




 据市场分析公司Appfigures的权威数据,DeepSeek的应用程序于1月26日首次登顶苹果App Store,并自此持续保持其全球领先的霸主地位。数据统计显示,自今年初发布以来,迅速攀升至140个国家的苹果App Store下载排行榜首位,并在美国的Android Play Store中同样占据榜首位置。
据市场分析公司Appfigures的权威数据,DeepSeek的应用程序于1月26日首次登顶苹果App Store,并自此持续保持其全球领先的霸主地位。数据统计显示,自今年初发布以来,迅速攀升至140个国家的苹果App Store下载排行榜首位,并在美国的Android Play Store中同样占据榜首位置。

Source: Industry Observation on Semiconductors.
In the past two weeks, DeepSeek has become a Global hotspot. Especially in the Western world, this generative AI system from China has sparked widespread discussion.
Within the first 18 days of its release, DeepSeek achieved an astonishing 16 million downloads, nearly double the download volume of its competitor OpenAI's ChatGPT during the same period, fully demonstrating its strong market appeal and user base.
 According to authoritative data from market analysis firm Appfigures, DeepSeek's app topped the Apple App Store on January 26 and has since maintained its dominant position globally. Statistics show that since its release earlier this year, it has quickly risen to the top of the download rankings in the Apple App Store in 140 countries and also holds the top position in the Android Play Store in the USA.
According to authoritative data from market analysis firm Appfigures, DeepSeek's app topped the Apple App Store on January 26 and has since maintained its dominant position globally. Statistics show that since its release earlier this year, it has quickly risen to the top of the download rankings in the Apple App Store in 140 countries and also holds the top position in the Android Play Store in the USA.
As an AI large model from China, DeepSeek's ability to gain this level of attention is due not only to its outstanding performance but also to its low training costs, which are key to attracting global interest. In today's article, we will take a look at the chips and systems behind DeepSeek.
DeepSeek's architecture self-description.
As early as August 2024, the DeepSeek team published a paper describing a new type of load balancer they created to connect the elements of their mixture of experts (MoE) foundational model.
DeepSeek stated in the article that for the mixture of experts (MoE) model, unbalanced expert load will lead to routing collapse or increased computational overhead. Existing methods typically use auxiliary loss to promote load balancing, but a large auxiliary loss introduces significant interference gradients during training, impairing model performance.
In order to control load balancing during training without producing undesired gradients, the DeepSeek team proposed Loss-Free Balancing, characterized by an auxiliary-loss-free load balancing strategy.
Specifically, before making top-K routing decisions, Loss-Free Balancing first applies expert-wise bias to the routing scores of each expert. By dynamically updating the bias based on each expert's recent load, Loss-Free Balancing can maintain a balanced distribution of expert loads.
Moreover, since Loss-Free Balancing does not produce any interfering gradients, it also enhances the upper limit of model performance obtained from MoE training. The DeepSeek team has validated the performance of Loss-Free Balancing on MoE models trained with up to 3 billion parameters and on up to 200 billion tokens. Experimental results indicate that, compared to traditional auxiliary dropout-controlled load balancing strategies, Loss-Free Balancing achieves both better performance and better load balance.
Figure 1: Loss-Free Balancing selects experts based on the 'biased gating score' in each training step and updates this expert bias after each training step.
In the report 'DeepSeek-V3 Technical Report' published at the end of 2024, the DeepSeek team provided an in-depth interpretation of the technical architecture of their DeepSeek-V3 model, offering more references for understanding the company's technology.
They stated in the report that, for forward-looking considerations, the company consistently pursues models that are strong in performance yet low in cost. Therefore, in terms of architecture, DeepSeek-V3 still adopts Multi-head Latent Attention (MLA) for efficient inference and DeepSeekMoE for economical training. To achieve efficient training, the DeepSeek team's solution supports FP8 mixed precision training and has comprehensively optimized the training framework. In their view, low precision training has become a promising solution for efficient training, closely related to advancements in hardware capabilities.
Figure 2: Overall mixed precision framework using FP8 data format. For clarity, only linear operators are indicated.
By supporting FP8 computation and storage, the DeepSeek team achieved accelerated training and reduced GPU memory usage. In terms of the training framework, they designed the DualPipe algorithm for efficient pipeline parallelism, which features fewer pipeline bubbles and hides most of the communication during the training process through computation-communication overlap.
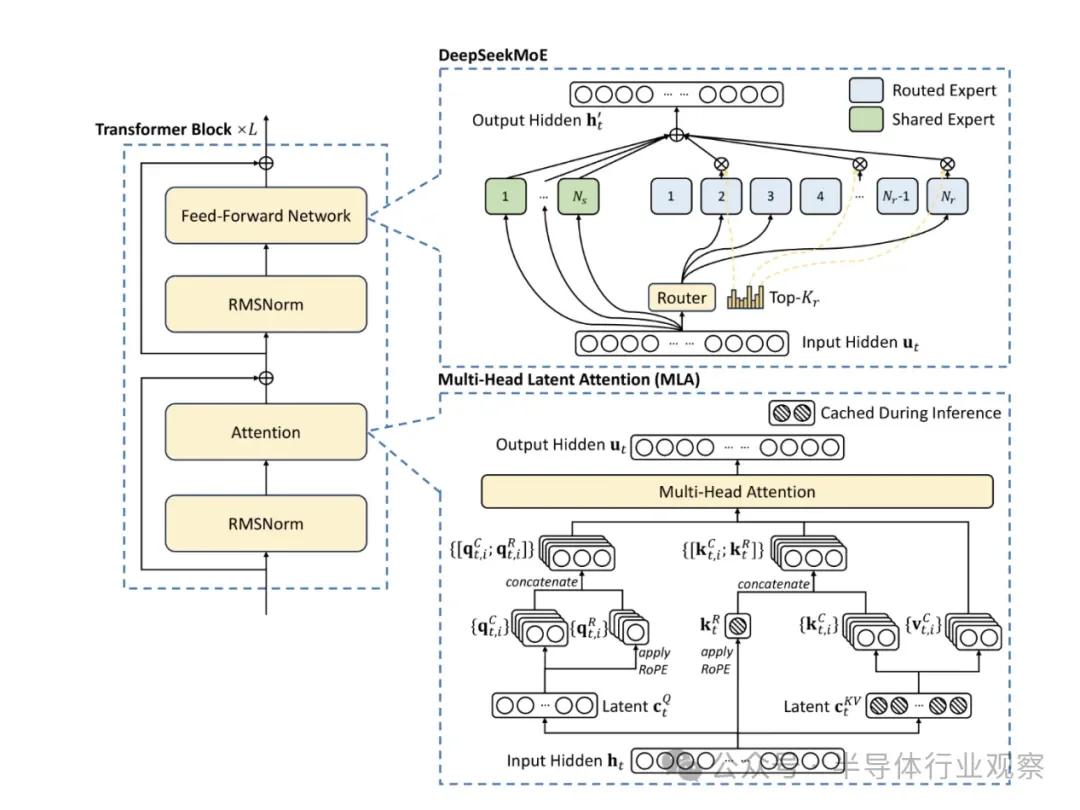
Figure 3: Basic architecture diagram of DeepSeek-V3. Following DeepSeek-V2, the company employs MLA and DeepSeekMoE for efficient inference and economical training.
The DeepSeek team stated that this overlap ensures that as the model further expands, as long as the computation and communication ratio remains constant, the company can still utilize fine-grained experts across nodes while achieving near-zero all-to-all communication overhead.
In addition, the DeepSeek team developed efficient cross-node all-to-all communication kernels to fully leverage the bandwidth of InfiniBand (IB) and NVLink. The company also meticulously optimized memory usage, allowing for training of DeepSeek-V3 without the need for expensive tensor parallelism.
By combining these efforts, the DeepSeek team achieved high training efficiency.

Table 1: Training costs of DeepSeek-V3, assuming a rental price of $2 per GPU hour for H800.
According to the DeepSeek team in the paper, this was achieved through the collaborative design of optimization algorithms, frameworks, and hardware. During the pre-training phase, training DeepSeek-V3 on every trillion tokens requires only 180K H800 GPU hours, which means it only took 3.7 days on its cluster with 2048 H800 GPUs. Thus, the company's pre-training phase was completed in less than two months, costing 2,664K GPU hours. In addition to the 119K GPU hours for extending context length and 5K GPU hours for post-training, the complete training of DeepSeek-V3 only cost 2.788 million GPU hours.
Assuming a rental price of $2 per hour for H800 GPUs, this represents a total training cost of only $5.576 million. The DeepSeek team also specifically emphasized that the aforementioned cost only includes the official training of DeepSeek-V3, excluding costs related to previous research and ablation experiments concerning architecture, algorithms, or data. In comparison, OpenAI's boss Sam Altman stated that training GPT-4 requires over $0.1 billion.
On January 20, DeepSeek launched the DeepSeek-R1 model, which adds two reinforcement learning stages and two supervised fine-tuning stages to enhance the model's reasoning abilities. DeepSeek AI charges 6.5 times more for the R1 model than the basic V3 model. Subsequently, DeepSeek released Janus-Pro, which is an updated version of its multimodal model Janus. The new model improved training strategies, data augmentation, and model size, enhancing multimodal understanding and text-to-image generation.
Up to this point, DeepSeek is popular globally.
The chips behind DeepSeek.
After the emergence of DeepSeek, discussions around its system and technology research framework have also spread throughout the internet, particularly concerning hardware. Due to its extremely low cost, this has led to shocks in the entire AI Chip market. A few days ago,$NVIDIA (NVDA.US)$the significant drop was the most direct reflection of this concern.
As mentioned above, DeepSeek stated that the cluster used to train the V3 model consists of only 256 Server nodes, each with 8 H800 GPU accelerators, totaling 2,048 GPUs. According to analysis by analysts from nextplatform, these GPU cards are likely the H800 SXM5 versions of NVIDIA H800 cards, with a maximum FP64 floating-point performance limit of 1 trillion floating-point operations, similar in other aspects to the 80 GB version of H100 cards that most companies around the world can purchase.
Within the node, the eight GPUs are interconnected via NVSwitch to create a shared memory domain among these GPU memories, and the node has multiple InfiniBand cards (possibly one for each GPU) to create high-bandwidth links to other nodes in the cluster.
Specifically concerning the H800, this is the GPU that NVIDIA initially introduced in response to the USA's export restrictions. At that time, the USA GPU export ban primarily restricted two aspects: compute power and bandwidth. Among them, the maximum compute power was 4800 TOPS, and the maximum bandwidth was 600 GB/s. The compute power of A800 and H800 is comparable to the original version, but the bandwidth has been reduced.
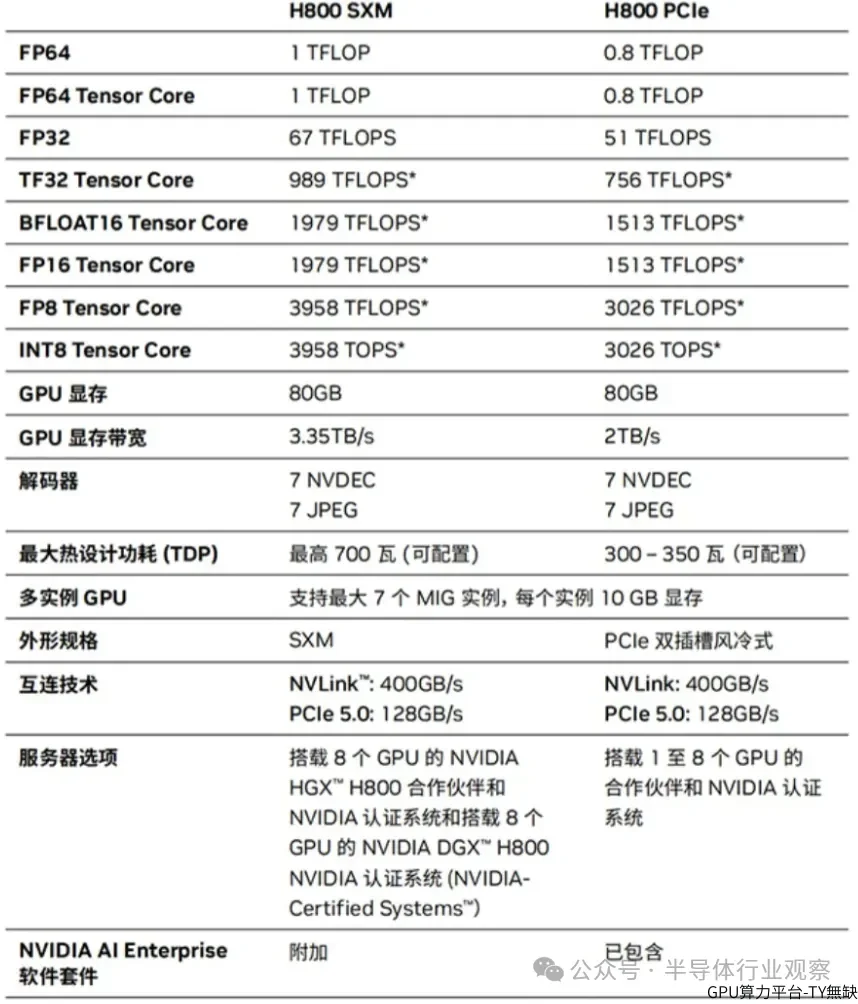
As mentioned above, DeepSeek uses the H800 SXM version in training. It is understood that the so-called SXM architecture is a high-bandwidth socket solution for connecting NVIDIA Tensor Core accelerators to its proprietary DGX and HGX systems. For each generation of NVIDIA Tensor Core GPU, the DGX system HGX board is equipped with SXM socket types, providing high bandwidth, power delivery, and other functions for its matching GPU subcards.
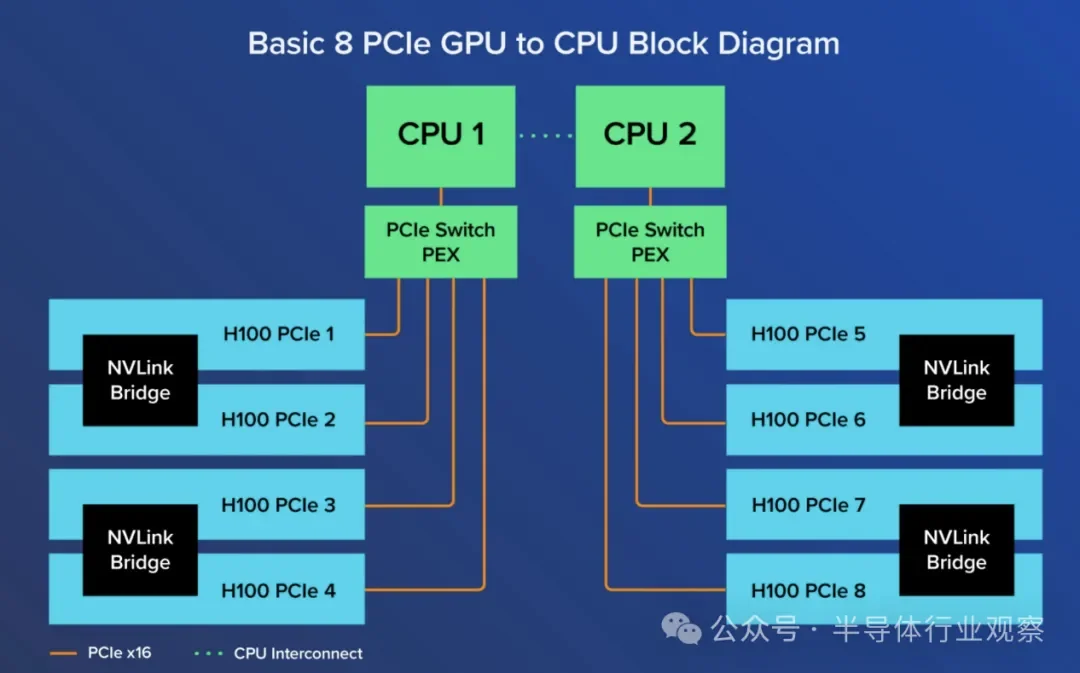
According to the data, dedicated HGX system boards interconnect 8 GPUs through NVLink to achieve high bandwidth between the GPUs. The capabilities of NVLink enable a rapid flow of data between GPUs, allowing them to operate as a single powerful GPU without needing to swap data via PCIe or communicating with the CPU. The NVIDIA DGX H800 connects 8 SXM5 H800 through 4 NVLink Switch Chips, with a bandwidth of 400 GB/s per GPU, resulting in a total bidirectional bandwidth exceeding 3.2 TB/s. Each H800 SXM GPU is also connected to the CPU through PCI Express, allowing any computational data from the 8 GPUs to be forwarded back to the CPU.

In recent years, large enterprises have shown increased interest in NVIDIA DGX due to the fact that SXM GPUs are better suited for large-scale deployments. As mentioned, the eight H800 GPUs are fully interconnected via NVLink and NVSwitch interconnection technologies. In DGX and HGX, the way the 8 SXM GPUs are connected differs from PCIe; each GPU is connected to 4 NVLink Switch Chips, effectively allowing all GPUs to operate as one large GPU. This scalability can be further expanded through NVIDIA NVLink Switch systems to deploy and connect 256 DGX H800 units, creating a GPU-accelerated AI factory.
Foreign Analysts' Views on DeepSeek.
Based on these GPUs and systems, despite this achievement, many Western analysts have criticized the DeepSeek team. However, analysts from the nextplatform indicate that if you read this 53-page paper carefully, you will find that DeepSeek has implemented various clever optimizations and methods to create the V3 model. They genuinely believe that this has indeed reduced inefficiencies and improved DeepSeek's training and inference performance on hardware.
They believe that the key innovation in the method used by the DeepSeek team to train the V3 base model is the use of 20 out of 132 streaming multiprocessors (SM) on Hopper GPUs as communication accelerators and schedulers for data, since the training running carefully examines tokens and generates model weights from the parameter deep set, thus data is passed within the cluster. According to nextplatform, as stated in the V3 paper, this "overlap between computation and communication can mask communication latency during the computation process," where using SM creates something that functions as L3 cache controllers and data aggregators between GPUs not on the same node.
As per nextplatform's sharing of their paper, DeepSeek created its own GPU virtual DPU to perform various Sharp-like processes related to all-to-all communication in the GPU cluster.
As mentioned above, the DeepSeek team designed the DualPipe algorithm to achieve efficient pipeline parallelism. In this regard, nextplatform pointed out that if DeepSeek could improve the computational efficiency on these 2,048 GPUs to nearly 100%, then the cluster would start to consider it to have 8,192 GPUs (of course lacking some SM) that operate inefficiently because they do not have DualPipe. In comparison, OpenAI's GPT-4 base model was trained on 8,000 Nvidia "Ampere" A100 GPUs, which is equivalent to around 4,000 H100 (approximately).
Additionally, including auxiliary lossless load balancing, FP8 low precision processing, promoting high precision matrix arithmetic of intermediate results in tensor cores to vector units on CUDA cores to maintain higher precision representation, recomputing all RMSNorm operations during backpropagation, and recomputing all MLA upward projections are also among DeepSeek's innovations.
Dylan Patel from the renowned semiconductor Analyst organization SemiAnalysis has questioned the costs disclosed by the DeepSeek team. However, they also acknowledge that DeepSeek has outstanding capabilities.
SemiAnalysis stated that DeepSeek-R1 can achieve results comparable to OpenAI-o1, which was released only in September. How could DeepSeek catch up so quickly? This is mainly because inference has become a new paradigm, where the iteration speed is faster and the computational load is lighter compared to before, yet still resulting in meaningful gains. In comparison, previous models relied on pre-training, but the costs of pre-training have become increasingly high and it is difficult to achieve robust returns.
They pointed out that the new paradigm focuses on achieving inference capability through synthetic data generation and RL during post-training of existing models, thus obtaining faster gains at a lower cost. A lower barrier to entry combined with straightforward optimization means that DeepSeek can replicate the o1 method faster than ever.
“R1 is an excellent model, and we have no disagreement on this, catching up to the inference edge so quickly is objectively impressive,” emphasized SemiAnalysis. They summarized:
On one hand, DeepSeek V3 has adopted Multi-Token Prediction (MTP) technology on an unprecedented scale, and these additional attention modules can predict multiple tokens instead of a single token. This improves the model's performance during training and can be discarded during inference. This is an example of an algorithm innovation that enhances performance with lower computational costs. There are also some additional considerations, such as improving FP8 accuracy during training;
On the other hand, DeepSeek V3 is also a mixture of expert models, composed of many smaller models that specialize in different fields. A challenge faced by the mixture of experts model is determining which token to assign to which sub-model or 'expert'. DeepSeek implements a gating network to efficiently route tokens to the appropriate expert without compromising model performance. This means the routing choices are very efficient, requiring only a small number of parameter changes for each token during training relative to the overall model size. This not only improves training efficiency but also reduces inference costs;
Furthermore, regarding R1, the powerful foundational model (v3) will benefit greatly. Part of the reason is reinforcement learning (RL).
Reinforcement learning focuses on two aspects: formatting (ensuring coherent output) and usefulness and harmlessness (ensuring the model is useful).
While fine-tuning the model on synthetic datasets, inferential capabilities emerged;
SemiAnalysis reiterates that MLA is a key innovative technology for DeepSeek significantly reducing inference costs. The reason lies in the fact that, compared to standard attention, MLA reduces the amount of KV cache required per query by approximately 93.3%. KV cache is a memory mechanism in transformer models used to store data that represents conversation context, thus reducing unnecessary computations.
Potential impact on NVIDIA chips.
As mentioned at the beginning of the article, after DeepSeek became popular, NVIDIA responded with a sharp decline. This is because if large technology companies in the USA begin to learn from DeepSeek and opt for cheaper AI solutions, it could put pressure on NVIDIA.
Subsequently, Nvidia gave a positive assessment of DeepSeek's progress. The company stated in a statement that DeepSeek's advancement well demonstrates a new operational approach to AI models. The company mentioned that providing such AI models to users requires a large number of Nvidia chips.
However, renowned investor and Ark Invest CEO "Woodstock" Cathy Wood stated in an interview that DeepSeek proves that success in the AI field doesn’t require that much money and accelerates the collapse of costs.
Counterpoint Research's Chief Analyst for AI, Sun Wei, also noted that Nvidia's sell-off reflects a shift in people's perspectives on AI development. She further pointed out: "The success of DeepSeek challenges the belief that larger models and more powerful computing capabilities provide better performance, posing a threat to Nvidia's GPU-driven growth strategy."
SemiAnalysis emphasized that the speed of algorithm improvement is too fast, which is also disadvantageous for Nvidia and GPUs.
The American media outlet "Fortune" even warned that DeepSeek is threatening NVIDIA's AI dominance.
As mentioned earlier, DeepSeek has adopted lower-performing, cheaper chips to build its latest model, which has also put pressure on Nvidia, with some worried that other large technology companies might reduce their demand for Nvidia's more advanced products.
AvaTrade's Chief Market Analyst Kate Leaman told "Fortune" magazine: "Investors are concerned that DeepSeek's ability to work with lower-performing AI chips may undermine Nvidia's dominance in the AI hardware sector, particularly considering that its valuation heavily relies on AI demand."
It's worth mentioning that according to tomshardware's report, DeepSeek's AI breakthrough bypassed Nvidia's CUDA unboxing and instead used assembly-like PTX programming, which has somewhat heightened concerns about Nvidia.
According to reports, NVIDIA's PTX (Parallel Thread Execution) is an intermediate instruction set architecture designed by NVIDIA for its GPUs. PTX is positioned between high-level GPU programming languages (such as CUDA C/C++ or other language front-ends) and low-level machine code (streaming assembly or SASS). PTX is a close-to-metal ISA that exposes the GPU as a data-parallel computing device, enabling fine-grained optimizations such as register allocation and thread/warp-level tuning, which CUDA C/C++ and other languages cannot accomplish. Once PTX enters SASS, it is optimized for a specific generation of NVIDIA GPUs.
During the training of the V3 model, DeepSeek reconfigured NVIDIA's H800 GPU: It allocated 20 out of 132 streaming multiprocessors for server-to-server communication, potentially used for compressing and decompressing data to overcome the connectivity limitations of processors and speed up trades. To maximize performance, DeepSeek also implemented advanced pipeline algorithms, possibly achieved through ultra-fine thread/warp-level tuning.
Reports indicate that these modifications far exceed the range of standard CUDA-level development but are very difficult to maintain.
However, Morningstar strategist Brian Colello bluntly stated that DeepSeek's entry undeniably adds uncertainty to the entire AI ecosystem, but this has not changed the overwhelming momentum behind the movement. In a report, he wrote: "We believe the demand for AI GPUs still exceeds supply. Therefore, even though slimmer models may achieve greater development with the same number of chips, we still believe technology companies will continue to buy up all the GPUs they can as part of this AI 'gold rush.' "
Industry veterans like former Intel CEO Pat Gelsinger also believe that applications like AI can leverage all the computing power they can access. Regarding DeepSeek's breakthrough, Gelsinger views it as a way to integrate AI into a large number of inexpensive devices on the mass market.
SemiAnalysis revealed in its report that since the release of DeepSeek V3 and R1, the price of AWS GPUs, including H100, has risen in many regions. The similar H200 is also harder to find. "After the launch of V3, the price of H100 skyrocketed as the monetization rate of GPUs began to increase significantly. Getting more intelligence at a lower price means greater demand. This marks a significant shift compared to the sluggish spot prices of H100 from a few months ago," SemiAnalysis said.
So, what does everyone think, how will DeepSeek develop? Will NVIDIA chips continue to dominate the market?
Editor/Rocky







 Today, after hitting the high near 24,000 in the early session and entering bearish positions, the index fell sharply by nearly over 600 points, immediately recouping yesterday's losses significantly.
Today, after hitting the high near 24,000 in the early session and entering bearish positions, the index fell sharply by nearly over 600 points, immediately recouping yesterday's losses significantly.

 Moreover, today it broke the new high again, reaching a maximum of 24,076, but by the end of the market, it fell back by about 70 points, producing a bearish candle. The current trend has not yet been broken, but from the previous low until now, it has risen close to 6,000 points. It is believed that those with positions can continue to hold until there is a clear trend reversal for profit-taking. Those without positions can wait for a pullback to get in. Actually, it is hoped for a quick pullback, as it allows for entry and also provides a healthy breath.
Moreover, today it broke the new high again, reaching a maximum of 24,076, but by the end of the market, it fell back by about 70 points, producing a bearish candle. The current trend has not yet been broken, but from the previous low until now, it has risen close to 6,000 points. It is believed that those with positions can continue to hold until there is a clear trend reversal for profit-taking. Those without positions can wait for a pullback to get in. Actually, it is hoped for a quick pullback, as it allows for entry and also provides a healthy breath. Currently, the outlook remains the same as before. It is believed that even if there is a pullback, it shouldn't be too deep. However, if Futures fail to stabilize and close below 22,350, there may still be room for decline. The chance of Futures falling below 21,400 in the short term should be low, so it is considered that if a significant pullback occurs, it presents a good opportunity to incrementally go long. Recently, there has been a consistent approach to not hold positions overnight, only focusing on immediate trades, as there is no high chasing and no casual short selling.
Currently, the outlook remains the same as before. It is believed that even if there is a pullback, it shouldn't be too deep. However, if Futures fail to stabilize and close below 22,350, there may still be room for decline. The chance of Futures falling below 21,400 in the short term should be low, so it is considered that if a significant pullback occurs, it presents a good opportunity to incrementally go long. Recently, there has been a consistent approach to not hold positions overnight, only focusing on immediate trades, as there is no high chasing and no casual short selling.
Comment(7)
Reason For Report