
Source: Wall Street News
Llama 3, the “most powerful open source model ever,” set off the AI community. Musk praised it. Nvidia senior scientist Jim Fan said bluntly that Llama 3 will be a “watershed moment” in the development process of the AI big model. Top AI expert Wu Enda said that Llama 3 was the best gift he received.
On April 18, the AI community welcomed another big news.$Meta Platforms (META.US)$Llama 3 came out with what it claims to be “the most powerful open source big model ever created.”
Meta has now open sourced two Llama 38B and 70B models of different sizes for external developers to use for free. Over the next few months, Meta will launch a series of new models with multi-modality, multi-language dialogue, and longer context windows. Among them, the larger version of Llama 3 will have more than 400 billion parameters and is expected to “compete” with Claude 3.
Meanwhile, Meta CEO Zuckerberg announced that based on the latest Llama 3 model, Meta AI Assistant has now covered all applications such as Instagram, WhatsApp, and Facebook, and has launched a separate website. There is also an image generator that can generate images based on natural language prompts.
The advent of Llama 3, which directly targets OpenAI's GPT-4, is quite different from OpenAI, which is “not open.” At a time when the AI community was constantly debating the open source or closed source route, Meta firmly followed the open source route to launch a charge towards the Holy Grail of AGI, bringing back the game for the open source model.
People familiar with the matter revealed that researchers have yet to fine-tune Llama 3 and have yet to decide whether Llama 3 will be a multi-modal model. According to some sources, the official version of Llama 3 will be officially launched in July of this year.
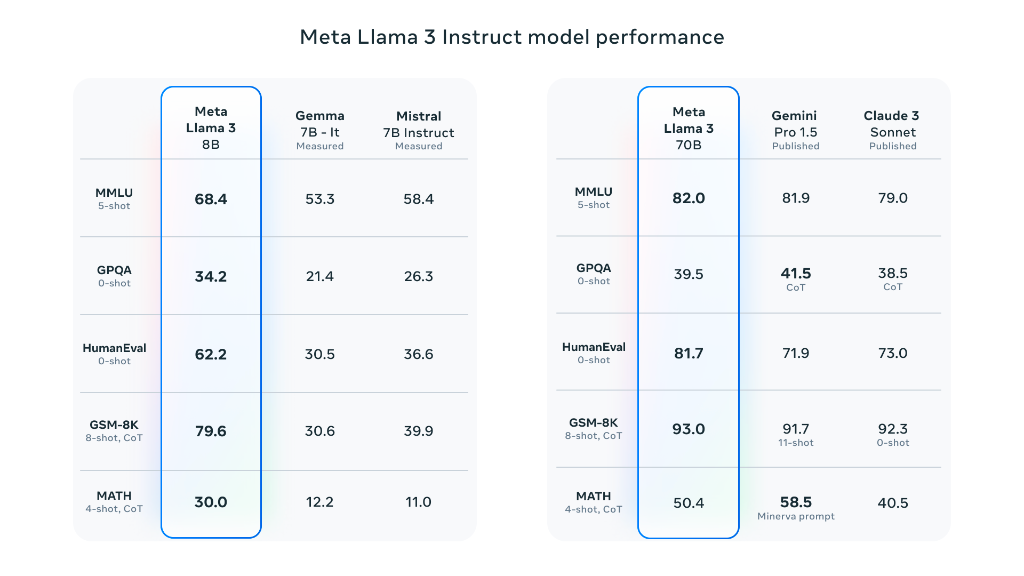
Meta AI chief scientist and Turing Award winner Yann LeCun is “rocking the flag” for the release of Llama 3, while predicting that more versions will be launched in the next few months, saying that Llama 3 8B and Llama 3 70B are currently the best performing open source models at the same size. llama 3 8b performed better than llama 2 70B on some test sets.

Even Musk appeared in this comment section, and the simple phrase “Not bad” expressed his recognition and expectations for Llama 3.

Jim Fan, a senior scientist at Nvidia, believes that the launch of Llama 3 has separated from technological progress, and is also a symbol that the open source model can be divided between the open source model and the top closed source model.
As can be seen from the benchmark tests shared by Jim Fan, the Llama 3 400B's strength is almost comparable to Claude's “Super Cup” and the new GPT-4 Turbo, and will become a “watershed”. It is believed that it will unleash huge research potential and drive the development of the entire ecosystem. The open source community may be able to use GPT-4 models.

The day of the announcement coincided with the birthday of Stanford University professor Wu Enda, a top AI expert. Wu Enda said bluntly that the release of Llama 3 was the best gift she has ever received in her life. Thank you Meta!

Andrej Karpathy, one of the founding members of OpenAI and former AI director of Tesla, also praised Llama 3. As one of the pioneers in the field of big language models, Karpathy believes that LLAMA3's performance is close to GPT-4's:
Llama3 is what appears to be a very powerful model released by Meta. Adhere to basic principles, spend a lot of quality time working with reliable systems and data, and explore the limits of long-term training models. I'm also very excited about the 400B model, which is probably the first GPT-4 level open source model. I think a lot of people would ask for a longer context length.
I would like a model with smaller parameters than 8B and an ideal scale of 0.1B to 1B for educational work, (unit) testing, embedded applications, etc.
Cameron R. Wolfe, AI director at Rebuy and a PhD in deep learning, believes that Llama 3 proved that the key to training excellent big language models is data quality. He gave a detailed analysis of Llama 3's data efforts, including:
1) Pre-training data of 15 trillion tokens: 7 times more than Llama 2, and more than DBRX's 12 trillion;
2) More code data: More code data is included in the pre-training process, improving the model's reasoning ability;
3) More efficient tokenizer: Having a larger glossary (128K tokens) has improved the efficiency and performance of the model.
After Llama 3 was released, Xiaoza told the media, “Our goal is not to compete with the open source model, but to surpass everyone and create the most advanced artificial intelligence.” In the future, the Meta team will release a technical report on Llama 3, revealing more details about the model.
This debate about open source and closed source is far from over. GPT-4.5/5, which is secretly poised, may arrive this summer, and the big model battle in the AI field is still going on.
editor/tolk