業務に関わる映像とドキュメントから空間把握能力と時系列理解能力を強化
当社は、このほど、AIサービス「Fujitsu Kozuchi」のコア技術として、製造、物流などの現場に設置されたカメラ映像を空間認識し解析するとともに作業指示や規則などのドキュメント情報を参照することで、自律的に現場改善の提案や作業レポートの作成を行い、人の作業を支援する映像解析型AIエージェントを開発しました。当社は、開発したAIエージェントを用いて2025年1月より社内実践を行うとともに、2024年度中に映像解析型AIエージェントのトライアル環境の提供を開始します。また今後、店舗、交通、公共安全などの様々な分野への技術展開も進めていきます。
開発したAIエージェントでは、マルチモーダル(注1)大規模言語モデル(以下、マルチモーダルLLM)をベースとし、安全規則などのドキュメント情報をもとに現場の3次元空間を映像認識する能力を獲得する自己学習技術と、ドキュメントのコンテキストが示す対象部分を映像から選択し記憶することにより、長時間の映像を世界最高精度(注2)で解析することを可能にしたコンテキスト記憶技術を搭載しています。
さらに、AIエージェントの性能評価を目的に、工場や倉庫の現場映像を含むAIエージェントの評価環境「FieldWorkArena(フィールドワークアリーナ)」を、米国のCarnegie Mellon University(注3)(以下、カーネギーメロン大学)の監修のもと開発しました。2024年12月より、「FieldWorkArena」の公開をGitHub(注4)およびFujitsu Research Portalにおいて開始する予定です。
背景
 製造や物流をはじめとする現場において人材不足や熟練者の高齢化が進む中、生産性や品質を確保しながら、働きやすく安心・安全な現場づくりを実現していくことが課題となっています。人と協調するAIエージェントは、デスクワークや会話支援において大きな広がりを見せていますが、現場作業の支援に向けてはさらなる進化が求められています。
製造や物流をはじめとする現場において人材不足や熟練者の高齢化が進む中、生産性や品質を確保しながら、働きやすく安心・安全な現場づくりを実現していくことが課題となっています。人と協調するAIエージェントは、デスクワークや会話支援において大きな広がりを見せていますが、現場作業の支援に向けてはさらなる進化が求められています。
開発技術
開発した映像解析型AIエージェントは、以下の特長を備えています。
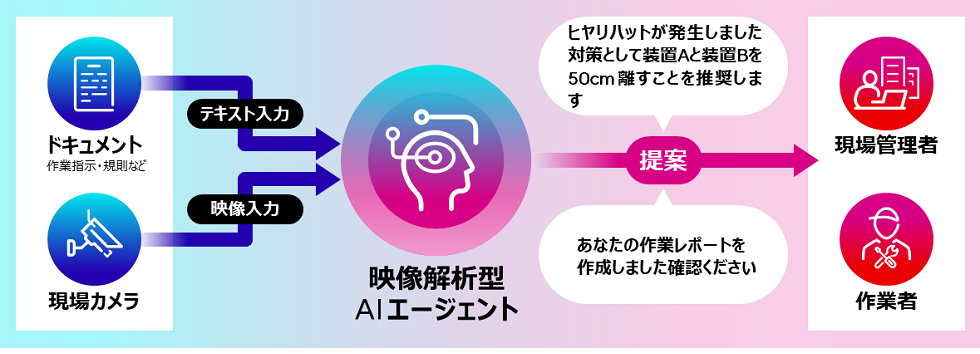 図1:映像解析型AIエージェント
図1:映像解析型AIエージェントドキュメント情報をもとに現場理解能力の拡張を行う自己学習技術
人間は初めて見る物や場所でも、指示書などの言語情報をもとに視覚情報を理解し、作業を行うことができます。本技術では、マルチモーダルLLMが映像から認識できない事象について、ドキュメントの言語情報を対応付けて学習し、AIエージェントの映像理解能力を拡張することができます。図2は、人と物との空間的関係性の理解能力を拡張する例です。まず、ドキュメントに含まれる対象物を選択し、機械学習により対象物との距離を推定して3次元データを仮想空間上に作成します。次に、ドキュメントから作成した質問と、3次元データからわかる回答を作成し、それらを学習データとしてマルチモーダルLLMをファインチューニングします。この技術を用いて人と物体の距離を3次元で推定することで、物流や建設の現場における安全管理や、製造現場における作業状況の生産管理システムへの自動入力などを実現します。また、空間理解能力に加え、現場固有の物体認識、人の個別作業の認識など、現場作業支援に必要な様々な能力をAIエージェントに追加できるようになります。
 図2:現場理解能力の追加学習の例
図2:現場理解能力の追加学習の例映像を効率的に解析するコンテキスト記憶技術
マルチモーダルLLMでは、サイズの大きい長時間の映像を入力する際にフレームを間引くため、時系列で変化のある映像を分析する際に回答の精度が落ちるという問題がありました。この問題を解決するために着目したのが、重要な情報に注意を集中することで効率的に視覚情報を処理する、人間の「選択的注意」というメカニズムです。本技術では、対象映像の中でAIエージェントのタスクで検知したい「人の安全行動」などの主題をプロンプトとして与えると、「選択的注意」により、主題に適合するフレーム内の特徴量のみを選択し、圧縮して映像コンテキストメモリとしてビデオメモリに格納します。映像コンテキストメモリを用いることで、フレームを間引くことなく長時間映像をマルチモーダルLLMが扱えるようになります。2時間以上の映像を含む長時間映像に対する質問回答のベンチマークを行った結果、開発方式は従来のマルチモーダルLLM向けの映像圧縮技術と比較して最小の記憶容量で世界最高の回答精度を達成しました。
![big]() 図3:選択的注意機構を用いた映像のコンテキスト記憶
図3:選択的注意機構を用いた映像のコンテキスト記憶AIエージェント評価環境「FieldWorkArena」
当社は、映像解析型AIエージェントのための評価環境「FieldWorkArena」を、カーネギーメロン大学のグラム・ニュービッグ准教授、ヨナタン・ビスク助教授のチームの監修のもと開発しました。「FieldWorkArena」には、実際の工場や倉庫の画像や映像、規則や手順書などのドキュメント、模擬の業務システム、AIエージェントが解決すべきタスク群が含まれ(図4)、AIエージェントの実業務での性能を評価することができます。
![big]() 図4:「FieldWorkArena」のデータ、タスク例
図4:「FieldWorkArena」のデータ、タスク例商標について
記載されている製品名などの固有名詞は、各社の商標または登録商標です。
注釈
注1
マルチモーダル:
複数の形式や手段を組み合わせること。
注2
世界最高の回答精度を実現:
長時間映像理解ベンチマークInfiniBenchのうち、映像情報のみで回答可能な599のサブセット(平均49分・最大151分の映像)に対しての回答精度で世界最高記録を達成(2024年12月12日現在)
注3
Carnegie Mellon University:
所在地 米国ペンシルベニア州、学長 Farnam Jahanian
注4
GitHub:
世界中でオープンソースソフトウェアの公開に使われているプラットフォーム。
関連リンク
- GitHub FieldWorkArenaページ
- Fujitsu Research Portal
- Fujitsu Kozuchi
- Fujitsu TECH BLOG
当社のSDGsへの貢献について
2015年に国連で採択された持続可能な開発目標(Sustainable Development Goals:SDGs)は、世界全体が2030年までに達成すべき共通の目標です。当社のパーパス(存在意義)である「イノベーションによって社会に信頼をもたらし、世界をより持続可能にしていくこと」は、SDGsへの貢献を約束するものです。
本件が貢献を目指す主なSDGs![big]()
本件に関するお問い合わせ
プレスリリースに記載された製品の価格、仕様、サービス内容などは発表日現在のものです。その後予告なしに変更されることがあります。あらかじめご了承ください。
通過與業務相關的圖像和文檔強化空間感知能力和時間序列理解能力
我們最近開發了AI服務「富士通Kozuchi」的核心技術,能夠分析安裝在製造、物流等現場攝像機的圖像,參考作業指示和規章等文檔信息,自動提出現場改善建議並生成作業報告,從而支持人的作業。這款圖像分析型AI代理將在2025年1月開始進行內部實踐,並將在2024財政年度內啓動圖像分析型AI代理的試用環境。此外,我們還將向店鋪、交通、公共安全等各個領域推進技術應用。
開發的AI代理基於多模態(注1)大規模語言模型(以下簡稱多模態LLM),通過基於安全規章等文檔信息,獲取現場三維空間的圖像識別能力,具備自我學習技術,同時通過選擇和記憶文檔上下文所指示的目標部分,能夠以世界最高精度(注2)分析長時間的圖像,搭載了上下文記憶技術。
爲了評估AI代理的性能,我們開發了包括工廠和倉庫現場圖像的AI代理評估環境「FieldWorkArena(現場工作競技場)」,並在美國卡內基梅隆大學(注3)的指導下進行開發。預計從2024年12月開始在GitHub(注4)和富士通研究門戶網站發佈「FieldWorkArena」。
背景
 在製造和物流等現場,人才短缺和熟練工高齡化日益嚴重,確保生產力和質量的同時,實現一個更加便捷、安全的工作環境已經成爲一個挑戰。與人協調的AI代理在辦公室工作和對話支持方面顯示出巨大潛力,但在現場作業支持方面仍需進一步發展。
在製造和物流等現場,人才短缺和熟練工高齡化日益嚴重,確保生產力和質量的同時,實現一個更加便捷、安全的工作環境已經成爲一個挑戰。與人協調的AI代理在辦公室工作和對話支持方面顯示出巨大潛力,但在現場作業支持方面仍需進一步發展。
開發技術
開發的圖像分析型AI代理具備以下特徵。
圖1:視頻解析型AI代理
基於文檔信息進行現場理解能力擴展的自我學習技術
人類雖然第一次見到某物或某地,但能夠根據指示書等語言信息理解視覺信息並進行操作。本技術利用多模態LLM對視頻中無法識別的事件,通過文檔的語言信息進行關聯學習,擴展AI代理的視頻理解能力。圖2是擴展人與物之間空間關係理解能力的例子。首先,選擇文檔中包含的目標物體,通過機械學習估計與目標物體的距離,並在虛擬空間中生成三維數據。接下來,從文檔中生成問題,並依據三維數據生成能夠回答的問題,將這些作爲學習數據對多模態LLM進行微調。通過使用此技術以三維方式估計人與物體之間的距離,可實現運輸和施工現場的安全管理,以及製造現場工作狀態的生產管理系統的自動輸入等。此外,除了空間理解能力外,還可以向AI代理增加現場特有的物體識別、人類個別工作的識別等現場作業支持所需的各種能力。
圖2:現場理解能力的追加學習的例子
有效解析視頻的上下文記憶技術
在多模態LLM中,輸入大尺寸長時間視頻時需要間隔掉一些幀,這導致在分析時序變化的視頻時,回答的準確性下降。爲了解決這個問題,我們關注了通過集中注意重要信息而有效處理視覺信息的人類「選擇性注意」機制。本技術中,給定AI代理任務中希望檢測的「人類安全行爲」等主題作爲提示,通過「選擇性注意」,僅選擇符合主題的幀內特徵量並進行壓縮,存儲爲視頻上下文記憶。在使用視頻上下文記憶的情況下,多模態LLM能夠處理長時間視頻而不間隔幀。對包含兩小時以上視頻的長時間視頻進行問答的商品測試結果表明,該開發方式在最小存儲容量下,實現了世界最高的回答精度,相較於傳統的多模態LLM視頻壓縮技術。
![大]()
圖3:使用選擇性注意機制的影像上下文記憶
AI代理評估環境「FieldWorkArena」
我們開發了用於影像解析型AI代理的評估環境「FieldWorkArena」,在卡內基梅隆高校的格拉姆·紐比格副教授和約納坦·比斯克助教授團隊的指導下。「FieldWorkArena」包含實際工廠和倉庫的圖像和視頻、規章制度和程序文件等文檔、模擬的業務系統以及AI代理需要解決的任務群(圖4),可以評估AI代理在實際業務中的性能。
![大]()
圖4:「FieldWorkArena」的數據,任務示例
關於商標
文中提到的產品名稱等專有名詞均爲各公司的商標或註冊商標。
註釋
相關鏈接
- GitHub FieldWorkArena頁面
- 富士通研究門戶
- 富士通小土
- 富士通技術博客
關於我們對SDGs的貢獻
2015年在聯合國通過的可持續發展目標(Sustainable Development Goals:SDGs)是全球在2030年前必須實現的共同目標。我們存在的意義是通過創新給社會帶來信賴,讓世界變得更加可持續,這承諾了我們對SDGs的貢獻。
本項目的主要目標是推動SDGs的貢獻
![大]()
有關本件的諮詢
在新聞稿中列出的產品價格、規格、服務內容等爲發佈日現有的信息,之後可能會在不通知的情況下進行變更,敬請諒解。

 圖3:使用選擇性注意機制的影像上下文記憶
圖3:使用選擇性注意機制的影像上下文記憶 圖4:「FieldWorkArena」的數據,任務示例
圖4:「FieldWorkArena」的數據,任務示例

