来源:腾讯科技
全球首台,黄仁勋亲自送货上门,OpenAI首发,DGX H200算是把流量拉满了。
DGX H200在发布大概半年后出货交付客户,按级别算属于现役“AI算力核弹”,更先进的GB200系列毕竟还没有量产服役。
作为山姆·奥特曼的亲密战友,在去年的“宫斗事件”中一同被赶出公司的格雷格·布罗克曼兴奋的在推特上官宣了这一消息。格雷格·布罗克曼炫耀式的推文中,还特意引用了黄仁勋在这台设备上的寄语签名——“为了推动AI、计算与人类的发展。”
 山姆·奥特曼、黄仁勋与格雷格·布罗克曼与DGX-GH200服务器合影
山姆·奥特曼、黄仁勋与格雷格·布罗克曼与DGX-GH200服务器合影2016年,彼时黄仁勋在马斯克等人的见证下,也曾为OpenAI捐赠了全球首台DGX-1服务器。请注意,当时是赠送的。黄仁勋写道,“致埃隆和OpenAI团队,为了计算和人类的未来,我向你们赠送世界上第一台DGX-1。”
两次题词,都强调“为了计算和人类的未来”,或多或少能说明:硅谷大佬们眼中“规模法则”是带领人类通往AGI时代的大门;黄仁勋和$英伟达 (NVDA.US)$,掌握着打开这扇大门的钥匙。
一直以来,OpenAI信奉的就是这种“大力出奇迹”的逻辑,山姆·奥特曼频繁对外吹风“我们需要更多的GPU”、“世界需要更多的人工智能计算”,甚至被传出“7万亿美元投资AI芯片制造”的消息。
我们的问题是,硅谷巨头们的算力储备情况如何,英伟达能否缓解AI布道者们的算力焦虑症,而谁又会成为英伟达供应算力子弹的掣肘,回答这些问题,可以从H200的“战斗力”开始。
1、H200迎战MI300X、Gaudi3
H200实际上去年下半年就已经发布,分HGX和DGX两个版本。HGX可以理解为计算模组,包含4 GPU、8 GPU两个版本,而DGX版本可以理解为AI超算服务器,不仅搭载了GPU模块,还配置有操作系统和处理器。
大家都说DGX H200交付,更准确的说法应该是DGX GH200,这里的“G”,对应的就是英伟达的Grace处理器。
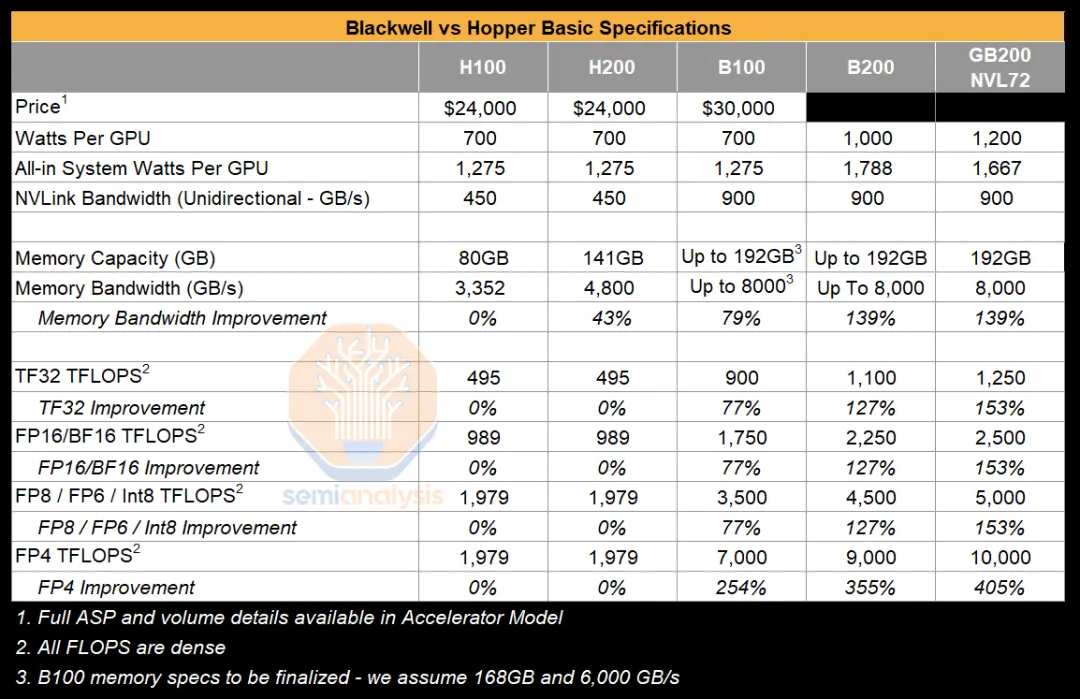
单纯的看硬件,H200和上一代产品H100采用相同的Hooper架构,浮点运算性能基本没有提升(如下表),改进在于H200全球首发了HBM3e内存(去年8月给客户送样,今年3月开始量产),显存达到了141GB,显存带宽达到4.8TB/s。
 *BlackWell和Hopper架构基础硬件规格对比,来源:Semianalysis
*BlackWell和Hopper架构基础硬件规格对比,来源:Semianalysis由于浮点运算性能没有提升,整体配置没有大改,H200也被外界解读为半代升级,但价格基本上不变,好歹算是个加量不加价,未来H100即将退役,相关市场则交棒给H200了。
按英伟达官方的说法,H200运行70B参数的Llama 2和175B参数的GPT-3,推理性能分别提升1.9倍和1.6倍。
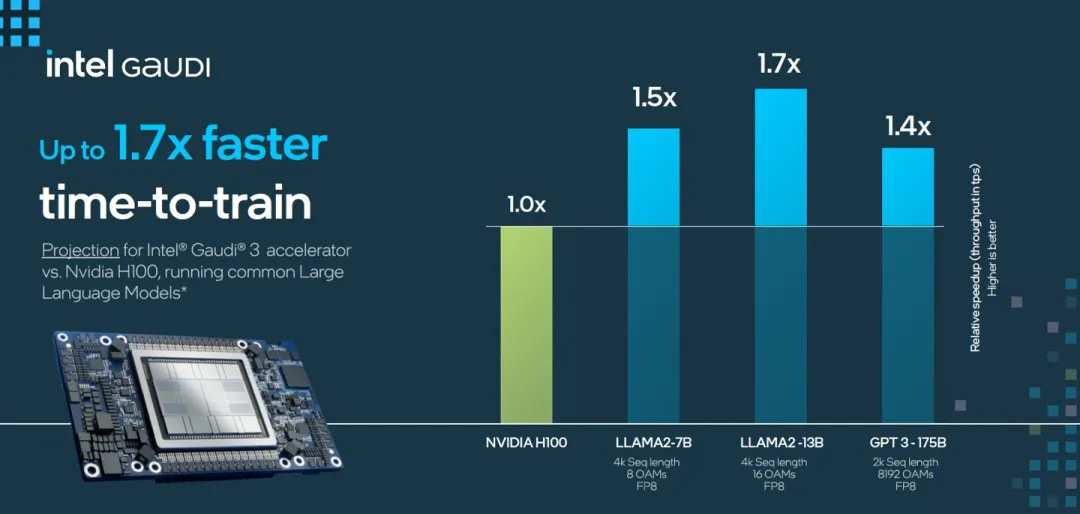
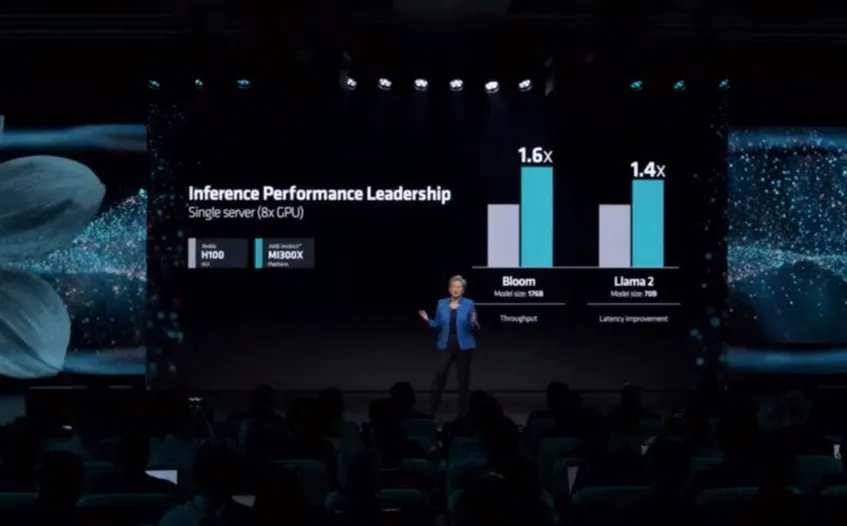
作为明星产品,H100一直被用来作为行业对标的对象,AMD发布MI300X时对外强调,70B参数的Llama 2推理性能是H100的1.4倍,英特尔在Gaudi3上给出的数据则是1.5倍。
把几款产品放在一起对比,H200、Gaudi 3和MI300X,70B参数的Llama 2模型,推理性能分别是H100的1.9倍、1.5倍和1.4倍。
![*Intel和AMD官方提供的Gaudi 3、MI300X 70B参数Llama 2推理性能]() *Intel和AMD官方提供的Gaudi 3、MI300X 70B参数Llama 2推理性能
*Intel和AMD官方提供的Gaudi 3、MI300X 70B参数Llama 2推理性能基于显存、带宽的提升,依旧能让英伟达在特定参数模型的推理上,占据领先地位。更重要的是,黄仁勋手中还有未上市的“核弹级产品”GB200,以及未公布的B100。
基于纸面参数看,英伟达目前还领先竞争对手一个代差,但纸面参数的追赶并不难。
作为挑战者,AMD和英特尔还需要提供让开发者从英伟达的CUDA生态走出去的吸引力,这种生态建设则是长期的追赶过程。芯事重重资深顾问,亚洲视觉科技研发总监陈经在GTC大会解读直播中将CUDA类比成PC互联网时代的Windows,“开发者则需要在Windows给定的框架里使用PC。”
“CUDA不是一个孤立软件,它需要众多配套系统,包括硬件层、驱动、GPU集群、底层库、Pytorch等上层库、编译器,跟着CUDA的套路走会很方便,一旦偏离套路就遇到知识盲区,懂怎么调整的人极为稀缺。”陈经认为如果人们想抛开CUDA,虽然可以选择单卡性能(比H100)更强的MI300X,但“实战”搭环境可能会面临无数个想不到的bug而被弄崩溃,适配的时间耗不起。
除了生态,另一个增加吸引力的杠杆是价格,追赶者需要借助更高的性价比,来覆盖开发者们的迁移成本。
当然,挖墙角并不是一件容易的事情,英伟达在商业策略上也有明确的反竞争机制,Semianalysis曾在研究报告中援引供应链人士的爆料,称英伟达正在基于多重因素,对客户进行不同优先级的产能分配。影响因素包括但不限于:存在多方采购的情况,自研AI芯片,捆绑采购英伟达其他产品。
在这种情况下,下场自研都会面临订单交付优先级下调的风险,更不用说在英伟达、AMD和Intel之间“骑墙”。
当然,这些都是对于存量用户的争抢。增量用户面前,性价比就是Intel、AMD这些追赶者的强力武器,这个策略在英特尔身上表现的最为明显——今年的Intel Vision大会上,英特尔就秀了一波合作伙伴阵容,其中包括博世、Naver、SAP、Ola等等。
2、硅谷公司抢算力“上头”
算力是硅谷巨头们在AI时代的硬通货,但他们手里到底屯了多少显卡,构建了什么规模的算力?
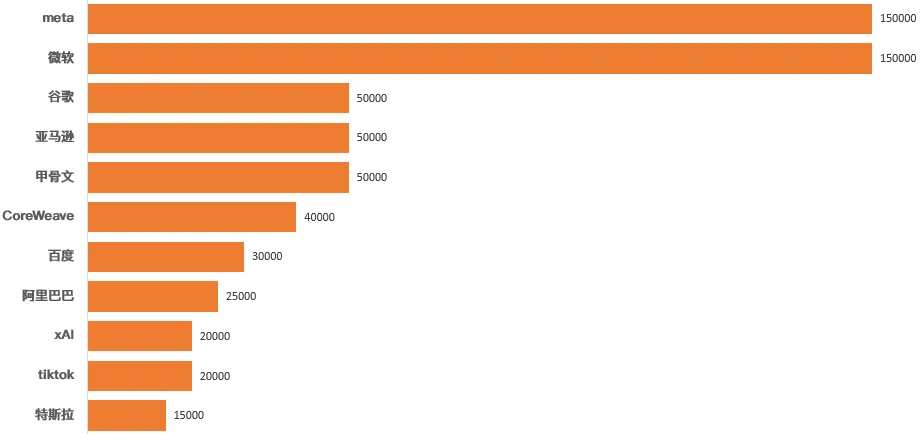
研究机构Omdia的数据显示,截至2023年第三季度,英伟达H100出货量达到65万张,其中$Meta Platforms (META.US)$和$微软 (MSFT.US)$分别拿下15万张,接近全部订单的一半。如果按照单卡价格24000美元计算,截至到2023年第三季度,65万张H100总计为英伟达贡献156亿美元营收。
![截至到2023年Q3,H100的出货量及主要科技公司储备情况,来源:Omdia]() 截至到2023年Q3,H100的出货量及主要科技公司储备情况,来源:Omdia
截至到2023年Q3,H100的出货量及主要科技公司储备情况,来源:Omdia另外,Omdia数据还显示,仅仅第三季度,英伟达的H100出货量就达到50万台,价值120亿美元。也就是说,硅谷巨头们的订单在第三季度得到了集中交付。交付量的增长与CoWoS封装产能拉升呈正相关。公开数据显示,$台积电 (TSM.US)$于去年4月、6月和10月,先后进行了多轮CoWoS设备加单,并且还对InFO封装线改机以增加CoWoS产能。
需要注意,Omdia的数据只统计到第三季度,且不包含OpenAI,所以只做参考。实际上,各家H100的囤货都在不断上涨,硅谷巨头们对算力的需求并不是虚张声势,而是用真金白银兑现。
日前,马斯克在$特斯拉 (TSLA.US)$电话会议上确认公司已经储备3.5万张H100。对照上面的图表,这意味着特斯拉过去两个季度新储备2万张H100。马斯克在电话会议上还表示,到2024年年底,总计储备量将达到8.5万张。扎克伯格更早之前就宣布计划到2024年底,将H100的储备量提升到35万张,微软则提出了更宏大的目标,到年底GPU储备量翻一倍,达到180万张,实际是在暗示目前已经屯了90万张(感慨一下纳德拉的钞能力)。
买卡其实很好理解,但前有发布间隔大半年的H200,后有性能更出众的B200,硅谷巨头们应该怎么选?
有报道称微软将放弃采购H100,计划抢夺50%的GB200订单,可是问题在于,“算力核弹”B200现阶段还属于“期货”。按照H200的交付节奏预估,包含台积电的逻辑芯片的生产及封装,富士康和纬创的代工以及最终进入渠道,B200系列向客户发货最快也要到今年四季度。
黄仁勋给OpenAI交付全球第一台DGX GH200,其目的也是在向市场表态,H200系列已具备量产交付能力,如果大家想要进入AGI时代,“钥匙”就摆在这里,而微软喊“卡”,就意味着将算力拱手让人。
争抢算力在人类史上可能会是一个长期现象,只是大家都在喊着缺显卡,缺算力,谁才是真正缺的那一位?
傅盛在腾讯科技的对话中提到过谷歌的案例,他说“如果一个谷歌研究员跟老板说训练一次2000万美金,老板问能不能做成?你说不知道,肯定就很难申请到资源。”
也就是说,对于一家商业化公司,当你的目标或者收益不够明确时,想烧钱堆算力做大模型是一件很困难的时间,毕竟所有的资本支出要对股东、投资人负责,微软和Meta疯狂砸钱买卡,就是因为商业回报已经有若隐若现的意思。
扎克伯格在2024财年一季度电话会议上说,“生成式AI可能要投资数年,才能实现有效盈利”,看起来是给投资者打预防针,但Meta的信息流、广告推荐系统都已经清楚的看到投资回报。扎克伯格说,脸书30%的帖子来自AI推荐系统,Instagram更是达到了50%,而且两个端到端人工智能工具Advantage+购物和Advantage+应用带来的收入已经翻倍增长。
微软的逻辑也差不多,刚刚公布的2024年第三财季业绩全面超预期,AI推动Azure云收入加速增长了31%,贡献的云收入增幅提升至7个百分点,包含Copilot AI助手的Office商业收入增长15%。
如果真的说巨头们信奉“规模法则”,强调“大力出奇迹”,至少微软、Meta们还可以再加一个“不见兔子不撒鹰”的标签。
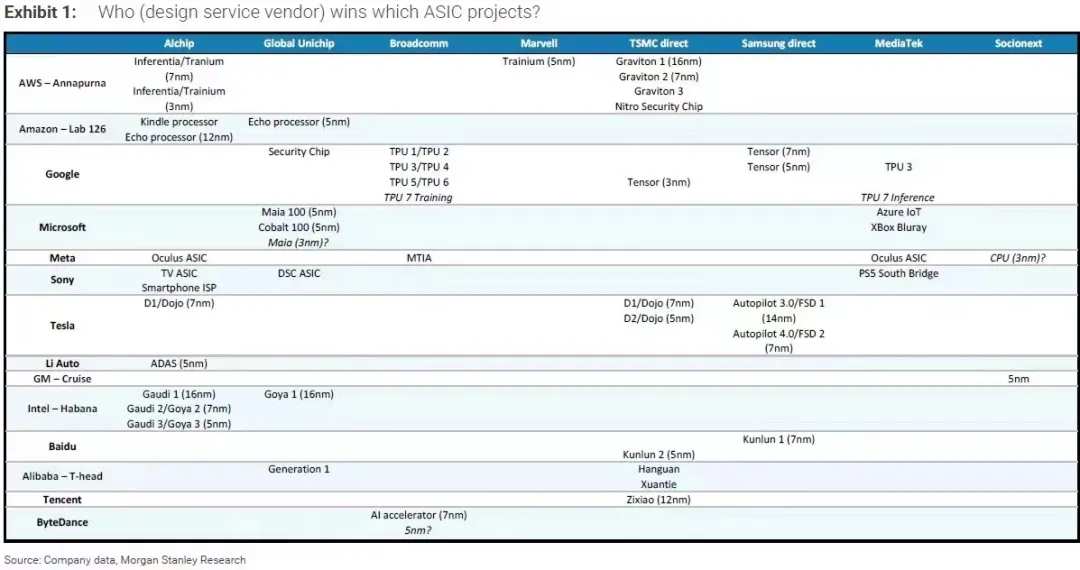
![全球科技公司自研芯片布局,来源:摩根史坦利]() 全球科技公司自研芯片布局,来源:摩根史坦利
全球科技公司自研芯片布局,来源:摩根史坦利当然,储备算力,买或者说抢是一条路径,自研则是另一条路径,这可能会带来数十亿的采购和能耗成本的缩减。
不过,自研前期资本支出巨大,从投入到性能符合预期的产出兑现也需要时间,基本上科技公司都在采用自研+采购两条腿走路的策略。
大摩此前提供了一份研究报告,资料显示绝大部分科技公司在自研芯片上都有布局(如上图),包括谷歌的TPU,meta的MTIA,也包括国内大厂的相关项目。
长期看,自研确实可以消除算力焦虑,大摩对自研的总结是“单美元效率”更高,尤其是不追求最尖端工艺产品的情况下,“单美元效率”会更明显。Semiannaly的“总拥有成本”也值得参考,该机构在研究报告中以GB200为例,强调尽管Blackwell系列提供了更多浮点运算性能,但考虑到硅面积的增加,单位面积的性能并没有显著提升,而且随着功率的提升,每瓦性能的提升幅度也会逐步下降。
还有一个终极问题,钱和卡都有了,电怎么办?
AI初创公司OpenPipe联合创始人、CEO 凯尔·科比特援引一位微软的工程师的观点称,“如果在一个州放置超过10万张H100 GPU,电网就会崩溃。”那么,卡不够可以自研,电不够,硅谷巨头们又要下场布局电力基础设施?
3、“卡黄仁勋脖子”的两只手
硅谷巨头缺卡又缺电,英伟达则缺CoWoS产能和HBM内存。
CoWoS被称之为2.5D封装,简单说就是将逻辑芯片、HBM内存通过硅中介层,再透过硅通孔技术,最后连接至PCB基板上,其英文全称也就是Chip on Wafer on Substrate。
今年GTC,黄仁勋在面对全球媒体的采访时,被问及CoWoS需求是去年三倍是否属实时幽了一默,反问记者“你想要确切的数据,这很有趣。”
关于英伟达CoWoS需求的具体情况,黄仁勋不给小抄,就只能参考外界数据。
Digitimes援引设备厂的数据,称台积电2023年全年CoWoS总产能逾12万片,2024年将冲上24万,英伟达将取得14.4万-15万片,占台积电总产能约60%左右。从Semianalysis跟踪的数据来看(如下图),2023年Q3英伟达的占比大致在40-50%的区间。
另外,随着台积电扩产及其他客户需求增长,英伟达的CoWoS需求占比也会被稀释,去年11月份,台积电电话会议上确认英伟达占台积电CoWoS总产能的40%,基本和Semianalysis数据吻合。
![*Semianalysis提供的CoWoS产能分布情况跟踪和预测]() *Semianalysis提供的CoWoS产能分布情况跟踪和预测
*Semianalysis提供的CoWoS产能分布情况跟踪和预测而按月拆分,Digitimes还预测,台积电的今年一季度CoWoS产能将爬升到17000片/月,到年底有机会爬升到26000片-28000片/月。
按照CoWoS月产能17000片的数据来计算,如果英伟达可以拿到其中40%,即6800片,而一片12英寸的晶圆,大致可以切30张左右的H200,即台积电单月可完成20.4万张H200的封装。到年底,按照台积电26000片/月的CoWoS产能,英伟达如果还是占40%,即10400片/月,单月可以完成31.2万张H200的封装。
也就是说,英伟达在台积电的助攻下,H200 GPU全年的封装产能,下限可能是244万张,上限有可能突破374万张,按照24000美元的单价,价值在580亿美元-890亿美元之间。
虽然和台积电长期交好,但似乎黄仁勋并不满足于当前的产能,也有消息说英伟达将在二季度向英特尔开出先进封装订单,预计月产能大概5000片左右,即单月封装15万张H200。
英伟达苦CoWoS产能久矣,同样苦HBM产能久矣。以H100、H200都是标配了6颗HBM内存,而GB200更是搭配了8颗HBM3e内存,HBM内存不够用了怎么办?
目前,HBM内存主要供应商有SK海力士、三星与美光,和先进封装一样,HBM厂商也在疯狂扩产。
外媒援引韩国券商Kiwoom Securities的数据,称$三星电子 (SSNLF.US)$的HBM内存月产能,预计将从2023年第二季的 2.5万片晶圆增加到2025年第四季度的15-17万片;同期,SK海力士的月产能预计将从3.5万片爬升到12-14万片,以此来估算,2024年全球HBM总产能70-75万片左右。
以12层堆叠的HBM3e为例,按照90%的良率,每片晶圆可以切750颗HBM,按照前面估算的70-75万片年产能,预计全球2024年总计产出5200-5600万颗HBM3e内存。而如果按前面的H200产能计算,每张GPU搭配6颗HBM内存,仅英伟达一家,对HBM内存的年需求总量大致在1460万-2240万颗区间。
如果SK海力士、三星和美光的HBM内存扩产顺利,英伟达悬着的心基本可以放下一半的,另一半也要看AMD、英特尔以及自研的企业如何来抢产能了。
毕竟,也不能在下场自研AI芯片,盖晶圆代工厂,建发电站这些想法出现之后,再给硅谷巨头们安排新任务——下场盖内存厂。
编辑/lambor
來源:騰訊科技
全球首臺,黃仁勳親自送貨上門,OpenAI首發,DGX H200算是把流量拉滿了。
DGX H200在發佈大概半年後出貨交付客戶,按級別算屬於現役“AI算力核彈”,更先進的GB200系列畢竟還沒有量產服役。
作爲山姆·奧特曼的親密戰友,在去年的“宮鬥事件”中一同被趕出公司的格雷格·布羅克曼興奮的在推特上官宣了這一消息。格雷格·布羅克曼炫耀式的推文中,還特意引用了黃仁勳在這臺設備上的寄語簽名——“爲了推動AI、計算與人類的發展。”
山姆·奧特曼、黃仁勳與格雷格·布羅克曼與DGX-GH200服務器合影 2016年,彼時黃仁勳在馬斯克等人的見證下,也曾爲OpenAI捐贈了全球首臺DGX-1服務器。請注意,當時是贈送的。黃仁勳寫道,“致埃隆和OpenAI團隊,爲了計算和人類的未來,我向你們贈送世界上第一臺DGX-1。”
兩次題詞,都強調“爲了計算和人類的未來”,或多或少能說明:硅谷大佬們眼中“規模法則”是帶領人類通往AGI時代的大門;黃仁勳和$英偉達 (NVDA.US)$,掌握着打開這扇大門的鑰匙。
一直以來,OpenAI信奉的就是這種“大力出奇跡”的邏輯,山姆·奧特曼頻繁對外吹風“我們需要更多的GPU”、“世界需要更多的人工智能計算”,甚至被傳出“7萬億美元投資AI芯片製造”的消息。
我們的問題是,硅谷巨頭們的算力儲備情況如何,英偉達能否緩解AI佈道者們的算力焦慮症,而誰又會成爲英偉達供應算力子彈的掣肘,回答這些問題,可以從H200的“戰鬥力”開始。
1、H200迎戰MI300X、Gaudi3
H200實際上去年下半年就已經發布,分HGX和DGX兩個版本。HGX可以理解爲計算模組,包含4 GPU、8 GPU兩個版本,而DGX版本可以理解爲AI超算服務器,不僅搭載了GPU模塊,還配置有操作系統和處理器。
大家都說DGX H200交付,更準確的說法應該是DGX GH200,這裏的“G”,對應的就是英偉達的Grace處理器。
單純的看硬件,H200和上一代產品H100採用相同的Hooper架構,浮點運算性能基本沒有提升(如下表),改進在於H200全球首發了HBM3e內存(去年8月給客戶送樣,今年3月開始量產),顯存達到了141GB,顯存帶寬達到4.8TB/s。
*BlackWell和Hopper架構基礎硬件規格對比,來源:Semianalysis 由於浮點運算性能沒有提升,整體配置沒有大改,H200也被外界解讀爲半代升級,但價格基本上不變,好歹算是個加量不加價,未來H100即將退役,相關市場則交棒給H200了。
按英偉達官方的說法,H200運行70B參數的Llama 2和175B參數的GPT-3,推理性能分別提升1.9倍和1.6倍。
作爲明星產品,H100一直被用來作爲行業對標的對象,AMD發佈MI300X時對外強調,70B參數的Llama 2推理性能是H100的1.4倍,英特爾在Gaudi3上給出的數據則是1.5倍。
把幾款產品放在一起對比,H200、Gaudi 3和MI300X,70B參數的Llama 2模型,推理性能分別是H100的1.9倍、1.5倍和1.4倍。
![*Intel和AMD官方提供的Gaudi 3、MI300X 70B參數Llama 2推理性能]() *Intel和AMD官方提供的Gaudi 3、MI300X 70B參數Llama 2推理性能
*Intel和AMD官方提供的Gaudi 3、MI300X 70B參數Llama 2推理性能基於顯存、帶寬的提升,依舊能讓英偉達在特定參數模型的推理上,佔據領先地位。更重要的是,黃仁勳手中還有未上市的“核彈級產品”GB200,以及未公佈的B100。
基於紙面參數看,英偉達目前還領先競爭對手一個代差,但紙面參數的追趕並不難。
作爲挑戰者,AMD和英特爾還需要提供讓開發者從英偉達的CUDA生態走出去的吸引力,這種生態建設則是長期的追趕過程。芯事重重資深顧問,亞洲視覺科技研發總監陳經在GTC大會解讀直播中將CUDA類比成PC互聯網時代的Windows,“開發者則需要在Windows給定的框架裏使用PC。”
“CUDA不是一個孤立軟件,它需要衆多配套系統,包括硬件層、驅動、GPU集群、底層庫、Pytorch等上層庫、編譯器,跟着CUDA的套路走會很方便,一旦偏離套路就遇到知識盲區,懂怎麼調整的人極爲稀缺。”陳經認爲如果人們想拋開CUDA,雖然可以選擇單卡性能(比H100)更強的MI300X,但“實戰”搭環境可能會面臨無數個想不到的bug而被弄崩潰,適配的時間耗不起。
除了生態,另一個增加吸引力的槓桿是價格,追趕者需要藉助更高的性價比,來覆蓋開發者們的遷移成本。
當然,挖牆角並不是一件容易的事情,英偉達在商業策略上也有明確的反競爭機制,Semianalysis曾在研究報告中援引供應鏈人士的爆料,稱英偉達正在基於多重因素,對客戶進行不同優先級的產能分配。影響因素包括但不限於:存在多方採購的情況,自研AI芯片,捆綁採購英偉達其他產品。
在這種情況下,下場自研都會面臨訂單交付優先級下調的風險,更不用說在英偉達、AMD和Intel之間“騎牆”。
當然,這些都是對於存量用戶的爭搶。增量用戶面前,性價比就是Intel、AMD這些追趕者的強力武器,這個策略在英特爾身上表現的最爲明顯——今年的Intel Vision大會上,英特爾就秀了一波合作伙伴陣容,其中包括博世、Naver、SAP、Ola等等。
2、硅谷公司搶算力“上頭”
算力是硅谷巨頭們在AI時代的硬通貨,但他們手裏到底屯了多少顯卡,構建了什麼規模的算力?
研究機構Omdia的數據顯示,截至2023年第三季度,英偉達H100出貨量達到65萬張,其中$Meta Platforms (META.US)$和$微軟 (MSFT.US)$分別拿下15萬張,接近全部訂單的一半。如果按照單卡價格24000美元計算,截至到2023年第三季度,65萬張H100總計爲英偉達貢獻156億美元營收。
![截至到2023年Q3,H100的出貨量及主要科技公司儲備情況,來源:Omdia]() 截至到2023年Q3,H100的出貨量及主要科技公司儲備情況,來源:Omdia
截至到2023年Q3,H100的出貨量及主要科技公司儲備情況,來源:Omdia另外,Omdia數據還顯示,僅僅第三季度,英偉達的H100出貨量就達到50萬臺,價值120億美元。也就是說,硅谷巨頭們的訂單在第三季度得到了集中交付。交付量的增長與CoWoS封裝產能拉升呈正相關。公開數據顯示,$台積電 (TSM.US)$於去年4月、6月和10月,先後進行了多輪CoWoS設備加單,並且還對InFO封裝線改機以增加CoWoS產能。
需要注意,Omdia的數據只統計到第三季度,且不包含OpenAI,所以只做參考。實際上,各家H100的囤貨都在不斷上漲,硅谷巨頭們對算力的需求並不是虛張聲勢,而是用真金白銀兌現。
日前,馬斯克在$特斯拉 (TSLA.US)$電話會議上確認公司已經儲備3.5萬張H100。對照上面的圖表,這意味着特斯拉過去兩個季度新儲備2萬張H100。馬斯克在電話會議上還表示,到2024年年底,總計儲備量將達到8.5萬張。扎克伯格更早之前就宣佈計劃到2024年底,將H100的儲備量提升到35萬張,微軟則提出了更宏大的目標,到年底GPU儲備量翻一倍,達到180萬張,實際是在暗示目前已經屯了90萬張(感慨一下納德拉的鈔能力)。
買卡其實很好理解,但前有發佈間隔大半年的H200,後有性能更出衆的B200,硅谷巨頭們應該怎麼選?
有報道稱微軟將放棄採購H100,計劃搶奪50%的GB200訂單,可是問題在於,“算力核彈”B200現階段還屬於“期貨”。按照H200的交付節奏預估,包含台積電的邏輯芯片的生產及封裝,富士康和緯創的代工以及最終進入渠道,B200系列向客戶發貨最快也要到今年四季度。
黃仁勳給OpenAI交付全球第一臺DGX GH200,其目的也是在向市場表態,H200系列已具備量產交付能力,如果大家想要進入AGI時代,“鑰匙”就擺在這裏,而微軟喊“卡”,就意味着將算力拱手讓人。
爭搶算力在人類史上可能會是一個長期現象,只是大家都在喊着缺顯卡,缺算力,誰才是真正缺的那一位?
傅盛在騰訊科技的對話中提到過谷歌的案例,他說“如果一個谷歌研究員跟老闆說訓練一次2000萬美金,老闆問能不能做成?你說不知道,肯定就很難申請到資源。”
也就是說,對於一家商業化公司,當你的目標或者收益不夠明確時,想燒錢堆算力做大模型是一件很困難的時間,畢竟所有的資本支出要對股東、投資人負責,微軟和Meta瘋狂砸錢買卡,就是因爲商業回報已經有若隱若現的意思。
扎克伯格在2024財年一季度電話會議上說,“生成式AI可能要投資數年,才能實現有效盈利”,看起來是給投資者打預防針,但Meta的信息流、廣告推薦系統都已經清楚的看到投資回報。扎克伯格說,臉書30%的帖子來自AI推薦系統,Instagram更是達到了50%,而且兩個端到端人工智能工具Advantage+購物和Advantage+應用帶來的收入已經翻倍增長。
微軟的邏輯也差不多,剛剛公佈的2024年第三財季業績全面超預期,AI推動Azure雲收入加速增長了31%,貢獻的雲收入增幅提升至7個百分點,包含Copilot AI助手的Office商業收入增長15%。
如果真的說巨頭們信奉“規模法則”,強調“大力出奇跡”,至少微軟、Meta們還可以再加一個“不見兔子不撒鷹”的標籤。
![全球科技公司自研芯片佈局,來源:摩根史坦利]() 全球科技公司自研芯片佈局,來源:摩根史坦利
全球科技公司自研芯片佈局,來源:摩根史坦利當然,儲備算力,買或者說搶是一條路徑,自研則是另一條路徑,這可能會帶來數十億的採購和能耗成本的縮減。
不過,自研前期資本支出巨大,從投入到性能符合預期的產出兌現也需要時間,基本上科技公司都在採用自研+採購兩條腿走路的策略。
大摩此前提供了一份研究報告,資料顯示絕大部分科技公司在自研芯片上都有佈局(如上圖),包括谷歌的TPU,meta的MTIA,也包括國內大廠的相關項目。
長期看,自研確實可以消除算力焦慮,大摩對自研的總結是“單美元效率”更高,尤其是不追求最尖端工藝產品的情況下,“單美元效率”會更明顯。Semiannaly的“總擁有成本”也值得參考,該機構在研究報告中以GB200爲例,強調儘管Blackwell系列提供了更多浮點運算性能,但考慮到硅面積的增加,單位面積的性能並沒有顯著提升,而且隨着功率的提升,每瓦性能的提升幅度也會逐步下降。
還有一個終極問題,錢和卡都有了,電怎麼辦?
AI初創公司OpenPipe聯合創始人、CEO 凱爾·科比特援引一位微軟的工程師的觀點稱,“如果在一個州放置超過10萬張H100 GPU,電網就會崩潰。”那麼,卡不夠可以自研,電不夠,硅谷巨頭們又要下場佈局電力基礎設施?
3、“卡黃仁勳脖子”的兩隻手
硅谷巨頭缺卡又缺電,英偉達則缺CoWoS產能和HBM內存。
CoWoS被稱之爲2.5D封裝,簡單說就是將邏輯芯片、HBM內存通過硅中介層,再透過硅通孔技術,最後連接至PCB基板上,其英文全稱也就是Chip on Wafer on Substrate。
今年GTC,黃仁勳在面對全球媒體的採訪時,被問及CoWoS需求是去年三倍是否屬實時幽了一默,反問記者“你想要確切的數據,這很有趣。”
關於英偉達CoWoS需求的具體情況,黃仁勳不給小抄,就只能參考外界數據。
Digitimes援引設備廠的數據,稱台積電2023年全年CoWoS總產能逾12萬片,2024年將衝上24萬,英偉達將取得14.4萬-15萬片,佔臺積電總產能約60%左右。從Semianalysis跟蹤的數據來看(如下圖),2023年Q3英偉達的佔比大致在40-50%的區間。
另外,隨着台積電擴產及其他客戶需求增長,英偉達的CoWoS需求佔比也會被稀釋,去年11月份,台積電電話會議上確認英偉達佔臺積電CoWoS總產能的40%,基本和Semianalysis數據吻合。
![*Semianalysis提供的CoWoS產能分佈情況跟蹤和預測]() *Semianalysis提供的CoWoS產能分佈情況跟蹤和預測
*Semianalysis提供的CoWoS產能分佈情況跟蹤和預測而按月拆分,Digitimes還預測,台積電的今年一季度CoWoS產能將爬升到17000片/月,到年底有機會爬升到26000片-28000片/月。
按照CoWoS月產能17000片的數據來計算,如果英偉達可以拿到其中40%,即6800片,而一片12英寸的晶圓,大致可以切30張左右的H200,即台積電單月可完成20.4萬張H200的封裝。到年底,按照臺積電26000片/月的CoWoS產能,英偉達如果還是佔40%,即10400片/月,單月可以完成31.2萬張H200的封裝。
也就是說,英偉達在臺積電的助攻下,H200 GPU全年的封裝產能,下限可能是244萬張,上限有可能突破374萬張,按照24000美元的單價,價值在580億美元-890億美元之間。
雖然和台積電長期交好,但似乎黃仁勳並不滿足於當前的產能,也有消息說英偉達將在二季度向英特爾開出先進封裝訂單,預計月產能大概5000片左右,即單月封裝15萬張H200。
英偉達苦CoWoS產能久矣,同樣苦HBM產能久矣。以H100、H200都是標配了6顆HBM內存,而GB200更是搭配了8顆HBM3e內存,HBM內存不夠用了怎麼辦?
目前,HBM內存主要供應商有SK海力士、三星與美光,和先進封裝一樣,HBM廠商也在瘋狂擴產。
外媒援引韓國券商Kiwoom Securities的數據,稱$三星電子 (SSNLF.US)$的HBM內存月產能,預計將從2023年第二季的 2.5萬片晶圓增加到2025年第四季度的15-17萬片;同期,SK海力士的月產能預計將從3.5萬片爬升到12-14萬片,以此來估算,2024年全球HBM總產能70-75萬片左右。
以12層堆疊的HBM3e爲例,按照90%的良率,每片晶圓可以切750顆HBM,按照前面估算的70-75萬片年產能,預計全球2024年總計產出5200-5600萬顆HBM3e內存。而如果按前面的H200產能計算,每張GPU搭配6顆HBM內存,僅英偉達一家,對HBM內存的年需求總量大致在1460萬-2240萬顆區間。
如果SK海力士、三星和美光的HBM內存擴產順利,英偉達懸着的心基本可以放下一半的,另一半也要看AMD、英特爾以及自研的企業如何來搶產能了。
畢竟,也不能在下場自研AI芯片,蓋晶圓代工廠,建發電站這些想法出現之後,再給硅谷巨頭們安排新任務——下場蓋內存廠。
編輯/lambor