
 值得一提的是,Bezos Expeditions的实控人为
值得一提的是,Bezos Expeditions的实控人为來源:半導體行業觀察
近日,由行業知名人士Jim Keller擔任CEO的Tenstorrent宣佈完成由三星證券和 AFW Partners 領投的 6.93 億美元 D 輪融資。在這輪融資之後,這家 AI 芯片初創公司的估值約爲 26 億美元。
Tenstorrent 創始人兼半導體先驅 Jim Keller 在接受採訪時表示,該公司希望開發一款芯片,試圖打破 $英偉達 (NVDA.US)$ 對 AI 業務的壟斷,該公司在由韓國 AFW Partners 和三星證券領投的一輪融資中籌集了資金。Bezos Expeditions 與 LG Electronics Inc. 和 Fidelity 聯手參與了這輪融資,看好 Keller 的實力和人工智能技術領域的蓬勃發展機會。
 值得一提的是,Bezos Expeditions的實控人爲$亞馬遜 (AMZN.US)$創始人Jeff Bezos。考慮到AWS對英偉達芯片的採購量,可以看到這個投資背後的深層次含義。
值得一提的是,Bezos Expeditions的實控人爲$亞馬遜 (AMZN.US)$創始人Jeff Bezos。考慮到AWS對英偉達芯片的採購量,可以看到這個投資背後的深層次含義。
除了領投方之外,許多知名投資者也參與了此輪融資,其中包括 XTX Markets、Corner Capital、MESH、加拿大出口發展局、安大略省醫療養老金計劃、LG 電子、現代汽車集團、富達管理與研究公司、Baillie Gifford、Bezos Expeditions 等。
Tenstorrent方面表示,由於投資者需求強勁,該輪融資獲得超額認購。Jim Keller 在接受採訪時更是表示,該公司希望開發一款芯片,試圖打破 Nvidia 對 AI 業務的壟斷。

Tenstorrent是誰?
關於誰是Jim Keller,媒體已經做了很多報道,我們就不再多言。《Jim Keller的芯片研發封神之路》可以看到其光輝的履歷。至於Tenstorrent,則是一家由Jim Keller支持並擔任CEO的公司。
Tenstorrent 總部位於加利福尼亞州聖克拉拉,主要開發和銷售專爲 AI 工作負載而設計的計算系統,這些系統均圍繞該公司的 Tensix 核心開發。該公司的願景是打破 Nvidia 在芯片硅片市場的壟斷,設計出更實惠的 AI 訓練和部署硬件,避免使用 Nvidia 使用的高帶寬內存等昂貴組件。
「如果你使用 HBM,你就無法擊敗 Nvidia,因爲 Nvidia 購買的 HBM 最多,而且具有成本優勢,」Jim Keller在接受彭博社採訪時候說。「但他們永遠無法像 HBM 內置到他們的產品和插槽中那樣降低價格。」
衆所周知,Nvidia 爲開發人員提供了全套專有技術,涵蓋從芯片到互連甚至數據中心佈局的方方面面,並承諾所有部件都能更好地工作,因爲它們是協同設計的。而競爭對手 AMD和 Tenstorrent 等公司則致力於與其他技術提供商實現更大的互操作性,無論是通過共享行業標準還是開放設計供他人使用。
爲了吸引更多潛在客戶,該公司專注於與其他供應商進行可互操作的硬件設計。它使用開放標準的RISC-V 處理器架構,旨在爲工程師和開發人員提供一個更開放的生態系統,以便將其處理器和系統應用於他們的數據中心和服務器設置。「過去,我使用專有技術,這真的很艱難,」Jim Keller 說。「開源可以幫助你構建更大的平台。它吸引了工程師。是的,這是一個充滿激情的項目。」
爲了實現這一目標,Tenstorrent將 AI 和 RISC-V 知識產權授權給想要擁有和定製專用芯片的客戶。RISC-V 是一種開源指令架構,用於基於所謂的「精簡指令集」爲不同應用開發定製處理器,這使得它非常易於使用、定製和優化功率、性能和功能。
與 RISC-V 和日本合作伙伴 Rapidus一樣,Tenstorrent 仍有很多需要證明的地方。迄今爲止,這家新興公司已與客戶簽訂了總額近 1.5 億美元的合同,與 Nvidia 每季度數百億美元的數據中心收入相比,這相形見絀。
該公司表示,將利用新資金構建開源 AI 軟件堆棧,並聘請開發人員來擴大全球開發和設計中心。這將使該公司能夠構建系統和雲,供 AI 開發人員在其系統上使用和測試模型。
Tenstorrent 表示,其首批芯片由 $GlobalFoundries (GFS.US)$製造,下一代芯片將來自臺灣半導體制造公司和三星電子公司。該公司還開始爲尖端的 2 納米制造進行設計。$台積電 (TSM.US)$和三星將於明年開始大規模生產,Tenstorrent 正在與他們以及日本的 Rapidus 進行談判,後者的目標是在 2027 年實現 2 納米產量。
XTX Markets 首席技術官 Joshua Leahy 表示:「我們發現 Tenstorrent 的開源驅動方法令人耳目一新,尤其是在專有且通常保密的 AI 加速器領域。」
隨着公司開始利用新資金擴大規模,它將在 Nvidia 佔據優勢的市場中面臨阻力。然而,Jim Keller 仍然相信,通過提供更實惠、可以根據業務需求量身定製的 AI 芯片,並每兩年發佈一款新處理器,可以幫助該公司在 AI 芯片行業保持商業上可行的產品。
在接受媒體採訪的時候,Jim Keller曾總結說:
Tenstorrent 是一家設計公司。我們設計CPU,我們設計人工智能引擎,我們設計人工智能軟件堆棧。
因此,無論是軟 IP、硬 IP chiplet還是完整芯片,這些都是實現。我們在這方面很靈活。例如,在 CPU 上,我們將在我們自己的chiplet流片之前對其進行多次許可。我們正在與六家想要從事定製內存芯片或 NPU 加速器等業務的公司進行交談。我認爲對於我們的下一代,無論是 CPU 還是 AI,我們將構建 CPU 和 AI chiplet。但隨後其他人會做其他的小芯片。然後我們會將它們整合到系統中。
憑啥挑戰英偉達?
從上面的介紹中,我們分享了Tenstorrent的願景。接下來,我們了解一下這家公司的產品和路線圖。
在2023年三月,Tenstorrent 的首席 CPU 架構師 Wei-Han Lien 在接受媒體採訪的時候就表示,由於 Tenstorrent 着眼於解決廣泛的 AI 應用問題,因此它不僅需要不同的片上系統或系統級封裝,還需要各種 CPU 微架構實現和系統級架構,以實現不同的功率和性能目標。
Tenstorrent 表示,公司的CPU 團隊開發了一種無序 RISC-V 微架構,並以五種不同的方式實現它,以滿足各種應用的需求。
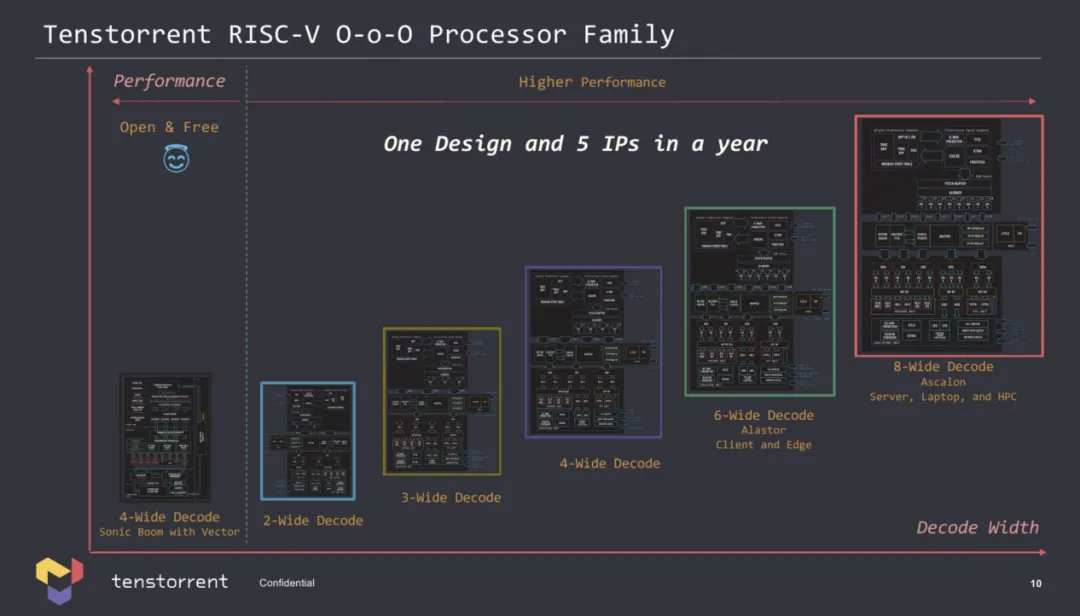
Tenstorrent 現在有五種不同的 RISC-V CPU 核心 IP,包括雙寬、三寬、四寬、六寬和八寬解碼,可用於自己的處理器或授權給感興趣的各方。對於那些需要非常基本的 CPU 的潛在客戶,該公司可以提供具有雙寬執行能力的小核心,但對於那些需要更高性能用於邊緣、客戶端 PC 和高性能計算的客戶,它有六寬 Alastor 和八寬 Ascalon 核心。
每個具有八寬解碼的無序 Ascalon ( RV64ACDHFMV ) 核心都有六個 ALU、兩個 FPU 和兩個 256 位矢量單元,因此非常強大。考慮到現代 x86 設計使用四寬 (Zen 4) 或六寬 (Golden Cove) 解碼器,我們看到的是一個功能非常強大的核心。

除了各種 RISC-V 通用核心外,Tenstorrent 還擁有專爲神經網絡推理和訓練量身定製的專有 Tensix 核心。每個 Tensix 核心由五個 RISC 核心、一個用於張量運算的數組數學單元、一個用於矢量運算的 SIMD 單元、1MB 或 2MB 的 SRAM 以及用於加速網絡數據包操作和壓縮/解壓縮的固定功能硬件組成。Tensix 核心支持多種數據格式,包括 BF4、BF8、INT8、FP16、BF16 甚至 FP64。

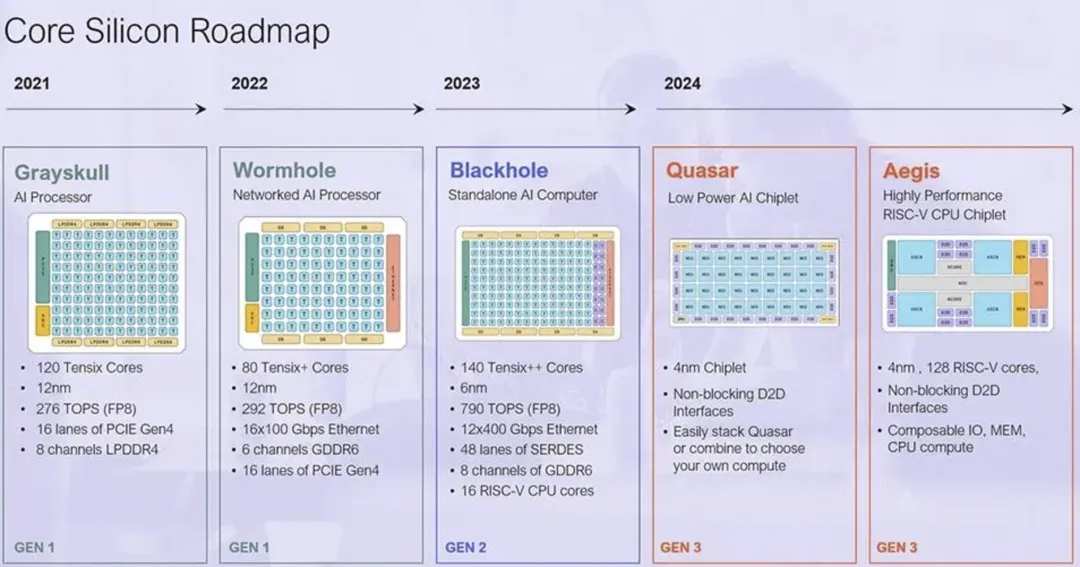
截止2023年三月,Tenstorrent 有兩種產品:一種名爲 Grayskull 的機器學習處理器,提供約 315 INT8 TOPS 的性能,可插入 PCIe Gen4 插槽;另一種是聯網的 Wormhole ML 處理器,性能約爲 350 INT8 TOPS,使用 GDDR6 內存子系統、PCIe Gen4 x16 接口,並與其他機器建立 400GbE 連接。

這兩種設備都需要主機 CPU,可作爲附加板使用,也可內置於預置的 Tenstorrent 服務器中。一臺 4U Nebula 服務器包含 32 張 Wormhole ML 卡,可提供約 12 個 INT8 POPS 的性能,功率爲 6kW。
在今年八月舉辦的 Hot Chips 上,Tenstorrent披露了Blackhole AI 加速器進行。與之前作爲基於 PCIe 的加速器部署的 Greyskull 和 Wormhole 部件不同,Tenstorrent 的 Blackhole旨在作爲獨立的 AI 計算機運行。
他們聲稱,該加速器在原始計算和可擴展性方面可以勝過 Nvidia A100。據介紹,每個 Blackhole 芯片都擁有 745 teraFLOPS 的 FP8 性能(FP16 爲 372 teraFLOPS)、32GB 的 GDDR6 內存和基於以太網的互連,能夠在其 10 個 400Gbps 鏈路上實現 1TBps 的總帶寬。
Tenstorrent 展示了其最新芯片如何在性能上比 Nvidia A100 GPU 略有優勢,儘管在內存容量和帶寬方面都落後。然而,就像 A100 一樣,Tenstorrent 的 Blackhole 旨在作爲橫向擴展系統的一部分進行部署。這家 AI 芯片初創公司計劃將 32 個 Blackhole 加速器以 4x8 網格的形式連接起來,塞進一個節點,並將其稱爲 Blackhole Galaxy。
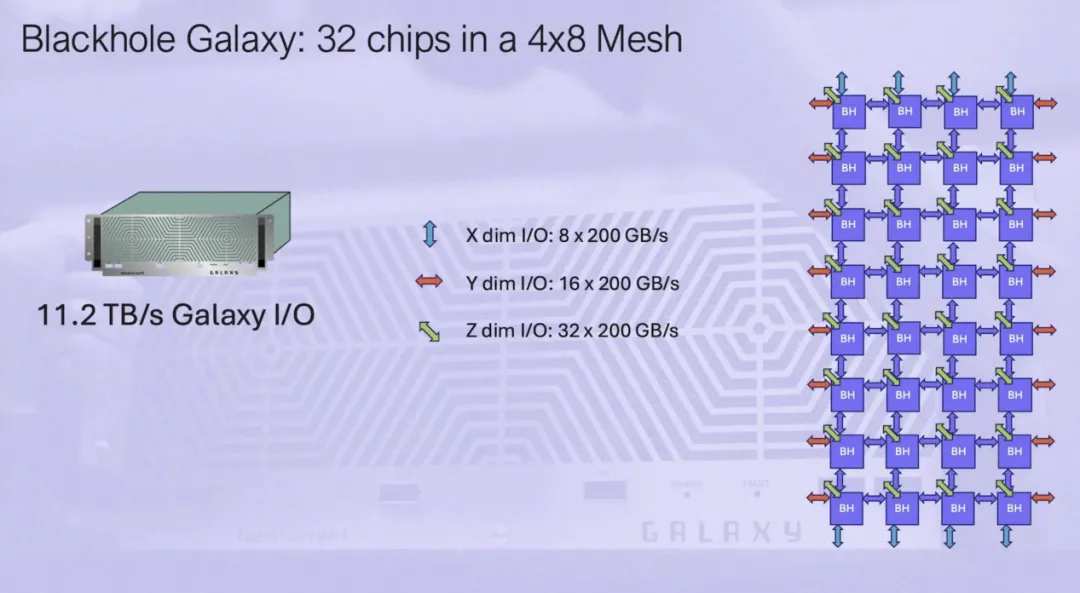
總體而言,單個 Blackhole Galaxy 承諾 FP8 的 23.8 petaFLOPS 或 FP16 的 11.9 petaFLOPS,以及能夠提供 16 TBps 原始帶寬的 1TB 內存。此外,Tenstorrent 表示,該芯片的核心密集型架構(我們稍後會深入探討)意味着這些系統中的每一個都可以用作計算或內存節點,或用作高帶寬 11.2TBps 的 AI 交換機。
Tenstorrent 人工智能軟件和架構高級研究員 Davor Capalija 表示:「你可以用它作爲樂高積木來搭建整個訓練集群。」
值得一提的是。Tenstorrent 使用板載以太網,這意味着它避免了在芯片到芯片和節點到節點網絡中處理多種互連技術所帶來的挑戰,而 Nvidia 則必須使用 NVLink 和 InfiniBand/以太網。在這方面,Tenstorrent 的橫向擴展策略與英特爾的Gaudi 平台非常相似,後者也使用以太網作爲其主要互連。考慮到 Tenstorrent 計劃在一個盒子裏塞入多少個 Blackhole 加速器,更不用說一個訓練集群,看看它們如何處理硬件故障將會很有趣。
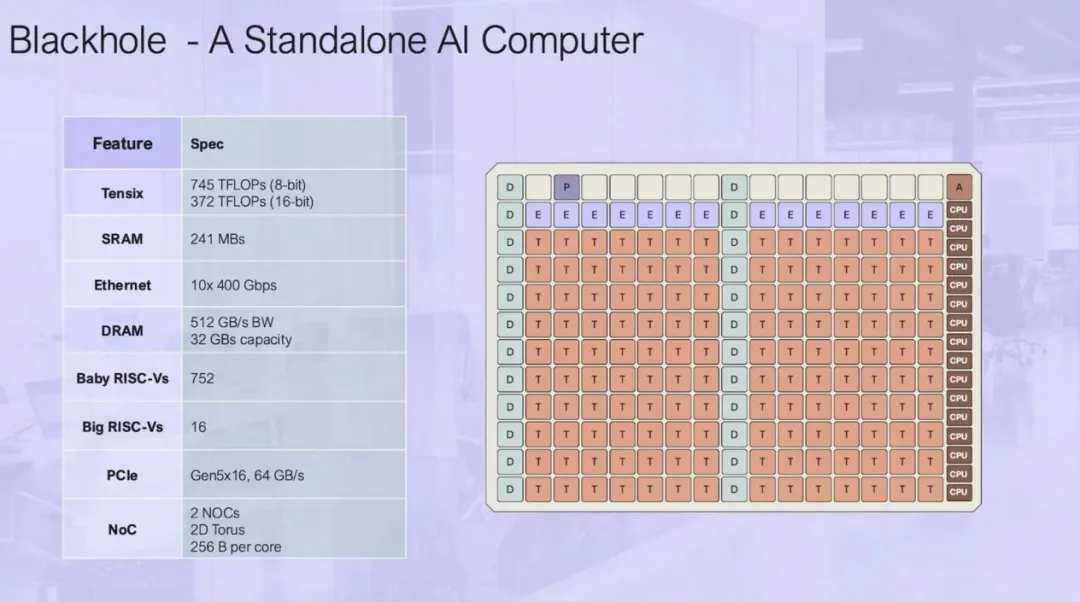
Tenstorrent 表示,Blackhole之所以能作爲獨立的 AI 計算機運行,主要歸功於 16 個「Big RISC-V」64 位、雙發射、有序 CPU 核心,這些核心排列在四個集群中。至關重要的是,這些核心足夠強大,可以作爲運行 Linux 的設備主機。這些 CPU 核心與 752 個「Baby RISC-V」核心配對,後者負責內存管理、片外通信和數據處理。
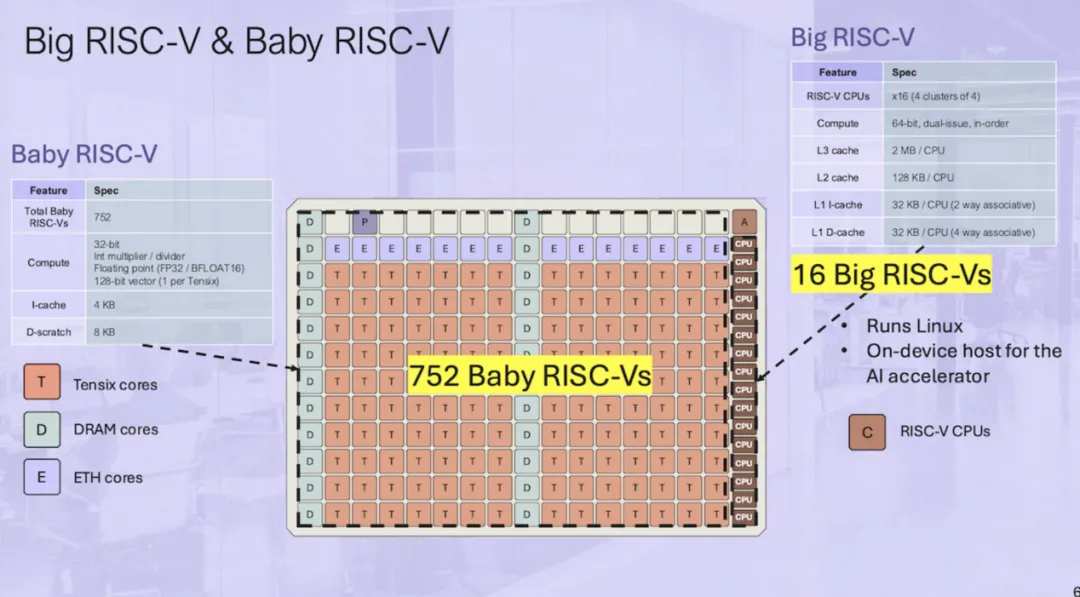
然而,實際計算是由 Tenstorrent 的 140 個 Tensix 核心處理的,每個核心由五個「Baby RISC-V」核心、一對路由器、一個計算綜合體和一些 L1 緩存組成。
計算綜合體由一個用於加速矩陣工作負載的圖塊數學引擎和一個矢量數學引擎組成。前者將支持 Int8、TF32、BF/FP16、FP8 以及 2 到 8 位的塊浮點數據類型,而矢量引擎則以 FP32、Int16 和 Int32 爲目標。
據他們所說,這種配置意味着該芯片可以支持 AI 和 HPC 應用中的各種常見數據模式,包括矩陣乘法、卷積和分片數據佈局。
總體而言,Blackhole 的 Tensix 核心佔了 752 個所謂的板載 RISC-V 核心中的 700 個。其餘核心負責內存管理(「D」代表 DRAM)、片外通信(「E」代表以太網)、系統管理(「A」)和 PCIe(「P」)。
除了新芯片之外,Tenstorrent 還公開了其加速器的 TT-Metalium 低級編程模型。
熟悉 Nvidia CUDA 平台的人都知道,軟件可以成就或毀掉性能最高的硬件。事實上,TT-Metalium 有點讓人聯想到 CUDA 或 OpenCL 等 GPU 編程模型,因爲它是異構的,但不同之處在於它是從「AI 和橫向擴展」計算開始構建的,Capalija 解釋道。
其中一個區別是內核本身是帶有 API 的純 C++。「我們認爲不需要特殊的內核語言,」他解釋道。
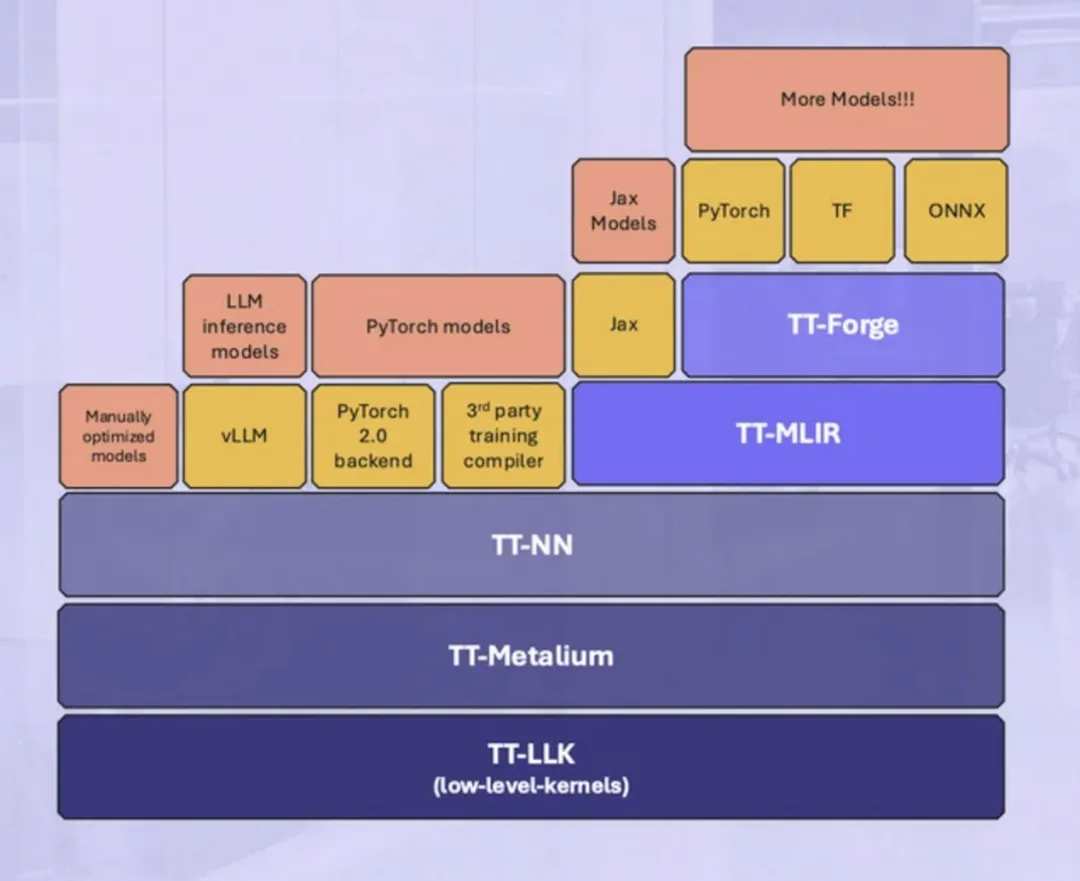
結合 TT-NN、TT-MLIR 和 TT-Forge 等其他軟件庫,Tenstorrent 旨在支持使用 PyTorch、ONNX、JAX、TensorFlow 和 vLLM 等常用運行時在其加速器上運行任何 AI 模型。
寫在最後
替代英偉達是很多人的想法,但替代英偉達似乎是任何一個人都很難達成的目標。例如,大家都知道,英偉達能穩坐釣魚臺,除了得益於其領先的硬件外,包括CUDA在內的軟件實力,是他們能壟斷至今的根本。
但Jim Keller曾表示:「CUDA並不是護城河,而是沼澤。」他同時認爲,GPU並不是運行人工智能的全部。
「我希望可以幫助客戶構建自己的產品,這是一件很酷的事情,您可以擁有並控制它,而不用向其他人支付 60% 或 80% 的毛利率。因此,當人們告訴我們 Nvidia 已經贏了,並問爲什麼 Tenstorrent 會參與競爭時,那是因爲只要存在利潤率極高的壟斷,就會創造商機。」Jim Keller說。
在筆者看來,亞馬遜後續會如何與英偉達battle,也會是一個有意思的話題。
編輯/Rocky