
【TechWeb】4月20日消息,近日,Meta重磅推出其80億和700億參數的Meta Llama 3開源大模型。該模型引入了改進推理等新功能和更多的模型尺寸,並採用全新標記器(Tokenizer),旨在提升編碼語言效率並提高模型性能。
在模型發佈的第一時間,英特爾即驗證了Llama 3能夠在包括英特爾至強處理器在內的豐富AI產品組合上運行,並披露了即將發佈的英特爾至強6性能核處理器(代號爲Granite Rapids)針對Meta Llama 3模型的推理性能。
英特爾至強處理器可以滿足要求嚴苛的端到端AI工作負載的需求。以第五代至強處理器爲例,每個核心均內置了AMX加速引擎,能夠提供出色的AI推理和訓練性能。截至目前,該處理器已被衆多主流雲服務商所採用。不僅如此,至強處理器在進行通用計算時,能夠提供更低時延,並能同時處理多種工作負載。
事實上,英特爾一直在持續優化至強平台的大模型推理性能。例如,相較於Llama 2模型的軟件,PyTorch及英特爾 PyTorch擴展包(Intel Extension for PyTorch)的延遲降低了5倍。這一優化是通過Paged Attention算法和張量並行實現的,這是因爲其能夠最大化可用算力及內存帶寬。下圖展示了80億參數的Meta Lama 3模型在AWS m7i.metal-48x實例上的推理性能,該實例基於第四代英特爾至強可擴展處理器。
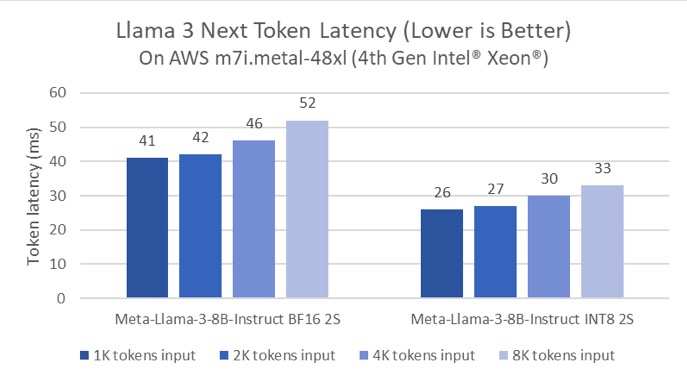
AWS實例上Llama 3的下一個Token延遲
不僅如此,英特爾還首次披露了即將發佈的產品——英特爾至強 6性能核處理器(代號爲Granite Rapids)針對Meta Llama 3的性能測試。結果顯示,與第四代至強處理器相比,英特爾至強6處理器在80億參數的Llama 3推理模型的延遲降低了2倍,並且能夠以低於100毫秒的token延遲,在單個雙路服務器上運行諸如700億參數的Llama 3這種更大參數的推理模型。
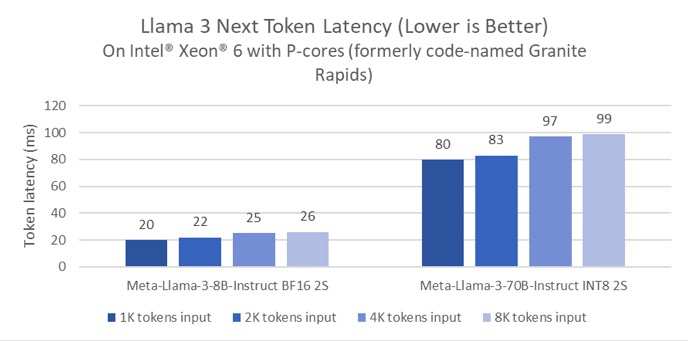
基於英特爾至強 6性能核處理器(代號Granite Rapids)的Llama 3下一個Token延遲
考慮到Llama 3具備更高效的編碼語言標記器(Tokenizer),測試採用了隨機選擇的prompt對Llama 3和Llama 2進行快速比較。在prompt相同的情況下,Llama 3所標記的token數量相較Llama 2減少18%。因此,即使80億參數的Llama 3模型比70億參數的Llama 2模型參數更高,在AWS m7i.metal-48xl實例上運行BF16推理時,整體prompt的推理時延幾乎相同(該評估中,Llama 3比Llama 2快1.04倍)。