
 リコーは、自社製LLMの開発だけではなく、お客様の用途や環境に合わせて、最適なLLMを低コスト・短納期でご提供するために、多様で効率的な手法・技術の研究開発を推進してまいります。
リコーは、自社製LLMの開発だけではなく、お客様の用途や環境に合わせて、最適なLLMを低コスト・短納期でご提供するために、多様で効率的な手法・技術の研究開発を推進してまいります。理光公司(社長執行役員:大山 晃)基於美國Meta Platforms公司提供的「Meta-Llama-3-70B」,改進了其日本性能,推出了基於「Llama-3-Swallow-70B*1」的基礎型號,通過合併公司的Instruct模型中的Chat Vector*2和理光製造的Chat Vector*3,結合理光獨有的技術,開發了高性能的日本大型語言模型(LLM*4)。這樣一來,理光開發和提供的LLM系列中增加了與美國OpenAI開發的GPT-4相當的高性能模型。
隨着生成AI的普及,企業對可用於業務的高性能LLM的需求日益增加。然而,LLM的追加學習存在高成本和時間耗費的挑戰。針對這一問題,將多個模型結合以創建更高性能模型的"模型融合*5"技術備受關注,被視爲一種高效的開發方法。
理光公司基於模型融合的技術與LLM開發的經驗,開發了新的LLM。這項技術有助於提高企業內部私有LLM以及特定業務用途的高性能LLM的開發效率。
 除了開發公司自家的LLM外,爲了在客戶的用例和環境下提供最適合的LLM且成本低、交付快,理光將推動各種多樣且高效的方法和技術的研究與開發。
除了開發公司自家的LLM外,爲了在客戶的用例和環境下提供最適合的LLM且成本低、交付快,理光將推動各種多樣且高效的方法和技術的研究與開發。
評估結果*6(ELYZA-tasks-100)
在包含複雜指示和任務的代表性日本語基準測試「ELYZA-tasks-100」中,理光通過模型融合方法開發的LLM展示出與GPT-4相當水平的高分。此外,與其他LLM相比,它展現出針對所有任務都用日語回答且表現出高度穩定性,而其他模型在某些任務中以英語回答。
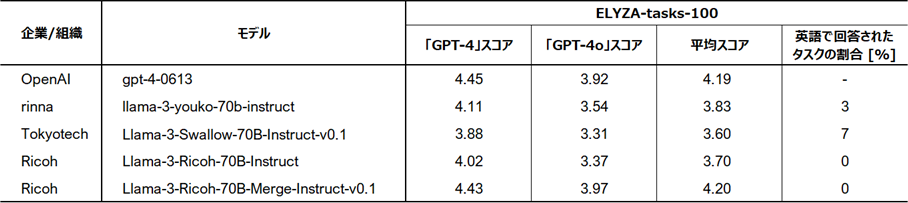 基準工具(ELYZA-tasks-100)中與其他模型的比較結果(理光位於最下方)
基準工具(ELYZA-tasks-100)中與其他模型的比較結果(理光位於最下方)Ricoh的LLM開發背景
在勞動力減少和人口老齡化的背景下,提高生產力和提供高附加值的工作方式成爲企業增長的難題,爲解決此問題,許多企業開始注意使用AI進行業務活用。然而,要將AI應用到實際的應用中,就需要將包含企業專有術語和語句的大量文本數據學習到LLM中,並創建企業獨有的AI模型(專用LLM)。
以國內頂尖的LLM開發/學習技術爲基礎,Ricoh可以提供企業專用LLM的服務,以及推廣使用內部文檔的RAG等各種AI解決方案的建議。
相關股票新聞
- 理光開發了7千億參數的大規模語言模型(LLM),支持日語、英語和中文,加強了客戶的私有LLM構建支持。
- 開發了已經調整好指令的日語LLM,其參數爲130億
- 開發了具有高日語精度的130億參數的大規模語言模型(LLM)
您可以在PDF文件中查看此新聞稿
理光通過模型融合開發了等同於GPT-4的高性能日語LLM(700億參數),總共224KB,分爲2頁。
