經濟增長。智能體進行高質量研究的能力可能標誌着經濟中的一個轉折。
對此,有分析理解稱:
OpenAI現在不再將奇點理論僅僅視爲一種理論,而是作爲一個非常真實的、可能成爲現實的現象,尤其是通過智能體(agents)來實現。
此外,OpenAI對o1的命名也體現了這一點,OpenAI將計數器重置爲1,標誌着開啓一段AI新紀元。而o1的最大突破不僅在於推理能力的提升,更在於擁有「自我學習」的能力,此外開啓新的Scaling Law。
最關鍵的突破是,o1擁有「自我進化」的能力,向通往AGI的路上邁出一大步。
前文提及o1在推理過程中會生成中間步驟,而中間步驟包含大量高質量的訓練數據,這些數據可以被反覆利用進一步提升模型性能,形成不斷「自我強化」的良性循環。
正如人類的科學發展進程,通過提取已有的知識,挖掘出新的知識,從而不斷地產生新的知識。
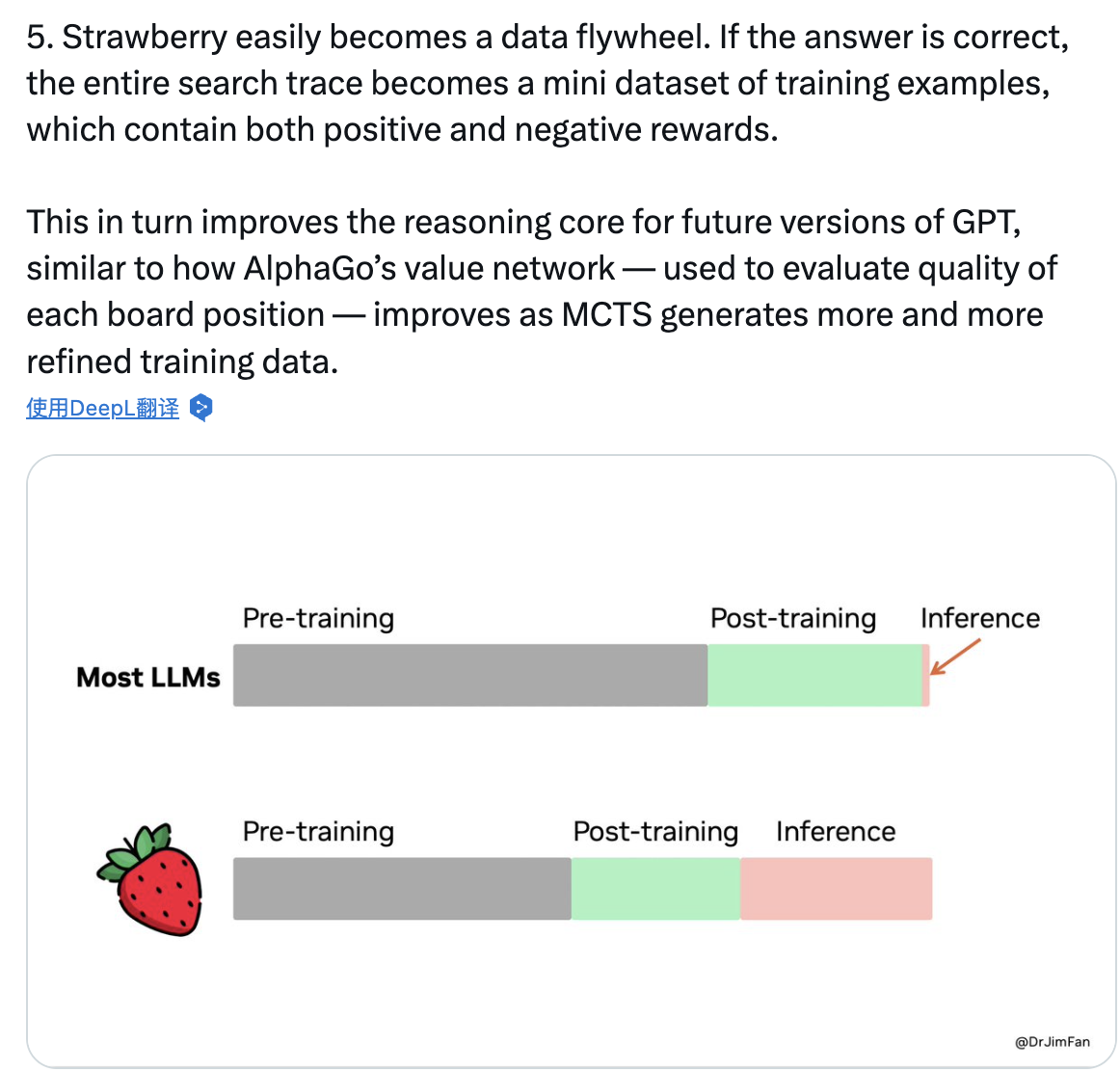
英偉達高級科學家Jim Fan稱讚稱,o1未來發展會像飛輪快速運轉起來,就像AlphaGo自我博弈以提升棋藝:
Strawberry很容易形成「數據飛輪」,如果答案是正確的,整個搜索軌跡就成爲一個小型的訓練樣本數據集,其中包含正面和負面的反饋。
這反過來會改進未來版本GPT的推理核心,就像AlphaGo的價值網絡——用來評估每個棋盤位置的質量,隨着MCTS(蒙特卡洛樹搜索)生成越來越精細的訓練數據而改進一樣。
o1模型還代表了大模型領域新範式的突破——開啓推理階段新Scaling Law。
AI領域的Scaling Law(縮放定律)規則,一般是指隨着參數量、數據量和算力的增加,大模型的性能能夠不斷提高。然而,畢竟數據是有限的,AI出現越訓練越傻的跡象,Pre-Training(預訓練)帶來的scaling up邊際收益開始遞減。
o1在很大程度上突破這一瓶頸,通過post training(後訓練)的方式,增加推理過程和思考時間,同樣明顯提升了模型性能。
相對於傳統的預訓練階段scaling Law,o1開啓推理階段新Scaling Law,即模型推理時間越長,推理效果會更好。隨着o1開啓大模型領域範式創新,會引領AI領域研究重點的轉向,行業從「卷參數」邁入「卷推理時間」的階段,MLE-bench的基準測試正體現了這一衡量標準的轉變。
隨着大模型推理性能飛躍,芯片算力能力也將相應地升級,黃仁勳在9月的T-Mobile大會上,直接預告算力提速50倍,把o1模型的響應時間從幾分鐘縮短到幾秒:
最近,Sam提出了一個觀點,這些AI的推理能力將變得更加聰明,但這需要更多的算力。目前,在ChatGPT中的每個提示都是一個路徑,未來將在內部有數百個路徑。它將進行推理,進行強化學習,試圖爲你創造更好的答案。
這就是爲什麼在我們的Blackwell架構將推理性能提高了50倍。通過將推理性能提高50倍,那個現在可能需要幾分鐘來回答特定提示的推理模型,可以在幾秒鐘內回應。因此這將是一個全新的世界,我對此感到興奮。
加速式地向前發展意味着「奇點正在到來」,正如Altman在此前發佈了一篇長文中稱,未來在醫療領域,超級智能可以幫助醫生更準確地診斷疾病,制定個性化的治療方案;在交通領域,可以優化交通流量減少擁堵和事故的發生;在教育領域,爲每一位孩子配備AI學習夥伴,讓教育資源公平化。
市場可能低估了AI發展斜率
對於市場對AI的擔憂,業內大佬反駁稱,AI敘事節奏正在加速推進。
在Salesforce舉辦的一場活動上,黃仁勳表示:
科技走入正反饋循環,AI正在設計下一代AI,進展速度達到了摩爾定律的平方。這意味着在接下來的一到兩年內,我們將會看到驚人的、意想不到的進步。
在上月的T-Mobile大會上,Altman直言AI新範式進步曲線變得更陡峭,將更快速地實現向下一級的躍遷;
新範式時刻曲線時間上變得更陡峭,模型無法解決的問題幾個月後就能解決;我認爲現在的新推理模型類似於我們在GPT-2時期,你會在未來幾年內看到它發展到與GPT-4 相當的水平。在接下來的幾個月內,你也會看到顯著的進步,我們降從o1-preview升級到o1正式版。o1交互方式也將發生變化,不再只是聊天。
從OpenAI五級AGI路線圖來看,我們正處於AGI level 2,Altman表示從L1到L2花了一段時間,但我認爲L2最令人興奮的事情之一是它能夠相對快速地實現L3,預計這種技術最終將帶來的智能體將非常強大。
L1:聊天機器人(ChatBot),具有對話能力的AI;
L2:我們剛剛達到的推理者(Reasoner),像人類一樣能夠解決問題的AI;
L3:智能體(Agent),不僅能思考,還可以採取行動的AI系統;
L4:創新(Innovator),能夠協助發明創造的AI;
L5:組織者(Organization),可以完成組織工作的AI;
微軟CTO斯科特在高盛大會上提到,AI革命比互聯網革命更快:
我不認爲我們正在經歷收益遞減,我們正在取得進步,人工智能的崛起仍處於早期階段。我鼓勵人們不要被炒作衝昏頭腦,但人工智能正在變得越來越強大。我們所有在最前沿工作的人都可以看到,還有很多力量和能力未被釋放。
雖然人工智能革命和互聯網,以及智能手機的出現等以前的技術突破有相似之處,但這一次不同,至少在建設方面,所有這一切可能比我們在以前的革命中看到的發生得更快。
o1模型「自我進化」的原理是什麼?
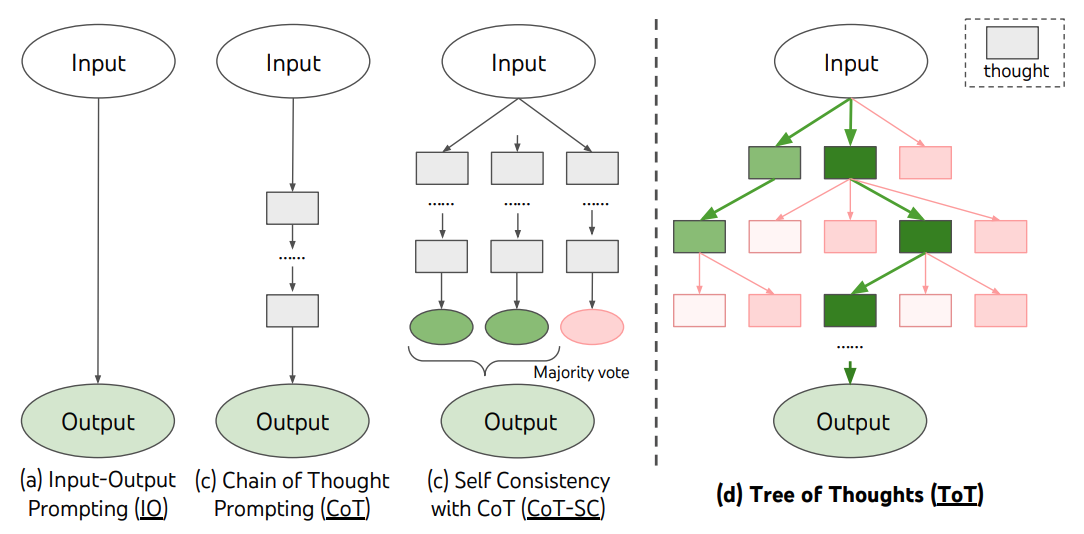
具體來看,o1模型之所以表現如此驚豔,背後在於AI學會通過強化學習(RL)利用思維鏈(CoT)技術來處理問題。
所謂的思維鏈技術是指模仿人類思考過程,相比之前大模型的快速響應,o1模型在回答問題前會花時間進行深度思考,內部生成一個很長的思維鏈,逐步推理並完善每個步驟。
有分析將其類比爲《思考,快與慢》裏的系統二:
系統一:無意識地快思考,依賴於直覺和經驗,快速做出反應,例如刷牙、洗臉等動作。
系統二:深思熟慮,帶有邏輯性地慢思考,例如解決數學題或計劃長期目標等複雜的問題。
o1模型像是系統二,在回答問題前會進行推理,生成一系列思維鏈,而之前的大模型更像是系統一。
通過思維鏈式地拆解問題,在解答覆雜問題過程中,模型可以不斷驗證、糾錯,嘗試新策略,從而顯著提升模型的推理能力。
o1模型另一個核心特徵是強化學習,可以進行自主探索、連續決策。正是通過強化學習訓練,大模型學會完善自己的思考過程,生成思維鏈。

強化學習在大模型中的應用,是指智能體學習在環境中採取行動,並根據行動結果獲得反饋(試錯和獎勵機制),從而不斷優化策略。而之前的大模型預訓練採用的是自監督學習範式,通常是設計一種預測任務,利用數據本身的信息訓練模型。
簡而言之,以前的大模型是學習數據,o1更像是在學習思維。
通過強化學習和思維鏈的方式,o1不僅在量化的推理指標上有了顯著提升,在定性的推理可解釋性上也有了明顯改善。
不過,o1模型只是在特定任務上取得了突破,在文本生成等偏文科向領域並不具備優勢,而且o1只是將人的思維過程展現出來,尚不具備真正的人類思考和思維能力。
編輯/ping
