
Source: Hard AI Author: Bu Shuqing
Claude 3 Super Cup Opus topped the list. Big Cup Sonnet and Small Cup Haiku achieved fourth and sixth good results respectively, and Haiku's level has reached GPT-4.
As soon as I woke up, the big model world welcomed the “new king to the throne”!
On Wednesday local time, the chatbot arena Chatbot Arena updated the battle rankings. Claude 3 overtook GPT-4 and won the “strongest king” title in one fell swoop.
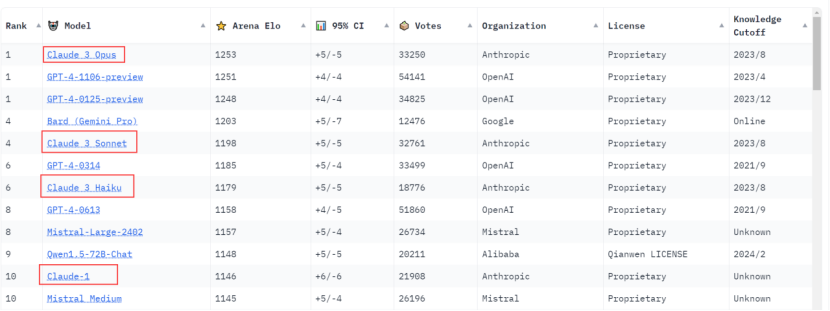
At the top of the list this time was Claude 3 Series' Super Cup Opus, which narrowly outperformed the GPT-4-1106-Preview model with a narrow 2-point Elo advantage, and GPT-4-0125-Preview ranked third.
Moreover, not only the Super Cup Opus, but the other two members of the Claude 3 family, Big Cup Sonnet and Little Cup Haiku, all made it to the top 10, getting fourth and sixth good results respectively.
Little Haiku reaches GPT-4 level
In particular, the small Haiku mug was brought out separately by the official government for praise.
“Haiku has impressed everyone and according to our user preferences, Claude 3 Haiku has reached GPT-4 level!” The LMSYS platform, which runs Chatbot Arena, praised the post, “It's currently unique in the market for its speed, functionality, and length of context.”
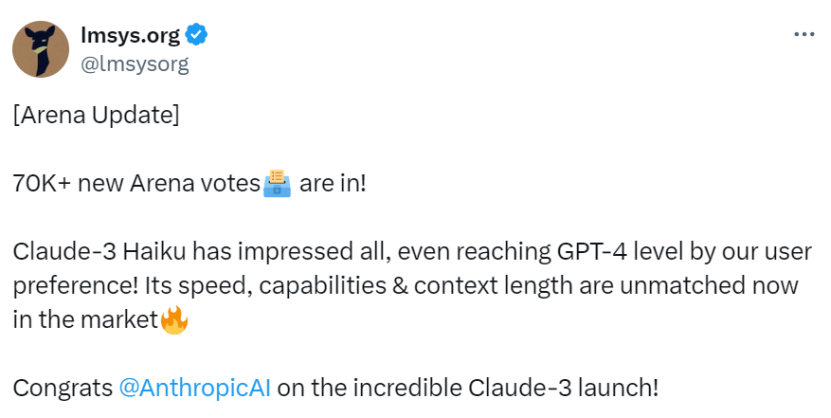
What is even more difficult and valuable is that Haiku's parameter scale is far smaller than Opus and any GPT-4 model, and its price is 1/60 of Opus, but the response speed is 10 times that of it.
GPT-4 has been firmly at the top of the list since it was added to the Chatbot Arena list in May of last year, but now Claude 3 has successfully disrupted this pattern with its outstanding performance, particularly its ability to handle advanced tasks.
“For the first time in history, the first model OPUS for advanced tasks and Haiku for cost efficiency are both from non-OpenAI vendors,” independent AI researcher Simon Willison said in an interview with the media. “It's very reassuring — in this field, the diversity of top vendors benefits everyone.”
“Kneel down to the new king!”
Netizens who eat melons also gave Claude 3 a thumbs up.
“Impressed, very nice!”

Others have suggested that Apple set Claude as the default AI tool.

Some even shouted, “The old king is dead. Rest in peace, GPT-4.”

“Kneel down to the new king!”


In contrast, netizens' feelings about GPT-4 are more complicated.
“GPT-4 is getting really crappy.”

In recent months, topics about GPT-4 becoming lazy have gone viral online.
Allegedly, when GPT is used during peak hours, the response becomes very slow and perfunctory, and even refuses to respond and unilaterally interrupts the conversation.
For example, it habitually skips part of the code during programming work, and there is also a famous scene where humans write their own code.

Is the rating accurate?
Among the voices praising Claude 3, there were also voices of doubt.

So, how did Chatbot Arena rate these big models?
Chatbot Arena was developed by LMSYS, a team led by the University of Berkeley. The platform uses an anonymous and random method for different big models to “play in the ring,” and allows human users to act as judges, and finally ranks them based on the points earned by the big models.
Specifically, the system will randomly select two different big models and chat anonymously with the user each time to let the user decide which big model performs better. The system will rate the big model according to the user's choices, then summarize and organize the scores to form the final points, and finally present them in the form of a ranking list.

Since its launch, more than 400,000 users have become judges of Chatbot Arena. The new round of rankings attracted another 70,000 users.
In this intense “ring competition,” Claude 3 fought back and forth against powerful opponents such as GPT-4 and Gemini through thousands of battles, and became the new king of big models.

It is worth mentioning that when evaluating the quality of a large model, the user's “feeling”, or sense of experience, is very important.
“So-called parameter standards can't really evaluate the value of large models,” AI software developer Anton Bacaj posted earlier. “I just had a long coding session with Claude 3 Opus, which really far surpassed GPT-4.”
The evolution of Claude 3 may make OpenAI a little uneasy. Some users have begun to “mutiny” at work, abandon ChatGPT and use Claude 3 instead.
“I haven't used ChatGPT since I got Claude 3 Opus.”

Software developer Pietro Schirano wrote on the X platform: “Honestly, one of the most shocking things about Claude 3 > GPT-4 is how easy it is to switch.”
However, some people also pointed out that Chatbot Arena did not take into account the performance after adding tools; this is exactly GPT-4's strength.

Also, the score between Claude 3 Opus and GPT-4 is very close, and GPT-4 has been around for a year, so it is expected that at some point this year, more powerful GPT-4.5 or GPT-5 will appear.


Needless to say, the PK between these two major models will be more intense by then.
edit/lambor