

① Google has released the next generation large model Gemini 2.0, which has doubled speed, enhanced capabilities, and supports native image generation and audio output in multimodal outputs.
② Google has launched a new multimodal real-time API that supports real-time audio and video stream input and the use of multiple combination tools. Additionally, three intelligent agent research prototypes were showcased: Project Astra, Project Mariner, and Jules.
③ The release of Google Gemini 2.0 is a defense of its inherent business, aiming to achieve enhanced capabilities at a lower cost.return on investmentImprovement.
 $Alphabet-C (GOOG.US)$ With a single release, it accomplished more than OpenAI did in five days.
$Alphabet-C (GOOG.US)$ With a single release, it accomplished more than OpenAI did in five days.
In the early morning of December 12, just as OpenAI's intense "12-day continuous release" reached its fifth day, Google released their significant update — Gemini 2.0 Flash.
Its speed has doubled, it is more capable, and it supports multimodal outputs for native image generation and audio output, as well as native use of tools like Google Search and Maps.
These updates bring much more than just an upgraded language model from Google; they present a unified underlying model that meets the basic needs of AI agents.
Google CEO Sundar Pichai stated in an open letter: "If Gemini 1.0 was about organizing and understanding information, then Gemini 2.0 is about making this information truly useful."
"Over the past year, we have been investing in developing more proactive models," Pichai explained, "which means they can better understand the world around them, think ahead several steps, and take actions under your supervision."
This means that AI is no longer just passively answering questions; it is able to understand user needs, think ahead, and take action under user supervision. Imagine an assistant that can help you plan trips and actually book tickets; this is Google's vision for the future of AI.
This vision has been mentioned by OpenAI and Microsoft as well, and they have also launched their own concepts and progressive products. However, a truly complete system-level Copilot and intelligent agent application are still being gradually implemented.
But Google has brought the whole pot to the table this time. It has included things that OpenAI and Microsoft did not showcase.
From the enhancement of Gemini 2.0's capabilities to Google's showcase of the three intelligent agent research prototypes: Project Astra, Project Mariner, and Jules, all mark that Google AI has preliminarily achieved a shift towards the era of "active agents." This means AI will transition from a passive information processing tool to an intelligent assistant capable of proactive thinking and actions.
Even without mentioning surpassing competitors, with the launch of Gemini 2.0, Google has returned to a leading position across all fields of products, models, agents, and systems.
Google, the king returns.
01 Gemini 2.0 Flash: The new霸主in the village.
Gemini Flash 2.0 brings many impressive enhancements, all of which ultimately support the agents.
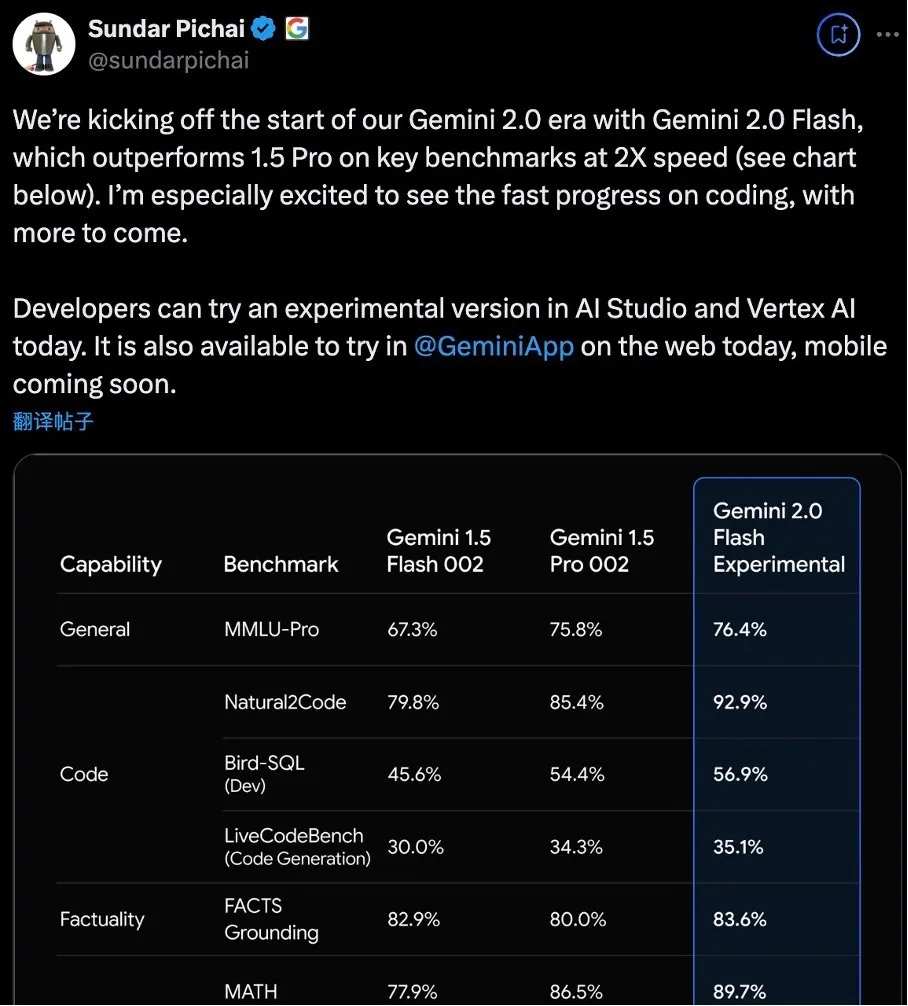
Technological advancements are first reflected in breakthrough improvements in speed and performance. The Flash version of Gemini 2.0 achieves double speed while also surpassing the performance of the 1.5 Pro model, which has a larger parameter scale.
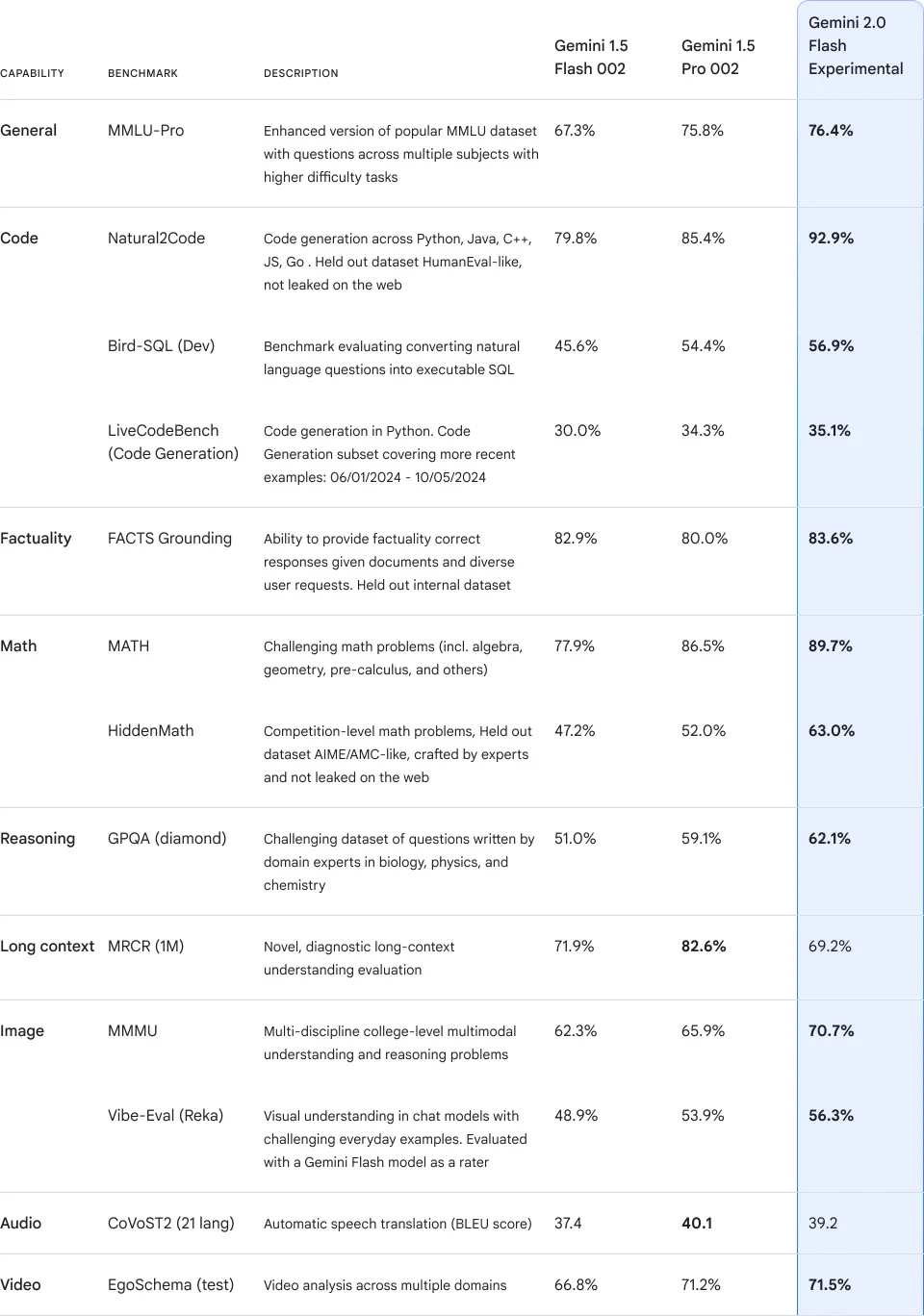
Although no direct comparison data with other mainstream models has been provided. However, the recently trending champion in the arena, Gemini-Exp-1121, is precisely Gemini Flash 2.0.
On this list, we can see that it surpasses ChatGPT-4o and o1 Preview, taking the first spot. This demonstrates the strength of its model.
Moreover, Flash is the smallest model in the Gemini model series, aside from the Nano model developed specifically for edge-side.
As the CTO of Alphabet-C DeepMind, Koray Kavukluoglu, said: "Compared to our position a year ago, the Flash model released today is much more powerful than any model we had a year ago, and the cost is only a small fraction of that."
The minimum has surpassed the maximum and most advanced models of competitors, making it hard to even imagine how strong Gemini 2.0 Ultra will be.
With the improvement in model performance, Gemini is able to better understand complex instructions, engage in long-term planning, and exhibit stronger combinatorial function calling capabilities.
This is the foundation of Gemini's powerful planning ability.
But what is more striking is the model's multimodal capabilities. Gemini 2.0 can not only understand text, images, videos, audio, and code, but can also natively generate images and multilingual audio.
This means it can switch between different forms of information as naturally as humans do.
During Gemini 1.0, Alphabet-C already achieved training for a multimodal large system model, but they had not been able to breakthrough on the generation side. Now they have done it.
This is something that all other leading models cannot do; ChatGPT's image generation still relies on DALLE, while voice generation is also a separate module.
Although when Gemini 1.0 was first released, everyone thought that a unified model would be the future, as of today, GPT-4o may still not be trained in this way.
This is the foundation of Gemini's perception abilities.
Long context understanding has always been Gemini's strength, although the official documentation only mentions "longer context," given that Gemini 1.5 Pro already supports a massive context window of 2 million tokens, Gemini 2 will not be lower than this.
This is the foundation of Gemini's memory abilities.
Additionally, Gemini 2.0 can natively call Google Search, execute code, and use third-party user-defined functions.
This is the foundation of Gemini's tool usage abilities.
Let us review the key foundational abilities of agents analyzed by former OpenAI Vice President Wang Li. Memory, tool usage, and planning abilities have all seen significant enhancements in Gemini 2.0.
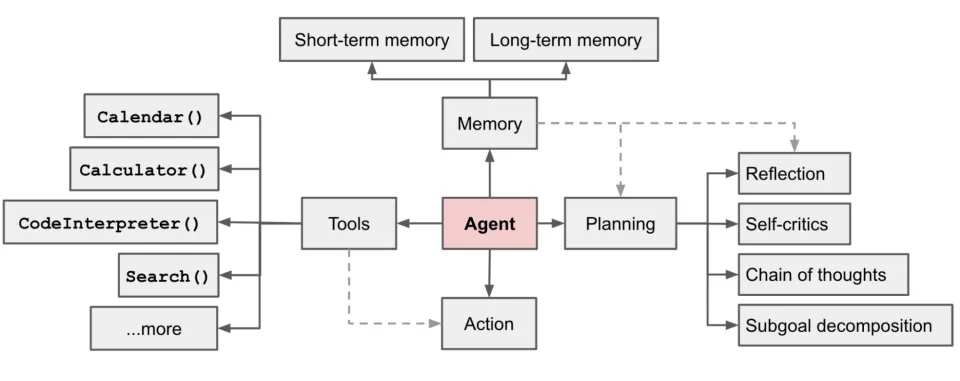
Perception is also one of the core requirements of traditional agents, as it determines the application scope of the agents.
Google product manager Tursi Dohi stated at the press conference: "These new capabilities make it possible to build agents that can think, remember, plan, and even act on your behalf."
Starting today, Global Gemini users can choose to use the 2.0 Flash experimental version on both the desktop and mobile web versions, with the mobile app version set to launch soon.
Google plans to expand Gemini 2.0 to more products in early next year.
For developers, Google has launched a new multimodal real-time API that supports real-time audio and video stream input and the use of multiple combination tools. These features will be available to developers through Google AI Studio and Vertex AI starting this week, with a full version to be released in January next year.
Following the hot excitement of Gemini-Exp-1121, Gemini 2.0 Flash has already received votes from users before its official release.
According to API team product manager Logan Kilpatrick's data, "The increase in Flash usage has exceeded 900%, which is incredible."
In the past few months, we have launched six experimental models, and now millions of developers are using Gemini.
Therefore, the launch of Gemini 2.0, as Pichai said, marks a new stage in the development of Google AI.
But Google has not stopped there.
02 Let AI permeate every vein of Google.
If the technological breakthroughs of Gemini 2.0 are impressive, what will happen when it is integrated into specific application scenarios?
The answer is: Google's AI all-in-one package!
Google demonstrates the potential of this technology through three research prototypes: Project Astra, Project Mariner, and Jules, each showcasing how AI will change our interaction with the digital world.
Project Astra: currently the most stunning system-level AI.
Project Astra is the AI assistant that Google first showcased at the I/O conference in May this year, which didn't seem very impressive when it launched. But now, with the integration of Gemini 2.0, it has gained significant enhancement.
In the demonstration, it can be regarded as Google's version of Apple Intelligence or Windows Copilot, its positioning being a system-level AI assistant.
Astra utilizes the built-in proxy framework of Gemini 2.0 to answer questions and perform tasks through text, voice, images, and videos, calling upon existing Google applications like Search, Maps, and Lens when needed.
Astra product manager Bibo Xu stated, "It integrates some of the most powerful information retrieval systems available today."
This greatly enhances its practicality in daily life.
In terms of memory capabilities, Project Astra has also made significant breakthroughs. The system now has a conversation memory of up to 10 minutes and can remember past conversation histories, even multimodal histories; for example, during a demonstration, it can even remember your door lock code. This enables it to provide more personalized services.
With new streaming capabilities and native audio comprehension, Astra can understand language with a delay speed close to that of human conversation and also supports multiple languages.
According to reports from Wired magazine and Bloomberg, these capabilities were vividly demonstrated in the "home library" scenario at Google's London headquarters. Project Astra can converse fluently with visitors, interpret the anxiety reflected in Norwegian painter Edvard Munch's "The Scream," and discuss how this work captures the general paranoia of that era.
In a room set up like a bar, it can quickly analyze wine bottles in view, providing Geographic Information and flavor characteristics, as well as searching for price information online. When someone quickly flips through books, it can read the content in real-time, even instantly translating Spanish poetry into English.
This is comparable to the level of real-time voice conversation demonstrated by Greg Brockman on the "60 Minutes" program with ChatGPT-Vision, but it seems to have richer functionality.
However, it is also a complete LLMOS system, which can combine what you see on the device and through video to give you answers. In the demonstration video, the guy first showed Astra a list of books his friend liked, and then had it recommend books available in the bookstore via live video.
With the support of tools, Astra can access information about your location at any time and understand the specific situation and policies of that place. Therefore, in the demonstration, when the guy wanted to ride a bike into the park, Astra accurately identified the park and also informed him that riding bicycles is not allowed in that park.
This seamless switching between modalities and the unobstructed integration of tools has not yet been achieved for Copilot or OpenAI. This is all the powerful support brought by Gemini 2.0's native capabilities. There is no doubt that this experience is what we expect to see in our daily applications.
No wonder the MIT Technology Review reports praise Astra as potentially becoming a killer application for generative AI.
Moreover, Google’s ambition does not stop at mobile phones. It has begun expanding its trusted tester program to include a small group of users to test Project Astra on prototype XR glasses. It is exploring the expansion of this technology into more forms, including AR glasses and other wearable devices.
Project Mariner: Google's version of AutoGLM, but more considerate.
Project Mariner is a plugin-based intelligent agent. After all, Google does not have a computer system, and plugins are the biggest PC system entry it can find. As an experimental Chrome extension, it can understand and analyze all information on the browser screen, including pixels, text, code, images, and forms.
When you prompt it to complete a series of tasks, such as finding the email addresses of four companies in the demonstration, Mariner can control a series of autonomous operations in Chrome, including entering information, opening web pages, browsing the internet, and further clicking to query.
Project Mariner can only be inputted, scrolled, or clicked in the active tab, and requires the user's final confirmation before performing sensitive operations such as shopping.
Its overall capabilities are very similar to the "computer use" feature released by Anthropic in October. The AutoGLM recently released by Zhipu in China follows a similar logic.
But the unique aspect of Mariner is that it can synchronize and display each step of the plan like a thought chain, allowing users to stop at any time and modify its erroneous steps. It provides a sense of satisfaction for the user boss.
Moreover, in the WebVoyager benchmark test, Project Mariner achieved an optimal score of 83.5% as a single intelligent agent, showing strong performance.
Although the navigation speed is not fast enough currently, and accuracy still needs improvement, Google states that these issues will improve rapidly over time.
Jules: Google also has Devin now, and it should sell for less than $500/month.
For the developer community, Google has launched the experimental AI agent Jules. Like Devin and Cursor 0.43, it acts as a coding assistant capable of creating detailed multi-step plans to solve problems, efficiently modifying multiple files, and even preparing pull requests to directly submit fixes back to GitHub.
Additionally, what is particularly special is that Jules can work asynchronously and integrate with your GitHub workflow, allowing you to focus on the actual content you want to build while it handles bug fixes and other time-consuming tasks. A true assistant, providing seamless support for you.
This seems not to be achieved yet on Cursor and Devin, not to mention the Canva just released by OpenAI.
In addition to these main applications, Google has made interesting attempts in the gaming field. They are collaborating with leading Game Publishers like Supercell to explore AI agents' applications in various types of games, from strategy games like Clash of Clans to simulation games like Cartoon Farm.
These game AI assistants can not only understand game rules and challenges but also provide suggestions through real-time dialogue, even calling Google searches to connect to the rich gaming knowledge on the internet.
The system-level AI assistant war has begun: Microsoft has drawn a watershed with Vision; Tencent Technology reported on Microsoft's Vision, an intelligent voice assistant they just launched, which can help you with shopping advice. In the promotional video, Microsoft mentioned that perhaps soon, Vision will be able to accompany you in gaming.
Indeed it was fast; it was achieved just a week later. But it was Google that made it happen.
Even more exciting is that Google is exploring the application of Gemini 2.0's spatial reasoning capabilities in the field of robotics. Although still in the early stages, it signals the potential for AI agents to offer assistance in physical environments.
These three products mean that Google has caught up with the industry's leading levels in the mainstream intelligent application direction through a press conference and can even create some new tricks.
03 The unsung heroes behind Gemini 2.0, NVIDIA's contributions.
Supporting these advances are Alphabet-C's significant investments in Hardware. The new generation of TPU chip Trillium not only supports all training and inference processes of Gemini 2.0 but is now also available to customers.
Behind Gemini 2.0 stands the powerful support of Alphabet-C's latest generation of AI Chips. The sixth generation TPU (Tensor Processing Unit) Trillium not only fully supports the training and inference of Gemini 2.0 but also represents a major breakthrough in the field of AI Hardware.
Compared to the previous generation, Trillium has achieved significant improvements in several key Indicators: training performance increased by over 4 times, inference throughput increased by 3 times, peak computing performance per chip increased by 4.7 times, while energy efficiency improved by 67%. More importantly, Alphabet-C has deployed over 0.1 million Trillium chips in a single Jupiter network architecture, creating an unprecedented scale.
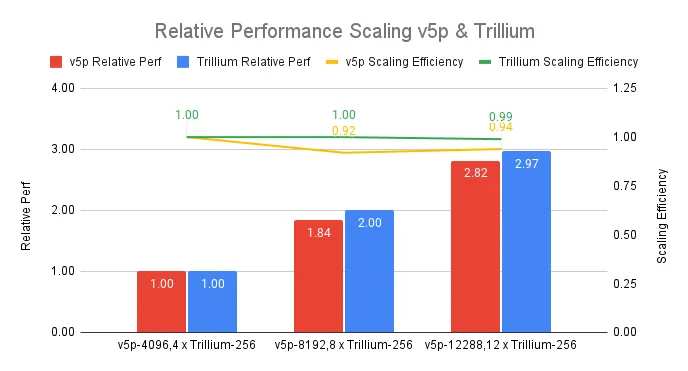
This performance enhancement is directly reflected in the training of large language models. When training dense models like Llama-2-70B, Trillium is 4 times faster than the previous generation TPU v5e. For the increasingly popular Mixture of Experts (MoE) models, the enhancement reaches as high as 3.8 times.
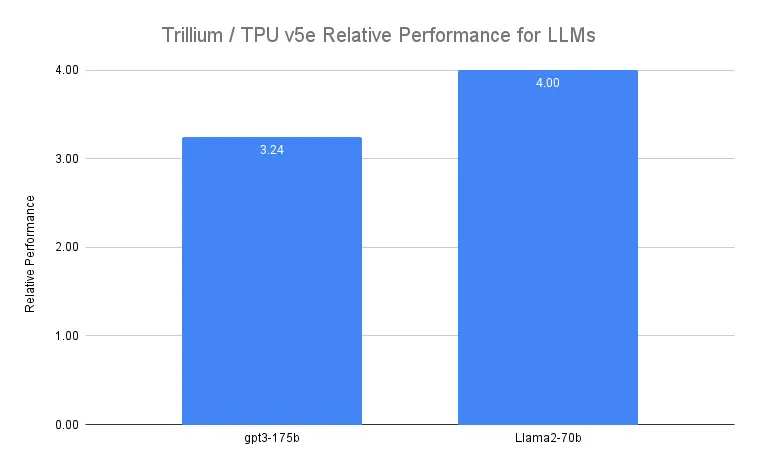
In terms of scalability, Trillium demonstrates astonishing efficiency. When training with 3072 chips (12 computing units), it can achieve 99% scaling efficiency; even when scaled up to 6144 chips (24 computing units), it still maintains 94% efficiency. This nearly linear scaling ability makes the training of large-scale models like Gemini 2.0 possible.
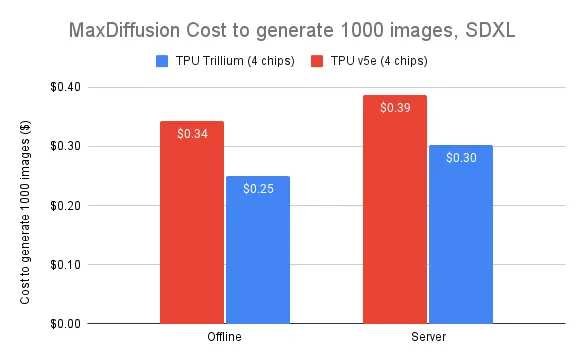
Not only in performance, but Trillium also excels in cost-effectiveness. During the training of large language models, performance per dollar improved by 2.5 times compared to the previous generation. In image generation tasks, the cost of generating 1000 images is 27% lower than TPU v5e (offline inference) and 22% lower (online service).
Behind these advances is Alphabet-C's deep innovation in infrastructure. The AI Hypercomputer architecture integrates optimized Hardware, open-source Software, and leading machine learning frameworks, connecting over 0.1 million Trillium chips with a bidirectional bandwidth of 13Pb/s, allowing a single distributed training task to scale to hundreds of thousands of accelerators.
The not-so-good news for NVIDIA is that Trillium has also been fully opened up to Google Cloud customers.
This means that both enterprises and startups can utilize the powerful, efficient, and sustainable infrastructure used to train Gemini at Alphabet.
Barak Lenz, CTO of AI21 Labs, stated at a press conference: "As a long-time user of TPU since version v4, we are impressed by the capabilities of Google's Cloud Trillium. The progress in scale, speed, and cost efficiency is remarkable."
04 How quickly, well, and economically can Google's updates shift the business landscape.
The commercial significance brought by the release of Gemini 2.0 is most evidently a defense of the inherent business.
As reported by Bloomberg, Google's Alphabet has been working hard to ensure that the latest AI tools launched by startups like OpenAI do not shake its dominance in search and advertising. Although Google still maintains its share of the search market, OpenAI is integrating more search functionalities into ChatGPT, which puts pressure on the industry leader.
Currently, Google's AI overview feature has reached 1 billion users, but the previous generation driven by Gemini 1.0 made the astonishing error of "eating stones daily to supplement calcium," making it difficult for users to trust Google's AI search.
By bringing advanced reasoning capabilities of Gemini 2.0 into search, Google hopes to maintain a competitive edge in more complex topics and multi-step questions.
But this is just the first layer.
A more important layer is the change in ROI. Since this year, investors have been worried about the return on investment for companies like Alphabet-C with significant expenditure in the AI field. Now, with Gemini 2.0 flash achieving more powerful capabilities at a lower cost, it looks much better in terms of ROI. Moreover, if Alphabet-C maintains this advantage, it can outlast its competitors in the price war.
However, the ultimate goal of this AI revolution seems to point towards a grander vision. As the CEO of Alphabet-C DeepMind, Demis Hassabis, stated, he has long dreamed of a universal digital assistant, which he sees as a stepping stone towards general AI. This vision aligns with the objectives of competitors like OpenAI: all are pursuing AGI (Artificial General Intelligence) that can perform tasks, believing that this is where the true value lies.
The CTO of DevMind, Kamukoglu, also emphasized this point: "We want to build this technology - the real value lies in it. On the way to this goal, we are trying to choose the right applications and the right problems to solve."
With this update, Alphabet-C has returned to the agents' table and is even sitting a bit closer than others.
In 2024, Alphabet-C launched two popular applications, the note product NotebookLM and the education AI product Learn About, with a solid foundation for their products. With an even better foundational model now, it may not be long before another blockbuster application emerges.
If 2025 is the year of explosion for Asia Vets and AI applications, then the largest piece of the cake is currently held by Google.
Editor/Somer
