
來源:華爾街見聞
“有史以來最強大的開源大模型”Llama 3引爆AI圈,馬斯克點贊,英偉達高級科學家Jim Fan直言,Llama 3將成爲AI大模型發展歷程的“分水嶺”,AI頂尖專家吳恩達稱Llama3是他收到的最好的禮物。
4月18日,AI圈再迎重磅消息,$Meta Platforms (META.US)$帶着號稱“有史以來最強大的開源大模型”Llama 3登場了。
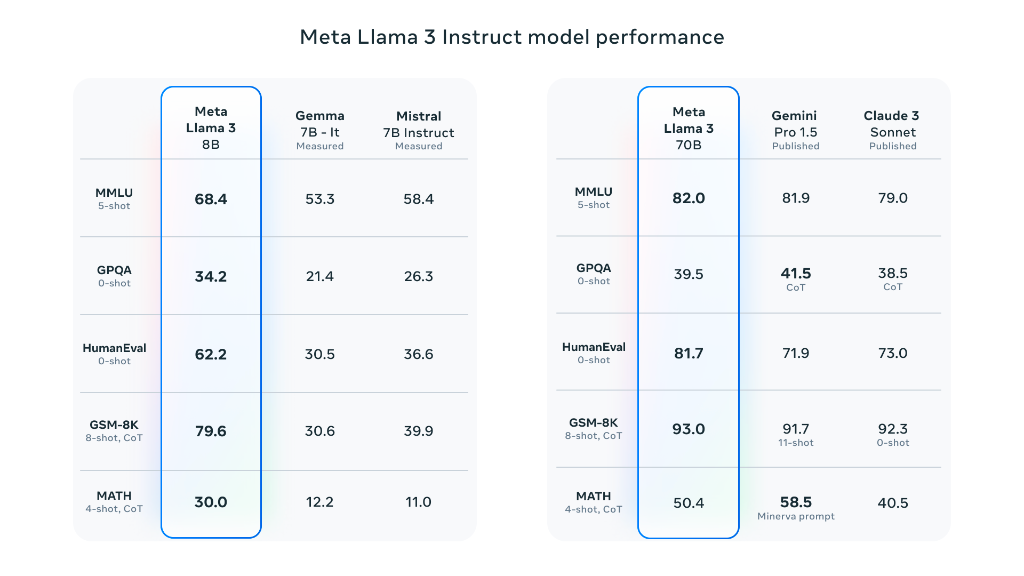
Meta本次開源了Llama 3 8B與70B兩款不同規模的模型,供外部開發者免費使用,未來幾個月,Meta 將陸續推出一系列具備多模態、多語言對話、更長上下文窗口等能力的新模型。其中,大版本的Llama 3將有超過4000億參數有望與Claude 3“一較高下”。
與此同時,Meta首席執行官扎克伯格宣佈,基於最新的Llama 3模型,Meta AI助手現在已經覆蓋Instagram、WhatsApp、Facebook等全系應用,並單獨開啓了網站,還有一個圖像生成器,可根據自然語言提示詞生成圖片。
Llama 3的出現直接對標OpenAI的GPT-4,與“並不Open”的OpenAI截然不同,在AI圈圍繞開源或閉源的路線爭論不休之時,Meta堅定沿着開源路線朝AGI的聖盃發起了衝鋒,爲開源模型扳回一局。
知情人士透露,研究人員尚未開始對Llama 3進行微調,還未決定Llama 3是否將是多模態模型。有消息稱,正式版的Llama 3將會在今年7月正式推出。
Meta AI 首席科學家、圖靈獎得主Yann LeCun一邊爲Llama 3的發佈“搖旗吶喊”,一邊預告未來幾個月將推出更多版本,稱Llama 3 8B和Llama 3 70B是目前同體量下,性能最好的開源模型。llama 3 8B在某些測試集上性能比llama 2 70B還要強。

就連馬斯克也現身於該評論區,一句簡潔的“Not bad”表達了對 Llama 3 的認可和期待。

英偉達高級科學家Jim Fan認爲,Llama 3的推出已經脫離了技術層面的進步,更是開源模型與頂尖閉源模型可分庭抗禮的象徵。
從Jim Fan分享的基準測試可以看出,Llama 3 400B 的實力幾乎媲美 Claude“超大杯”以及新版 GPT-4 Turbo,將成爲“分水嶺”,相信它將釋放巨大的研究潛力,推動整個生態系統的發展,開源社區或將能用上GPT-4級別的模型。

公佈當天恰逢斯坦福大學教授,AI頂尖專家吳恩達的生日,吳恩達直言,Llama 3的發佈是自己這輩子收到過的最好的禮物,謝謝你Meta!

OpenAI創始成員之一、特斯拉前AI總監Andrej Karpathy也對Llama 3表達了讚許。作爲大語言模型領域的先驅之一,Karpathy認爲Llama3的性能已接近GPT-4 的水平:
Llama3是Meta 發佈的看起來非常強大的模型。堅持基本原則,在可靠的系統和數據工作上花費大量高質量時間,探索長期訓練模型的極限。我也對 400B模型非常興奮,它可能是第一個 GPT-4 級別的開源模型。我想很多人會要求更長的上下文長度。
我希望能有比 8B 更小參數,理想規模在0.1B到1B左右的模型,用於教育工作、(單元)測試、嵌入式應用等。
Rebuy公司AI總監、深度學習領域的博士Cameron R. Wolfe認爲,Llama 3證明了訓練優秀大語言模型的關鍵在於數據質量。他詳細分析了Llama 3在數據方面做出的努力,包括:
1)15萬億個token的預訓練數據: 比Llama 2多7倍,比DBRX的12萬億個還要多;
2)更多代碼數據: 預訓練過程中包含更多代碼數據,提升了模型的推理能力;
3)更高效的tokenizer: 擁有更大的詞彙表(128K tokens),提高了模型的效率和性能。
在Llama 3發佈後,小扎向媒體表示,“我們的目標不是與開源模型競爭,而是要超過所有人,打造最領先的人工智能。”未來,Meta團隊將會公佈Llama 3的技術報告,披露模型更多的細節。
這場關於開源與閉源的辯論還遠未結束,暗中蓄勢待發的 GPT-4.5/5 也許會在今年夏天到來,AI領域的大模型之戰還在上演。
編輯/tolk