
 自从OpenAI 的Sora 基于 DiT(Diffusion Transformer)架构,把长视频生成的效果提高到了前所未有的水平,全球AI厂商加速赶来,掀起视频生成热潮。
自从OpenAI 的Sora 基于 DiT(Diffusion Transformer)架构,把长视频生成的效果提高到了前所未有的水平,全球AI厂商加速赶来,掀起视频生成热潮。①騰訊混元大模型正式上線視頻生成能力,並開源該視頻生成大模型,參數量130億,這是當前最大的視頻開源模型。②騰訊認爲,當下的視頻生成,還未到大規模商用的階段,還有很多技術難點需要克服,混元文生視頻當下階段更重要的是開源讓更多人「用起來」,使模型的飛輪能快速轉動帶動優化模型本身。
《科創板日報》12月4日訊(記者 張洋洋)昨日,騰訊混元大模型正式上線視頻生成能力,這是繼文生文、文生圖、3D生成之後,混元大模型的最新業務進展。與此同時,騰訊開源該視頻生成大模型,參數量130億,是當前最大的視頻開源模型。
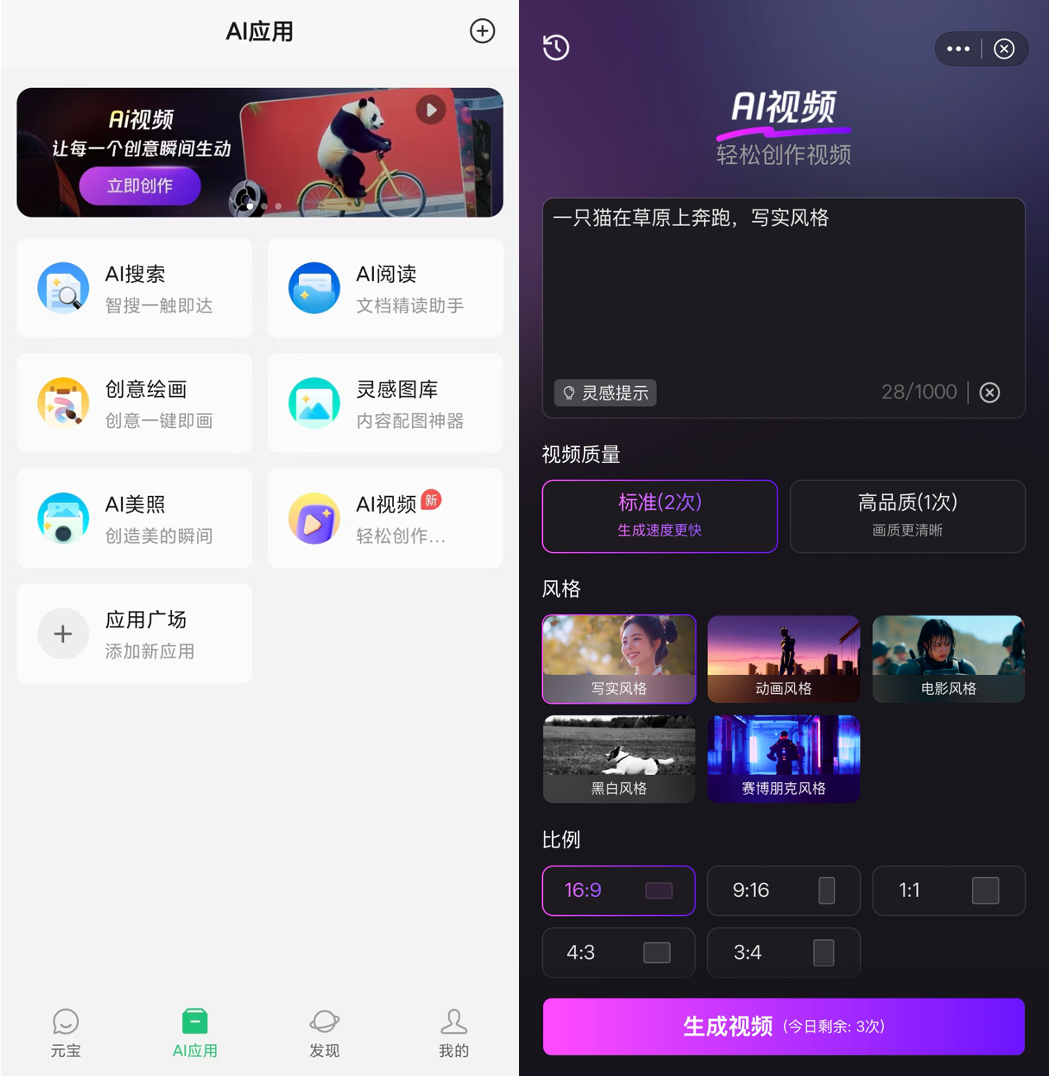
「用戶只需要輸入一段描述,即可生成視頻,」騰訊混元相關負責人透露,目前的生成視頻支持中英文雙語輸入、多種視頻尺寸以及多種視頻清晰度。目前該模型已上線騰訊元寶APP,用戶可在AI應用中的「AI視頻」板塊申請試用。企業用戶通過騰訊雲提供服務接入,目前API同步開放內測申請。
 自從OpenAI 的Sora 基於 DiT(Diffusion Transformer)架構,把長視頻生成的效果提高到了前所未有的水平,全球AI廠商加速趕來,掀起視頻生成熱潮。
自從OpenAI 的Sora 基於 DiT(Diffusion Transformer)架構,把長視頻生成的效果提高到了前所未有的水平,全球AI廠商加速趕來,掀起視頻生成熱潮。
2024年接近尾聲,今年以來大模型領域最熱鬧的細分賽道要數視頻生成。字節豆包正在推出文生視頻內測,Minmax,快手,商湯等也先後推出了文生視頻。由清華大學聯合生數科技共同研發Vidu 則宣稱是中國首個長時長、高一致性、高動態性視頻大模型。
不過,做好文生視頻這件事並不簡單,這一點從OpenAI在今年初發布了Sora之後,仍未正式對外開放便可見一斑。
這主要是因爲當前的視頻生成技術產出的結果與用戶期望之間仍存在較大差距,這些模型在理解和應用物理規則方面表現不足,並且在生成過程中缺乏有效的可控性。
按照騰訊的說法,混元文生視頻大模型主要的優勢能力在於,可以實現超寫實畫質、生成高度符合提示詞的視頻畫面,畫面流暢不易變形。
「比如,在衝浪、跳舞等大幅度運動畫面的生成中,騰訊混元可以生成非常流暢、合理的運動鏡頭,物體不易出現變形;光影反射基本符合物理規律,在鏡面或者照鏡子場景中,可以做到鏡面內外動作一致。同時,模型還可以實現在畫面主角保持不變的情況下自動切鏡頭,這是業界大部分模型所不具備的能力。」
從技術角度來看,據騰訊混元相關負責人介紹,混元大模型基於跟Sora類似的DiT架構,在架構設計上進行了多處升級。
混元視頻生成模型適配了新一代文本編碼器提升語義遵循,其具備強大的語義跟隨能力,更好地應對多個主體描繪,實現更加細緻的指令和畫面呈現;採用統一的全注意力機制,使得每幀視頻的銜接更爲流暢,並能實現主體一致的多視角鏡頭切換;通過先進的圖像視頻混合VAE(3D 變分編碼器),讓模型在細節表現有明顯提升,特別是小人臉、高速鏡頭等場景。
比如寫下這麼一段提示詞,一位中國美女穿着漢服,頭髮飄揚,背景是倫敦,然後鏡頭切換到特寫鏡頭:

不過在視頻生成領域,快手、抖音、智譜科技、生數科技等國內廠商均已推出相應的產品,甚至開啓了商業化,騰訊混元此番的節奏並不算快。
對此,騰訊混元相關負責人在接受《科創板日報》記者採訪時回應稱,當下的視頻生成技術,從可用度而言,還未到大規模商用的階段,還有很多技術難點需要克服,混元大模型文生視頻功能也並不急於一時,當下階段更重要的是開源讓更多人用起來,使模型的飛輪能快速轉動帶動優化模型本身。
在落地應用上,上述負責人表示,混元大模型生成的視頻可用於工業級商業場景,例如廣告宣傳、動畫製作、創意視頻生成等場景。對於未來的商業化,騰訊暫時還沒有詳細的規劃出來。
目前,騰訊宣佈開源該視頻生成大模型已在 Hugging Face平台及Github上發佈,包含模型權重、推理代碼、模型算法等完整模型,可供企業與個人開發者免費使用和開發生態插件。基於騰訊混元的開源模型,開發者及企業無需從頭訓練,即可直接用於推理,並可基於騰訊混元系列打造專屬應用及服務。
