
 前十一天,OpenAI 的发布会涉及技术、产品形态、商业模式和产业生态等多个重要更新,包括完整的推理模型 o1、强化微调、文生视频 Sora、更强的写作和编程工具 Canvas、与 Apple 生态系统的深度整合、语音和视觉功能、Projects 功能、ChatGPT 搜索、给 ChatGPT 打电话和 WhatsApp 聊天等等。
前十一天,OpenAI 的发布会涉及技术、产品形态、商业模式和产业生态等多个重要更新,包括完整的推理模型 o1、强化微调、文生视频 Sora、更强的写作和编程工具 Canvas、与 Apple 生态系统的深度整合、语音和视觉功能、Projects 功能、ChatGPT 搜索、给 ChatGPT 打电话和 WhatsApp 聊天等等。Source: Geek Park
Author: Li Shiyun
For the first time in history, a company will hold a product launch event for 12 consecutive days——when OpenAI announced this decision, the anticipation in the global Technology circle was at its peak. But as the launch event drew to a close, an AI professional expressed his feelings: "Is that it? Just that?"
This seems to represent a certain mainstream view: the OpenAI launch event had little highlight and was below expectations.
 In the previous eleven days, OpenAI's launch event involved multiple important updates regarding technology, product forms, business models, and Industry ecosystems, including the complete reasoning model o1, enhanced fine-tuning, text-to-video Sora, stronger writing and programming tools Canvas, deep integration with the Apple ecosystem, voice and visual functionalities, Projects feature, ChatGPT search, calling ChatGPT, and WhatsApp chat, among others.
In the previous eleven days, OpenAI's launch event involved multiple important updates regarding technology, product forms, business models, and Industry ecosystems, including the complete reasoning model o1, enhanced fine-tuning, text-to-video Sora, stronger writing and programming tools Canvas, deep integration with the Apple ecosystem, voice and visual functionalities, Projects feature, ChatGPT search, calling ChatGPT, and WhatsApp chat, among others.
However, as the AI professional who felt disappointed mentioned, "I thought GPT-5 would be released." On the day after the launch event, reports from foreign media indicated that OpenAI's development of GPT-5 faced obstacles.
However, the o3 released on the last day was an exception. It is the next generation reasoning model following o1 and exhibited astonishing performance in various tests in mathematics, coding, and physics——a technical person from a domestic large model company spoke about the shock o3 brought him, stating, "AGI has arrived." Technical professionals generally hold high evaluations of o3.
Looking back at these 12 days of launch events, OpenAI showcased its technological "muscle" while continuously optimizing product forms and expanding the space for application. Some joked that it was like a "live-streamed sales event," with OpenAI hoping to attract more users and developers to use ChatGPT. In the new year, OpenAI may experience a leap in daily active users, revenue, and other metrics.

However, this process may not go smoothly. Although the model's capabilities are improving, there remains a significant gap between powerful models and their practical applications due to data constraints, encapsulation capabilities, and high model costs.
The recent OpenAI launch event seems to reveal a trend: the competition in the large model industry is not only focused on model parameters and technical limits but also on user experience and market scale. Both aspects need to progress in tandem to maintain a leading position.
After reviewing the main information from the 12 OpenAI launch events and discussing with industry personnel from the domestic large model sector, Geek Park has summarized the following key points.
The intelligence depth of o3 is sufficient, but whether it can be called AGI depends on the breadth of its intelligence.
"Crazy, too crazy." This was the first reaction from a domestic model head after seeing o3.
In complex issues such as mathematics, coding, and PhD-level scientific question answering, o3 has demonstrated levels surpassing that of some human experts. For instance, in the PhD-level scientific examination GPQA Diamond, which involves biology, physics, and chemistry, o3 achieved an accuracy of 87.7%, while PhD experts in these fields could only reach 70%; in the USA AIME mathematics competition, o3 scored 96.7, missing only one question, comparable to top mathematicians.
The widely discussed aspect is its coding ability. On Codeforces, the world's largest algorithm practice and competition platform, o3 scored 2727 points, improving over o1 by more than 800 points, equivalent to ranking 175 among human competitors. It even surpassed OpenAI's senior vice president of research, Mark Chen (who scored 2500 points).
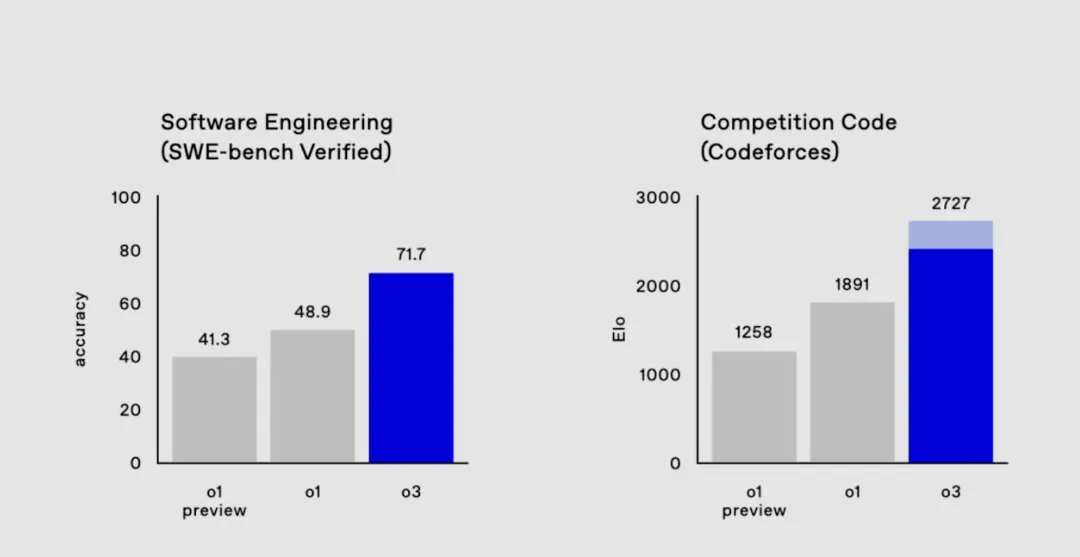
Since the launch of the o1-preview version in September, the o1 series models have undergone extraordinary evolution in reasoning ability within just three months. The full version of o1 released on the first day of the conference has improved its thinking speed by about 50% compared to o1-preview, reduced major errors in tackling difficult real-world problems by 34%, and now supports multimodal input (capable of recognizing images). Today's o3 has surpassed some levels of human experts on complex issues.
"The upgrade in model capabilities from o1 to o3 is achieved by increasing the volume of reasoning computations. With the release of domestic and international models such as Deepseek-R1 and Gemini 2.0 Flash Thinking, it indicates that large models are beginning to shift from the pre-training Scaling Law to the reasoning Scaling Law," said Liu Zhiyuan, a long-term associate professor at Tsinghua University and founder of Bianding Intelligent, to Geek Park.
Since OpenAI launched o1-preview, the technical paradigm of large model waves has shifted from the initial pre-training Scaling Law, which constantly expands model training parameters to enhance their intelligence limits, to a new round of upgraded technical paradigm, which injects reinforcement learning during the reasoning phase to enhance complex reasoning capabilities.
In the former paradigm, the model mainly provides answers through next token prediction and is more inclined toward "fast thinking." It's like having "read ten thousand books" but "learning without thinking is in vain," making it unable to perform more complex reasoning tasks like mathematics and programming.
In the latter paradigm, the model will not immediately provide an answer but will "slow think," first introducing CoT (Chain of Thought), planning and breaking down complex problems into simpler steps to finally reach a result. When one method fails, it will try another method, enhancing complex reasoning abilities through reinforcement learning. As the model continuously engages in "slow thinking" and reinforcement learning, its reasoning capabilities increase exponentially, which is the reasoning Scaling Law.
Regarding the super research reasoning ability of o3 that exceeds human experts - in Liu Zhiyuan's view, this indicates that o3 is moving towards the direction of a 'super intelligent supercomputer.'
Many industry insiders believe that this will have a profound impact on the cutting-edge scientific field. From a positive perspective, o3's extremely strong research reasoning ability can help advance fundamental scientific research in disciplines such as mathematics, physics, biology, and chemistry. However, some are concerned that it may disrupt the work of researchers.
The astonishing depth of intelligence brought by o3 seems to reveal a glimpse of AGI. However, in Liu Zhiyuan's view, just as the hallmark of the information revolution was not large computers, but the popularization of personal computers (PCs), only when AGI is made accessible and affordable for everyone, allowing each person to have their own large model to solve their daily problems, can it signify a true intelligence revolution.
"After all, we don't need to have Tao Zhexuan and Hinton (both top scientists) solve our daily problems for us," he said.
The key issue behind this is whether the intelligence depth of the o3 model can generalize to various other fields and whether it has sufficient intelligence breadth - in the opinion of technical personnel from a major domestic model company, only by simultaneously breaking through the depth and breadth of intelligence can it be called AGI. He feels optimistic about this, "It's like when a transfer student joins your class. You haven't interacted with him, but he ranks first in math and programming on the exams. Do you think he will perform poorly in Chinese and English?"
For domestic large model companies, the core issue is still how to catch up with o3. From the key elements of training architecture, data, training methods, and evaluation datasets, it seems to be a problem that engineering can solve.
"How far do you think we are from having an open-source model at the level of o3?"
"One year from now," the person in charge of the model replied.
The model is just an engine; the key is to help developers use it.
Despite the strong capabilities of the o3 model, there is still a significant gap between the model and its practical applications in the eyes of some application-level professionals. "Today, OpenAI trained Einstein, but if you want to become the chief scientist of a listed company, there is still a distance," said Zhou Jian, founder and CEO of Lanma Technology, to Geek Park.
As an intermediate layer for large models, Lanma Technology is among the earliest companies in the country to explore the practical application of large models and create AI Agents. In Zhou Jian's view, large models are just infrastructure and need to be combined with various scenarios for many tasks to be usable, and the main constraint currently is data.
In many scenarios, obtaining complete data is very difficult, and much of the data is not even digitalized. For example, headhunters may need resume data, but many resume data have not been digitized.
Cost is the most critical factor affecting the implementation of the o series models. According to ARC-AGI testing standards, o3-low (low computational mode) costs $20 per task, while o3-high (high computational mode) costs thousands of dollars per task—asking even the simplest question can cost nearly 20,000 dollars. The benefits and costs cannot balance at all, and the implementation of o3 may still require a long time.

Regarding helping the application of models, OpenAI also released corresponding functional solutions at the launch. For example, the next day, OpenAI specially released the AI Reinforcement Fine-Tuning feature for developers, which is the functionality Zhou Jian is most concerned about. It refers to the ability of the model to optimize reasoning capabilities and enhance performance with a small amount of data.
This is especially applicable to the refined field of applications. OpenAI technologists claim that it can help any field that requires deep expertise in AI models, such as Law, Finance, Engineering, Insurance. One example is that recently, Thomson Reuters used reinforced fine-tuning to fine-tune o1-mini, resulting in a useful AI legal assistant that helped their legal professionals complete some of the 'most analytical workflows.'
For example, on the ninth day, the o1 model was finally opened for developers to use. It supports function calls and visual capabilities; it introduced WebRTC to enable real-time voice application development; it launched a preference fine-tuning feature to help developers customize the model; and it released Go and JAVA SDKs to allow developers to quickly get started with integration.
At the same time, it brought lower costs and higher quality 4o voice models. Among them, the price of 4o audio was reduced by 60%, down to $40/million tokens for input and $80/million tokens for output, while the cached audio price dropped by 87.5% to $2.50/million tokens; for developers with limited budgets, OpenAI introduced GPT-4o mini, with audio costs being only a quarter of those of 4o.
This new feature is also a focus for Zhou Jian. He believes that the updated real-time voice and visual recognition capabilities can be better applied in scenarios such as marketing, telephone customer service, and sales outbound calls. In his experience, when OpenAI releases certain leading technologies, domestic companies can generally catch up within 6-12 months. This gives him confidence in the application business for the new year.
Sora's video generation fell short of expectations, but the product's release will enhance its physical simulation capabilities.
At the beginning of the year, when OpenAI released the demo of Sora, it shocked the global technology community. However, throughout the year, various domestic model companies competed in the text-to-video field — by the time OpenAI officially released Sora on the third day of the conference, domestic text-to-video companies breathed a sigh of relief.
'There is basically nothing that exceeds expectations; the realism, physical properties, and other aspects have not significantly changed compared to the release in February, falling short of what was anticipated from the basic model capability,' said Tang Jiayu, co-founder and CEO of Shengshu Technology, to Geek Park.
Currently, companies like ByteDance, Kuaishou, MiniMax, Zhupu, Shengshu, and Aishi have all launched their own text-to-video products. 'The performance and strength of Sora do not show any obvious advantages; we see that we are indeed keeping pace with OpenAI,' Tang Jiayu stated.
In his view, the highlights of Sora are slightly beyond basic text-to-video and image-to-video, providing some editing features that enhance the video creation experience, indicating that OpenAI is indeed more focused on product experience.
For example, the storyboard feature acts like a timeline, breaking a story (video) into multiple different story cards (video frames). Users only need to design and adjust each story card (video frame), and Sora will automatically stitch them together into a smooth story (video) - this is very similar to storyboards in movies or animation drafts; once the director completes the storyboard and the comic artist finishes the draft, an animation or film is completed. It allows creators to express themselves better.
Additionally, it has launched features for direct text modification of videos, seamless blending of two different videos, and changing the artistic style of the video, which is like adding "special effects" directly to the video. In contrast, typical text-to-video products cannot directly modify the original video but can only keep adjusting the prompts to generate new videos.

In Tang Jiayu's opinion, these feature designs are indeed meant to give creators greater creative freedom, and similar features are already planned for iteration in Vidu (the text-to-video product from Shengshu Technology). "The implementation of these features in Sora poses no difficulty for us, and the path to realization is already very clear," he said.
At the launch event, Sam Altman explained the reasons for creating Sora: first, its tool value, providing creative tools for creative personnel; second, interaction value, as large models should not only interact through text, but should also expand into multimodal interactions; third, and most importantly, it aligns with the vision of AGI technology, as Sora is learning more about the rules of the world and may ultimately establish a "world model" that understands physical laws.
Tang Jiayu believes that the videos generated by Sora still contain many obvious violations of physical laws, showing little improvement compared to the demo in February. In his view, after Sora's release, more people will attempt to explore its physical simulation capabilities, and these testing samples may play a certain guiding role in enhancing its physical simulation.
Can ChatGPT, with its internal functions and external ecosystem, transform into a Super App?
Apart from the o-series models, Sora, and developer services, the main actions of OpenAI at the launch event included continuing to add new features on the product side and optimizing user experience. On the other hand, they are actively promoting deep cooperation with companies like Apple to explore the integration of AI into terminal devices and operating systems.
From the former, it can be seen that the evolution direction of ChatGPT seems to aim at becoming a 'super AI assistant that is omnipotent, omnipresent, and accessible to everyone.' According to Geek Park, the original vision of OpenAI was to create an 'omnipotent' Agent that can understand human commands, automatically call different tools, and meet human needs. It appears that the destination is the starting point.
For example, on the sixth day, ChatGPT added support for video calls with screen sharing and the Santa Claus voice mode. The former allows users to have real-time video calls with the AI, share the screen or showcase the surrounding environment, facilitating multimodal interactions that recreate scenes from the movie 'Her.'
For instance, on the eighth day, ChatGPT opened its search function to all users. In addition to basic search, it also added voice search; meanwhile, it integrated map services from mobile devices, enabling retrieval of search results from Apple and Google Maps. It has also established partnerships with several leading news and data providers, supporting users in checking stock market quotes, sports scores, weather forecasts, and more.
Another example is on the eleventh day when ChatGPT announced the expansion of its integration with desktop software. It can connect to more coding applications like BBEdit, MatLab, NOVA, Script Editor, etc.; it can work alongside applications like Warp (a file-sharing app) and XCode editor; it can also collaborate with other applications in voice mode, including NOTION and Apple Notes.
An example showcased live is when a user sets up a 'holiday party playlist' in Apple Notes and asks ChatGPT for opinions on the candidate songs. ChatGPT can point out user errors, such as mistakenly writing the Christmas song 'Frosty the Snowman' as 'Freezy the Snowman.'

"ChatGPT will transform from a simple conversational assistant to a more powerful agent tool," said OpenAI Chief Product Officer Kevin Weil.
On the other hand, OpenAI is also actively expanding its ecosystem, reaching a wider audience by integrating into the most commonly used terminal devices, operating systems, and upper-level software.
For example, on the fifth day, ChatGPT announced the integration of the Apple Smart ecosystem, incorporating iOS, MacOS, and iPadOS, enabling users to access AI capabilities across platforms and applications, including Siri interaction, Writing Tools, and Visual Intelligence for smart recognition of scene content. Through this collaboration, ChatGPT reached billions of Apple users worldwide. It also set a precedent for cooperation between large models and device-side operating systems.
For example, on the tenth day, ChatGPT announced its phone contact number (1-800-242-8478), allowing USA users to call this number for 15 minutes of free calls each month. Also launched was a WhatsApp contact (1-800-242-8478), which allows any user worldwide to send messages to this number, currently limited to text only.

In some countries and regions around the globe, the penetration rate of Smart Phones and the Penghua CSI Mobile Internet Index Fund(LOF)-A is still far from sufficient. Through the most basic communication tool, the telephone, ChatGPT reached these groups. At the same time, it also reached nearly 3 billion users through WhatsApp.
Whether it's internal features or external ecosystems, the core focus of ChatGPT is to reach a broader audience and become a true Super APP. However, some are skeptical about this continuous addition of functions and the endless expansion of business lines, even describing it as 'laying out a big pancake, but each piece is a bit thin and doesn't go deep enough.' Many businesses need to be deep enough to realize their value, and there are corresponding companies that focus on depth, which may be a challenge that OpenAI has to face.
Although the O3 model has shown the world OpenAI's astonishing technological strength, doubts about how far the Scaling Law of reasoning can reach in terms of intelligent limits and the difficulties surrounding the development of GPT-5 still leave the public questioning the company's technological progress. At this release event, OpenAI shifted its focus to product forms, cooperative ecosystems, and practical implementation, which might also be a strategy. The combination of these two factors may determine the future direction of the Industry.
Editor/rice
