

① OpenAI did not specifically mention the "upstream providers" related to this issue. Its exclusive cloud provider, Microsoft, reported that one of its datacenters had "power issues," which have now been resolved; ② The most recent massive outage occurred on December 11, when all services under OpenAI experienced up to 4 hours of severe performance degradation, or were even completely unavailable.
The Star Daily reported on December 27 (Editor: Song Ziqiao) that early in the morning on December 27, OpenAI announced that the chatbot ChatGPT, video generation model Sora, and API encountered significant errors, with most services down for several hours, although the cause has been identified and recovery efforts have begun.
The issue began around 1:30 PM EST on December 26. The network monitoring site Downdetector reported that over 0.015 million users reported problems that afternoon, mainly related to ChatGPT. By that evening, the number of reports had decreased to less than 700.
 OpenAI subsequently released a report stating that the error rate for ChatGPT, API, and Sora is currently very high, and this issue is caused by upstream providers.
OpenAI subsequently released a report stating that the error rate for ChatGPT, API, and Sora is currently very high, and this issue is caused by upstream providers.
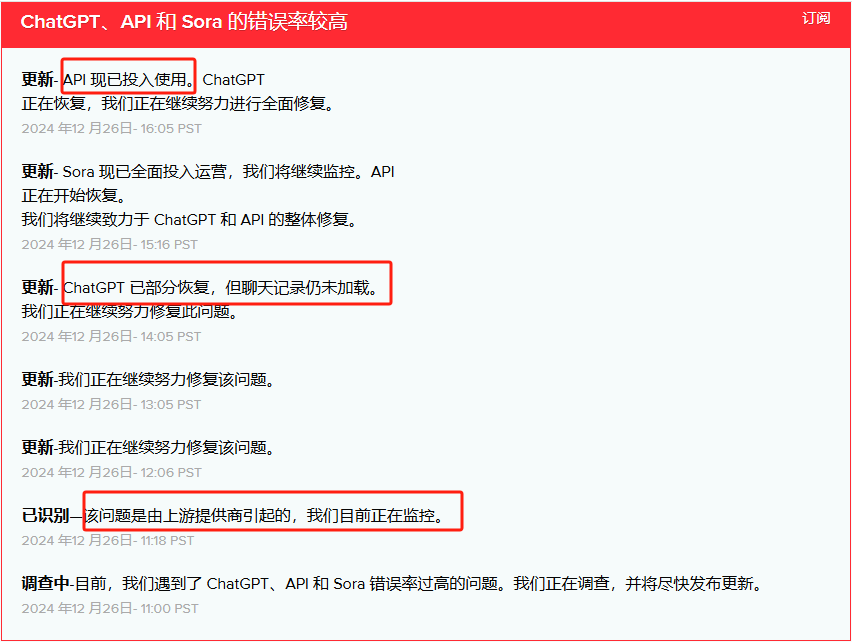
Image source: OpenAI
According to previous media reports, OpenAI did not specify the "upstream providers" related to this issue, but its exclusive cloud provider Microsoft reported that one of its datacenters had "power issues" that coincided with OpenAI's problems and affected the North American region, while Xbox cloud gaming also experienced issues. Shortly after 5 PM EST on December 26, Microsoft stated it had "fully restored" power to the affected datacenter.

Image source: Microsoft
As of the end of this summer, the daily active users of ChatGPT have exceeded 0.2 billion. Since its release, OpenAI's popular products, including ChatGPT, have experienced multiple outage events.
The most recent large-scale outage occurred on December 11, just days after the release of Sora, when all services under OpenAI, including ChatGPT, API, and Sora, experienced severe performance degradation or complete unavailability from 3:16 PM to 7:38 PM Pacific Time, lasting for over four hours. This outage was caused by a misconfiguration of a newly deployed telemetry service, which overloaded the control planes of hundreds of global Kubernetes clusters, leading to cascading failures of critical systems.
