
今年5月,自動駕駛迎來了一筆10億美金的巨額融資。
聚焦研發端到端自動駕駛以及自動駕駛大模型的英國初創公司Wayve.AI官宣獲得了一輪10.5億美元的融資,投資方爲軟銀、英偉達和現有投資人微軟。
即使在自動駕駛融資高漲的時候,獲得過10億美金級融資的公司也並不多,能夠挑出來的大概只有Waymo、Argo、Cruise等少數幾家。更何況自2021年上半年以來,全球自動駕駛投融資市場進入低迷期。在鮮有資本在自動駕駛領域投入巨額資金的情況下,Wayve.AI憑藉“端到端自動駕駛”概念拿下了10億美元級別的融資,或許已經在指明潮水的方向。
端到端並不是一個新的概念,它的“轉漲”來自2023年8月特斯拉發佈的FSD V12版本。此後,迅速成爲自動駕駛領域的“當紅炸子雞”。今年4月,馬斯克旋風訪華,外界盛傳他爲FSD進入中國而來,這讓人看到了使用端到端方案的FSD加速入華的可能性。
國內的頭部參與者們自然不甘示弱,小鵬、理想、蔚來、長城、華爲、元戎啓行、毫末智行都不約而同地轉向端到端自動駕駛路線,希望其成爲狙擊對手的“大殺器”。
顯然,在賽道越來越卷,以及特斯拉FSD即將入華的挑戰和激勵下,一場新的行業變局正在醞釀。
端到端與大模型,並不必然相關
自動駕駛行業一向熱衷發明新詞,比如前年流行的是“Transfomer+BEV”,去年爆火的是“大模型”、“無圖”,今年輪到了“端到端”。那麼,究竟什麼是端到端?
所謂端到端(end-to-end)架構,其對應的是傳統自動駕駛採用的模塊化架構。傳統的自動駕駛架構更多衍生於機器人架構,通常包含感知、定位、規劃三大模塊,不同領域的工程師負責不同的模塊。雖然這種方法在早期的自動駕駛技術發展中起到了積極作用,但也暴露出了一些明顯的弊端。
零一汽車智能駕駛合夥人、前圖森感知負責人王泮渠就指出,分模塊會導致架構複雜,通常有3-40個模塊,各個模塊上限不高,傳輸和優化難度高,並且局部與整體優化目標衝突。
除此之外,他還表示,開發、維護和人力成本會隨着模塊增加而飆升。並且由於疊加規則應對交付壓力,導致維護性和可擴展性變差。
相比之下,端到端不需要人爲將任務分解成多箇中間步驟,以感知的傳感器數據(圖像、點雲、雷達)作爲輸入,直接輸出用於車輛的控制指令(油門、剎車),中間過程都靠神經網絡模型來完成。如果用日常的做菜過程來理解的話,端到端就有點類似在模型這邊輸入食材,另一邊一步到位輸出了做好的菜。
從模塊化架構到端到端架構,這樣的變化有什麼好處呢?蔚來智能駕駛研發副總裁任少卿對鈦媒體App曾表達過,“真實世界是複雜的。越往後你會發現,你可以解決99%的問題,但就是這1%的問題解決不了。所以大家就希望說那我不定這個接口了,讓網絡自己學,讓機器自己去定,這個的核心就是端到端,就相當於把前面和後面連起來,把接口乾掉,能幹掉很多事。”
辰韜資本投資經理劉煜冬對鈦媒體App也表示,對於自動駕駛很多的“只可意會,不可言傳”的長尾場景,像積水、汽油等不同的路況,端到端有很強的應對能力。並且,端到端可以讓駕駛風格更加擬人化,表現得更像人類司機,比如遇到堵車的情況提前處理,訓練模型會更像人類老司機。
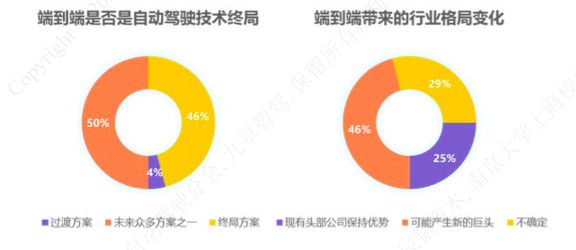
圖片來源:辰韜資本《端到端自動駕駛行業研究報告》
值得注意的是,在談到端到端自動駕駛時,人們很容易將其與大模型的概念混淆在一起。劉煜冬坦言,實際上兩者並不必然相關。
之所以會這樣說,在於大模型更多關注模型的參數數量以及湧現能力,而端到端更多強調的是結構上的梯度可傳導以及全局優化。目前的大模型爲端到端實現提供了很好的可選方案,但是端到端並非必然基於大模型實現。
對於自動駕駛及具身智能領域的 “ 大模型 ”,往往不是傳統意義上的 “ 大 ” 模型。這類大模型由於更多考慮了車端算力以及實時性要求的性質,很難達到和 NLP (Natural Language Processing) 或者通用 AI 領域同等的標準。如果不考慮英偉達規劃 2025-2026 年量產的 Thor,目前車端算力較大的也只有幾百 TOPS (Tera Operations Per Second),這種算力水平遠遠無法滿足動輒 10B 甚至上百 B 的大模型需求。
所以,自動駕駛領域的大模型都是小於 1B 的模型,這裏所謂的 “ 大 ” 的定義更多的是相對於原來感知系統採用的幾百萬參數的小模型而言。
新舊勢力押注,2025年量產
事實上,端到端並不是一個全新的概念。
2016年,英偉達就提出採用單個神經網絡來實現端到端的自動駕駛。但由於結構設計過於簡單,模型的規模也過小,這種方案僅能支持高速或者簡單道路狀況下的自動駕駛,且僅僅完成了小規模的demo驗證。
直到2023年8月特斯拉公佈FSD V12版本時提到引入了“端到端”技術,從此成爲自動駕駛界最火熱的概念。
國內的小鵬汽車緊跟一步。1月30日,何小鵬表示小鵬智駕未來將實現端到端模型全面上車。5月20日,小鵬汽車在北京舉辦“AI DAY”,宣佈即日起開始向用戶推送基於端到端大模型的智能駕駛和智能座艙系統。
4月24日,華爲智能汽車解決方案發佈會上,華爲發佈了以智能駕駛爲核心的全新智能汽車解決方案品牌 —— 乾崑,併發布了採用端到端架構的ADS 3.0。 據悉,在6月剛剛上市的享界S9已經首發搭載了ADS 3.0智駕系統。
蔚來則在4月公開了端雲算力規模,並透露端到端方案會在今年年內發佈。最近還有報道稱,蔚來智駕研發部已經完成架構調整,要放棄業界沿用多年的“感知-決策-規控”的技術路線,這意味着蔚來將更明確地探索用端到端大模型實現高階智能駕駛。
理想汽車也不甘落後。在2024中國汽車重慶論壇上,理想汽車董事長兼CEO李想透露,將向測試用戶推送基於300萬clips訓練出的端到端+VLM自動駕駛體系。預計最早在今年年底、最晚明年年初,理想汽車將推出通過超過1000萬clips訓練出的更完善的自動駕駛體系,爲用戶提供監督型L3級自動駕駛體驗。
新勢力不斷出牌,傳統車企也在奮進追趕。4月15日,在長城汽車董事長魏建軍的直播首秀中,新款魏牌藍山車型搭載的端到端智駕方案就曾引發外界關注。
在這一塊發力的除了蔚小理、長城等衆多車企,還有小馬智行、英偉達、元戎啓行、商湯絕影等產業鏈企業。
去年,小馬智行將感知、預測、規控三大傳統模塊打通,統一成端到端自動駕 駛模型,目前已同步搭載到 L4 級自動駕駛出租車和 L2 級輔助駕駛乘用車。
2024北京車展前夕,吳新宙展示了英偉達自動駕駛業務從 L2 到 L3的發展規劃,其中提到規劃的第二步爲 “ 在 L2++ 系統上達成新突破,LLM(Large Language Model,大語言模型)和 VLM(Visual Language Model,視覺語言模型) 大模型上車 。
元戎啓行、商湯絕影則是在北京車展上各自展示了端到端產品。前者展示的是即將量產的高階智駕平台 DeepRoute IO 以及基於 DeepRoute IO 的端到端解決方案,後者推出的則是面向量產的端到端自動駕駛解決方案 “UniAD”。
至於端到端架構何時上車,辰韜資本發佈的《端到端自動駕駛行業研究報告》表示,這一技術演進的時間進度可以參考國內企業追趕特斯拉BEV/Occupancy Network的進度。特斯拉在2021和2022年年底的AI Day上分別公佈了BEV和Ocuupancy Network的技術架構,而國內車企開始OTA基於BEV/Occupancy Network的功能普遍在2023-2024年,與特斯拉的研發進度差大概在1.5~2年。參考前述追趕進度, 國內自動駕駛公司的模塊化端到端方案上車量產時間可能會在2025年。
2023年9月中信證券發佈研報預測:2025年起,端到端發展的提速將催化各級別自動駕駛功能滲透率大幅提升,我們據此更加樂觀地預測,高速NOA滲透率至2026年將超過30%,城市 NOA滲透率超過 10%。
數據、算力是入場券,也是挑戰賽
頭部車企、自動駕駛技術供應商都在跑步進場,但端到端的上車仍有極高難度。
首先,擺在國內廠商面前亟待解決的就是端到端訓練的數據難題。畢竟端到端方案中的一體化訓練需要通過足夠多的數據訓練,這樣才能湧現出一些驚人的能力。
馬斯克之前曾談到過數據對自動駕駛模型的重要性:訓練了100萬個視頻Case,勉強夠用;200萬個,稍好一些;300萬個,就會感到Wow;到1000萬個,就變得難以置信了。
除了數據量的差距,從這些難以計算的數據中,找出可以用於訓練的有效數據,是另一個重要的挑戰。
“老的數據要求的場景比較單一,複雜度低。深度學習的路線要求的場景分佈會大很多,數據集的多樣性要求更高。”愷望數據解決方案總監黃玉慶表示。
在他看來,目前自動駕駛數據的採集處理面臨諸多挑戰。首先,車廠的採集方案都不太相同,標準不一樣。其次,路採的時候涉及到合規,如何脫敏並且上傳到雲端,需要合規的公司做支持,而提供這樣合規服務的公司並不是很多。再次,數據管理平台這部分國內並不完整,比如雲端做大批量訓練和計算時怎樣進行清洗、拆、剪輯、標註。
面對數據量、數據標註、數據質量和數據分佈等多維度的挑戰,業內有一種說法是:建立數據共享平台 。
對此,極佳科技工程負責人毛繼明表示,數據共享的價值毋庸置疑,但要謹慎樂觀。“數據共享背後是數據交易和數據價值的共識,買方和賣方很難達成共識。生成的好壞對於訓練效果的影響也會影響共識,需要政府推動。另外也可以出臺國標或法律。”
輝羲智能市場副總裁劉奇也表示,衆多主機廠的痛點,不是每家主機廠都能投這麼多錢把數據採集起來。對於數據採集統一化有很高的要求,各家技術方案都不一樣。另外,商業上的收益會是影響閉環更大的因素。
即便解決了數據採集問題,這也只是第一步,算力也是很大的限制。
在2024 Q1業績電話會上,特斯拉表示,公司已經有35000張H100GPU,並計劃在2024年內增加到85000張H100以上,達到和谷歌、亞馬遜同一梯隊。
在國內,大部分研發端到端自動駕駛的公司目前的訓練算力規模在千卡級別,隨着端到端逐漸走向大模型,訓練算力將顯得捉襟見肘。
理想汽車總裁、總工程師馬東輝在理想汽車今年第一季度業績電話會上坦言,特斯拉“端到端大模型”需要大量的數據和訓練算力,“這不是所有車企都有能力和資源做到的”。
餘承東也發表過類似看法,他曾自信地表示,“國外就是特斯拉,國內就是華爲。”他認爲,在智駕上會強者越強,一步領先就步步領先。投入大,成本高,一般企業根本投入不起。
據悉,華爲乾崑ADS 3.0在算力方面達到3.5E FLOPS(注:FLOPS指每秒執行的浮點運算次數,1E FLOPS即100億億次),訓練數據量已達日行3000萬公里。
小鵬汽車爲此給出過明確的數字:2024年將投入35億元用於智能研發,並新招募4000名專業人才,今後每年還將投入超過7億元用於算力訓練。
特斯拉則是計劃2024年底前對DOJO超算中心投資超過10億美元,以提升總算力至10萬PFLOPS。
顯然,要想把端到端做好並不容易,需要巨大的車隊、巨大的算力、非常長時間在安全領域的浸潤。這場以“端到端”爲中心的拼殺還在繼續,角力的烈度仍在加劇。接下來,我們更想觀察的是撥開營銷的迷霧,端到端的真相到底會是什麼。
(本文首發於鈦媒體App 作者|韓敬嫺)