作者:周源/华尔街见闻
9月25日,英特尔正式推出AI加速卡Gaudi 3和“Granite Rapids”Xeon 6(至强6,服务器CPU)。
 Gaudi 3对标英伟达H100和AMD的Instinct MI300,用于GAI和HPC;Xeon 6专为人工智能和高性能计算场景设计。
Gaudi 3对标英伟达H100和AMD的Instinct MI300,用于GAI和HPC;Xeon 6专为人工智能和高性能计算场景设计。
虽弱但强?怎么理解?
今年4月,英特尔就宣布,将于今年四季度推出Gaudi 3,现在,市场终于可以看到这颗英特尔倾尽全力研发的AI加速卡的实际性能,究竟有多强。毕竟,英特尔要靠这颗芯片正面PK英伟达广受市场欢迎的H100加速卡。
除了选用HBM2E(第三代)作为存储中心,较为令人迷惑——H100用的是HBM3(H100 SXM5 GPU是全球首款使用HBM3内存的GPU,提供了高达3 TB/s的内存带宽),其他的性能升级,至少从参数看,还是非常惊人的。
Gaudi 3采用台积电5nm制程工艺,拥有两个芯片组:每个芯片组各有4个(合计8个)MME(矩阵乘法引擎),包含64个张量处理器核心(TPC,带有FP32累加器的256x256 MAC结构);SRAM缓存容量翻番至96MB,带宽翻倍至19.2TB/s;HBM2E内存容量从96GB增加到128GB(8颗),带宽为3.7TB/s。
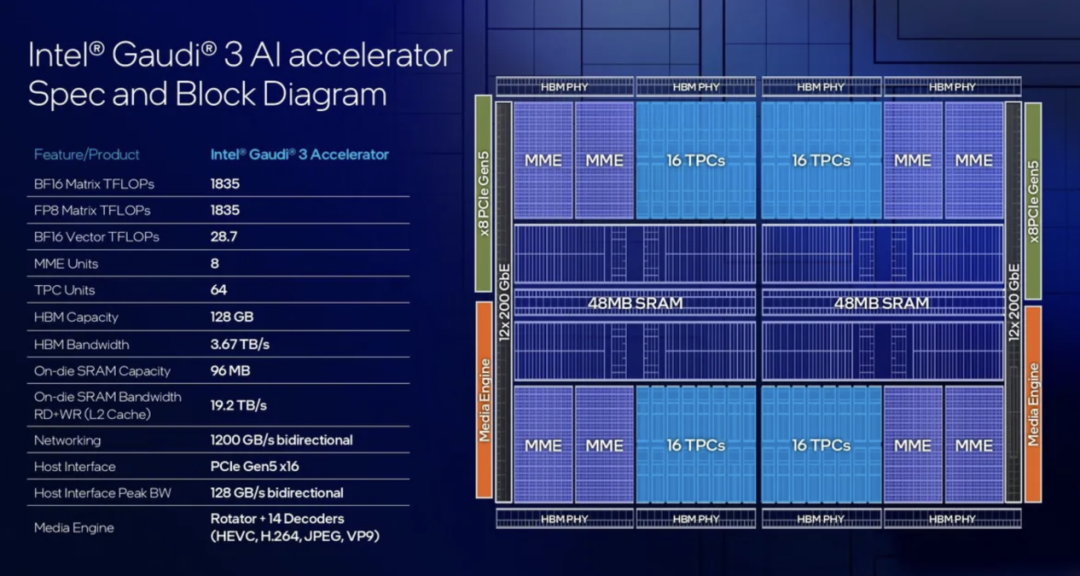
与前代Gaudi 2相比,在物理配置上,Gaudi 3也有明显的大幅提升。Gaudi 2用了台积电7nm工艺,有24个TPC、2个MME和96GB HBM2E高带宽内存。但不知出于何种考虑,英特尔Gaudi 3仅支持FP8矩阵运算和BFloat16矩阵和矢量运算,不再支持FP32、TF32和FP16。
性能方面,Gaudi 3的MME和矢量BF16的参数都赶不上英伟达H100。
Gaudi 3的MME BF16/FP8都是1835 TFlops(1.835亿亿次/秒),矢量BF16能达到28.7 TFlops(28.7万亿次/秒),分别比Gaudi 2提升3.2倍、1.1倍和1.6倍;但是英伟达H100的这三项性能参数分别为BF16的1979 TFlops(高于1835 TFlops)、FP8的3958 TFlops和1979TFlops。
在核心性能参数上,Gaudi 3和英伟达H100的差距肉眼可见。但是,英特尔却宣称,Gaudi 3比H100的LLM大模型推理性能领先50%、训练时间快40%,综合性价比是英伟达的两倍。
这是怎么做到的呢?是不是英特尔的软件能力(尤其是软件开发配套工具)和AI生态比英伟达更强?毕竟硬件性能需要强悍的软件能力,以及完善的生态做配合,才能充分激发。
对此,英特尔没有做过多解释,其宣称比英伟达更强的证据,仅是几张PPT。因此,是否真能像英特尔说的那样,还需要市场和时间验证。
唯一让市场对英伟达高度自信有信心的是售价。今年早些时候,英特尔表示,基于八颗Gaudi 3的AI加速器套件,售价12.5万美元。也就是说,每颗Gaudi 3售价约15,625美元。相比之下,H100目前售价为30,678美元,英特尔Gaudi 3的价格是英伟达H100的50.93%。
至少英特尔高层也承认生态的价值,认知还是相当全面的。
英特尔执行副总裁兼数据中心和人工智能事业部总经理 Justin Hotard 说,“对AI的需求正在推动数据中心发生巨大转变,业界要求在硬件、软件和开发工具方面做出选择。随着我们推出配备P核的Xeon 6和Gaudi 3 AI加速器,英特尔正在建立一个开放的生态系统,使我们的客户能够以更高的性能、效率和安全性实施所有工作负载。”
从这个表态可以看出,英特尔的AI加速卡生态也在构建过程中。开发配套软件方面,Gaudi 3能无缝兼容PyTorch框架、Hugging Face Transformer和扩散模型;同时,Gaudi 3会提供给IBM Cloud和英特尔Tiber开发者云。
此外,Gaudi 3加速器提供三种部署形态,分别是OAM 2.0标准夹层卡,被动散热峰值功耗900W,液冷散热峰值功耗1200W;HLB-325通用基板,功耗未知;HL-338扩展卡,PCIe 5.0 x16接口,被动散热峰值功耗600W。
基于英特尔Gaudi 3的系统将于今年第四季度从戴尔、HPE和超微全面上市,戴尔和超微的系统将于10月出货,超微的设备将于12月出货。
设计思路向联发科看齐?
同一日,英特尔还发布了宣称过久却迟迟不露面,故而快被遗忘的“Granite Rapids”Xeon 6(CPU)。
好在9月25日,“Granite Rapids”服务器 CPU 系列的高端产品终于登台,市场认为,“Granite Rapids”Xeon 6与今年6月发布的“Sierra Forest”Xeon 6芯片组合起来,还是能打的,起码能降低英特尔在IDC(数据中心)领域的市场损失。
尽管这个结果不那么好——推出一颗新的性能强劲的处理器,作用仅仅是降低损失,这无论怎么说,都有点令人沮丧。但是,英特尔的对手——AMD现在对英特尔来说,后者难以在技术、成本、性能和市场等维度做到超越,故而若能减少损失,这结果已经相对理想。
由于Xeon 6的E核(能耗)和P核(性能)变体的芯片封装和架构,在2023年的Hot Chips 2023已经公开,所以实际上,对“Granite Rapids”Xeon 6来说,性能提升的亮点就9月25日披露的信息看,最鼓舞至少是英特尔公司信心,部分让市场看到希望的亮点,是——Xeon 6提升了设计水平。
芯片设计水平能决定最终的性能表现,芯片设计最难的部分是取舍,这取决于对特定芯片定位、性能、技术水平、成本、竞争和市场需求度等极多维度的综合考虑。
比如联发科技设计旗舰芯片的核心考虑是要在保持相对低功耗的基础上,再考虑性能提升;而高通更追求高性能,不像联发科那么极度追求功耗平衡,所以之前推出了饱受市场诟病的火龙芯片。
英特尔的芯片设计考虑,有点类似于联发科。比如IPC(每时钟指令数)常被用来衡量CPU性能的重要指标。那么在芯片设计时,无限制提升IPC是可取的吗?
别忘了还有能耗限制。虽然台式机或者服务器,对能耗的容忍度更高,但也会综合考虑能耗成本。此时应该如何选择?
最近,英特尔高级研究员兼Xeon 6产品线首席架构师Ronak Singhal对这个话题有过一番解释, 核心观点就一个,英特尔Xeon 6的设计思路是降低能耗,同时再尽可能的保持高性能,故而不过分追求IPC。
这个设计指导思路的结果就是,“Granite Rapids”Xeon 6,英特尔将核心数量从之前的两颗P核的56个核心提升至120个,增加2.3倍,而顶部部分的功率仅增加至500W,仅增加1.4倍。
总的来说,Xeon 6的性能特性很多,比如超核心数(UCC)变体,即Xeon 6 6900P,具有高达504 MB的L3缓存,远超通常的英特尔芯片缓存容量。但是Xeon 6也有很奇特的设计,比如不支持支持四路和八路服务器的变体,这和Gaudi 3使用HBM2E一样令人困惑。
作者:周源/華爾街見聞
9月25日,英特爾正式推出AI加速卡Gaudi 3和「Granite Rapids」Xeon 6(至強6,服務器CPU)。
 Gaudi 3對標英偉達H100和AMD的Instinct MI300,用於GAI和HPC;Xeon 6專爲人工智能和高性能計算場景設計。
Gaudi 3對標英偉達H100和AMD的Instinct MI300,用於GAI和HPC;Xeon 6專爲人工智能和高性能計算場景設計。
雖弱但強?怎麼理解?
今年4月,英特爾就宣佈,將於今年四季度推出Gaudi 3,現在,市場終於可以看到這顆英特爾傾盡全力研發的AI加速卡的實際性能,究竟有多強。畢竟,英特爾要靠這顆芯片正面PK英偉達廣受市場歡迎的H100加速卡。
除了選用HBM2E(第三代)作爲存儲中心,較爲令人迷惑——H100用的是HBM3(H100 SXM5 GPU是全球首款使用HBM3內存的GPU,提供了高達3 TB/s的內存帶寬),其他的性能升級,至少從參數看,還是非常驚人的。
Gaudi 3採用台積電5nm製程工藝,擁有兩個芯片組:每個芯片組各有4個(合計8個)MME(矩陣乘法引擎),包含64個張量處理器核心(TPC,帶有FP32累加器的256x256 MAC結構);SRAM緩存容量翻番至96MB,帶寬翻倍至19.2TB/s;HBM2E內存容量從96GB增加到128GB(8顆),帶寬爲3.7TB/s。
與前代Gaudi 2相比,在物理配置上,Gaudi 3也有明顯的大幅提升。Gaudi 2用了台積電7nm工藝,有24個TPC、2個MME和96GB HBM2E高帶寬內存。但不知出於何種考慮,英特爾Gaudi 3僅支持FP8矩陣運算和BFloat16矩陣和矢量運算,不再支持FP32、TF32和FP16。
性能方面,Gaudi 3的MME和矢量BF16的參數都趕不上英偉達H100。
Gaudi 3的MME BF16/FP8都是1835 TFlops(1.835億億次/秒),矢量BF16能達到28.7 TFlops(28.7萬億次/秒),分別比Gaudi 2提升3.2倍、1.1倍和1.6倍;但是英偉達H100的這三項性能參數分別爲BF16的1979 TFlops(高於1835 TFlops)、FP8的3958 TFlops和1979TFlops。
在覈心性能參數上,Gaudi 3和英偉達H100的差距肉眼可見。但是,英特爾卻宣稱,Gaudi 3比H100的LLM大模型推理性能領先50%、訓練時間快40%,綜合性價比是英偉達的兩倍。
這是怎麼做到的呢?是不是英特爾的軟件能力(尤其是軟件開發配套工具)和AI生態比英偉達更強?畢竟硬件性能需要強悍的軟件能力,以及完善的生態做配合,才能充分激發。
對此,英特爾沒有做過多解釋,其宣稱比英偉達更強的證據,僅是幾張PPT。因此,是否真能像英特爾說的那樣,還需要市場和時間驗證。
唯一讓市場對英偉達高度自信有信心的是售價。今年早些時候,英特爾表示,基於八顆Gaudi 3的AI加速器套件,售價12.5萬美元。也就是說,每顆Gaudi 3售價約15,625美元。相比之下,H100目前售價爲30,678美元,英特爾Gaudi 3的價格是英偉達H100的50.93%。
至少英特爾高層也承認生態的價值,認知還是相當全面的。
英特爾執行副總裁兼數據中心和人工智能事業部總經理 Justin Hotard 說,「對AI的需求正在推動數據中心發生巨大轉變,業界要求在硬件、軟件和開發工具方面做出選擇。隨着我們推出配備P核的Xeon 6和Gaudi 3 AI加速器,英特爾正在建立一個開放的生態系統,使我們的客戶能夠以更高的性能、效率和安全性實施所有工作負載。」
從這個表態可以看出,英特爾的AI加速卡生態也在構建過程中。開發配套軟件方面,Gaudi 3能無縫兼容PyTorch框架、Hugging Face Transformer和擴散模型;同時,Gaudi 3會提供給IBM Cloud和英特爾Tiber開發者雲。
此外,Gaudi 3加速器提供三種部署形態,分別是OAM 2.0標準夾層卡,被動散熱峯值功耗900W,液冷散熱峯值功耗1200W;HLB-325通用基板,功耗未知;HL-338擴展卡,PCIe 5.0 x16接口,被動散熱峯值功耗600W。
基於英特爾Gaudi 3的系統將於今年第四季度從戴爾、HPE和超微全面上市,戴爾和超微的系統將於10月出貨,超微的設備將於12月出貨。
設計思路向聯發科看齊?
同一日,英特爾還發布了宣稱過久卻遲遲不露面,故而快被遺忘的「Granite Rapids」Xeon 6(CPU)。
好在9月25日,「Granite Rapids」服務器 CPU 系列的高端產品終於登臺,市場認爲,「Granite Rapids」Xeon 6與今年6月發佈的「Sierra Forest」Xeon 6芯片組合起來,還是能打的,起碼能降低英特爾在IDC(數據中心)領域的市場損失。
儘管這個結果不那麼好——推出一顆新的性能強勁的處理器,作用僅僅是降低損失,這無論怎麼說,都有點令人沮喪。但是,英特爾的對手——AMD現在對英特爾來說,後者難以在技術、成本、性能和市場等維度做到超越,故而若能減少損失,這結果已經相對理想。
由於Xeon 6的E核(能耗)和P核(性能)變體的芯片封裝和架構,在2023年的Hot Chips 2023已經公開,所以實際上,對「Granite Rapids」Xeon 6來說,性能提升的亮點就9月25日披露的信息看,最鼓舞至少是英特爾公司信心,部分讓市場看到希望的亮點,是——Xeon 6提升了設計水平。
芯片設計水平能決定最終的性能表現,芯片設計最難的部分是取捨,這取決於對特定芯片定位、性能、技術水平、成本、競爭和市場需求度等極多維度的綜合考慮。
比如聯發科技設計旗艦芯片的核心考慮是要在保持相對低功耗的基礎上,再考慮性能提升;而高通更追求高性能,不像聯發科那麼極度追求功耗平衡,所以之前推出了飽受市場詬病的火龍芯片。
英特爾的芯片設計考慮,有點類似於聯發科。比如IPC(每時鐘指令數)常被用來衡量CPU性能的重要指標。那麼在芯片設計時,無限制提升IPC是可取的嗎?
別忘了還有能耗限制。雖然臺式機或者服務器,對能耗的容忍度更高,但也會綜合考慮能耗成本。此時應該如何選擇?
最近,英特爾高級研究員兼Xeon 6產品線首席架構師Ronak Singhal對這個話題有過一番解釋, 核心觀點就一個,英特爾Xeon 6的設計思路是降低能耗,同時再儘可能的保持高性能,故而不過分追求IPC。
這個設計指導思路的結果就是,「Granite Rapids」Xeon 6,英特爾將核心數量從之前的兩顆P核的56個核心提升至120個,增加2.3倍,而頂部部分的功率僅增加至500W,僅增加1.4倍。
總的來說,Xeon 6的性能特性很多,比如超核心數(UCC)變體,即Xeon 6 6900P,具有高達504 MB的L3緩存,遠超通常的英特爾芯片緩存容量。但是Xeon 6也有很奇特的設計,比如不支持支持四路和八路服務器的變體,這和Gaudi 3使用HBM2E一樣令人困惑。

